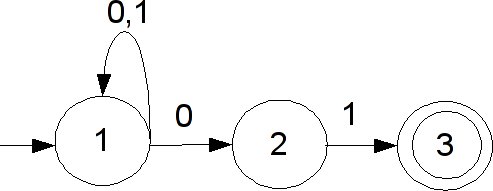
In lecture, Ras described the problem of matching a string against a regular expression (or, equivalently, against an automaton). Matching was defined as testing whether or not the full string matches. However, when we are doing lexing, or breaking a program into individual tokens, we are solving a related but different problem: given a string, we find a prefix that matches a regular expression. These are two separate operations: matching an entire string and searching for a substring that matches.
The difference between these two problems has an interesting effect on the semantics of regular expressions. In Tuesday's lecture, someone asked Ras exactly what the semantics of x* are: how many times does it match x? In the first problem, that of matching an entire string, this question doesn't really matter, since the end result will be the same no matter how many times it matches. For example, if we are matching x*x* against a string, there are many different ways to perform the match, but all have the same end result. But in the second problem, that of finding a prefix, this question becomes important. Consider the regular expression a* and the input string aaaaa. If a* matches greedily (i.e. as many times as it can while retaining a match), it will return aaaaa. In contrast, if it matches minimally, it will return the empty string.
For now, you can use the semantics Ras mentioned in response to the question: that it matches so that the total prefix matched is the longest possible prefix. We will show you on Thursday how to efficiently find that longest prefix and why these semantics make sense. If you're really interested, though, try to figure out why this longest-prefix semantics may produce different results from the greedy matching semantics. Can you come up with an input string where the two semantics match a different substring?
Our goal now is to convert a regular expression (which you can think of as notation or as a source program) into an automaton (which we can execute to match a string). In Tuesday's lecture, Ras began to cover this. He suggested that given a regular expression, we begin by converting it into an abstract syntax tree (AST) that shows the precedence of its operators. The AST is constructed by a parser, which we will explain later in the semester. For now, you can ask yourself whether this parser could be built with regular expressions.
Given this AST, how do you think we might be able to convert it to a NFA? Do we want to work top-down or bottom-up?
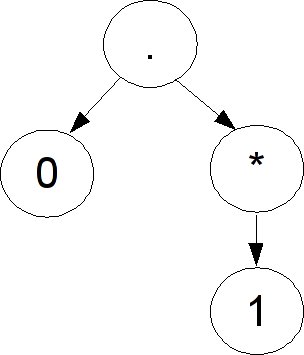
It is most natural to start from the leaves and make our way up the three. For each node of the AST, we will compute an automaton corresponding to the regular expression described by that node. We will start by constructing an automaton at each leaf; as we go up, we combine these automata into bigger automata. A leaf is simply a single character, so we can easily create an automaton that matches exactly a single character. This is the base case of our induction process.
But how can we work our way up the AST from the leaves? To see this, let us consider how we build a regular expression from its simplest forms. When we defined regular expressions recursively, we built up larger ones using three operators: concatenation, alternation, and closure. And these are precisely the way we combine nodes in the AST. So to finish our conversion, we must simply figure out how to build a NFA that recognizes these three, which is the inductive case.
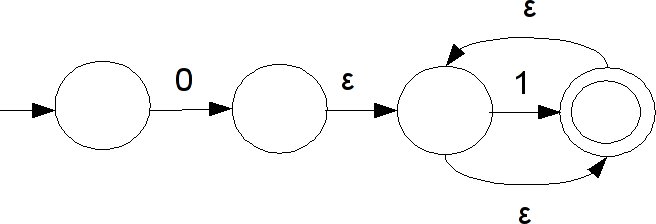
Luckily, we can take advantage of the nondeterminism of NFAs to help us. For concatenation, we link the end state of the first NFA with the start state of the second with an epsilon transition. With alternation, we add a new start state, connect it with epsilon transitions to the two existing start states, and similarly create a new end state with epsilon transitions from the two old end states. For closure, we create new start and end states and link them with the existing ones via epsilon transitions, and we additionally add an epsilon transition between them (for matching zero times) and from the old end state to the old start state (for matching multiple times).
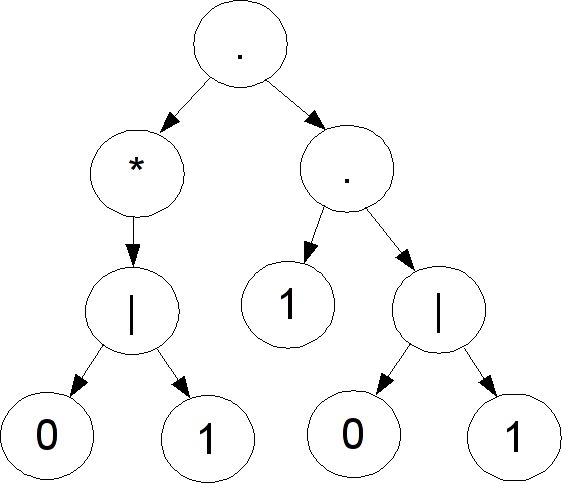
Examples:
You often hear about expressivity of finite automata or regular expressions. Expressivity here refers to the ability of these mechanisms to distinguish strings. For example, can we build a finite automaton that accepts all strings with an even number of characters and rejects all strings with an odd number of characters? Yes. Can we construct an automaton that, in a similar way, tells apart strings that contain matching parentheses from those where the parentheses don't match? No. Automata are not expressive enough for the second problem because it requires unbounded counting, which automata cannot do because they have only finite memory.
With their nondeterminism and the ability to magically "guess" which transition to follow, it is hard to believe that NFAs are not more expressive than DFAs. However, they are not, and we can prove it with a well-known construction.
The key lies in the semantics of NFAs. Given a start state and a symbol, a NFA can transition to multiple states. Thus at any given time during a match, a NFA could be in multiple states. And how do we, as humans, match a string on a NFA? We follow it character by character and at each step compute which states the NFA could be in. Do you see how we might be able to build a DFA that encodes this approach
The insight is that at each step, a NFA could be in multiple states. So when building a DFA, each of its states corresponds to a subset of the states of the NFA. The transition function takes a DFA state representing some set x of NFA states and maps it to the DFA state representing all the NFA states reachable from a state in x. The start state is the state representing the NFA start state and any nodes reachable from it via epsilon transitions. What do you think the final states are?
This is known as the subset construction.
The easiest way to understand it is to work through some examples:
Note that while conceptually pleasing, we should be a bit worried at the thought that states in the DFAs correspond to sets of NFA states. That means that there could be 2^n states in a DFA corresponding to a NFA with n states. But is this worst case actually possible?
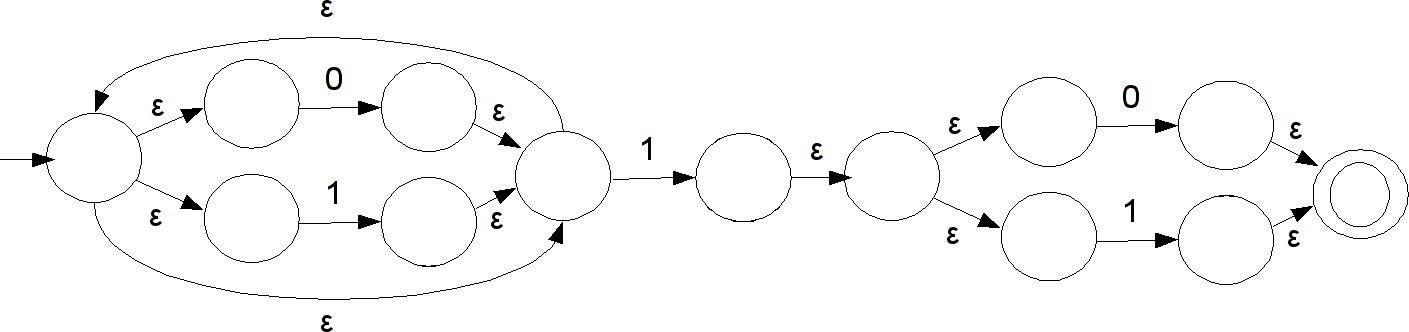
Consider the regular expression (0|1)*1(0|1){n-1}, where x{n-1} is syntactic sugar for n-1 copies of x concatenated together. What would the NFA for this look like? It would use n+1 states and progress linearly down them with the proper transitions. But what about the DFA build form it using the subset construction? It has to remember the last n symbols it has read. If it uses fewer than 2^n states to represent those, then there are two subsets of NFA states between which it cannot differentiate. This means that there are two different sequences of n characters that end in the same DFA state. Since the two are different, then there is at least one location where one is a 0 and the other is a 1, so we can easily build two strings, only one of which the NFA would accept, but which the DFA would treat the same. Thus the worst case exponential behavior for this construction is in fact possible.

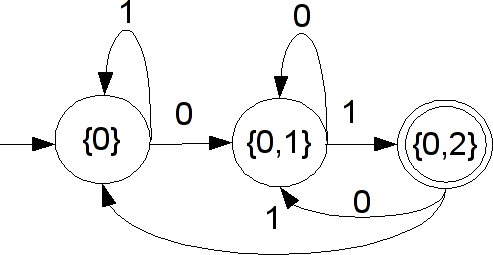
Consider the NFA for this regular expression, shown above. Let's start making the transition table for its DFA via the subset construction.
| Start state | Symbol | End state |
| {0} | 0 | {0} |
| {0} | 1 | {0,1} |
| {0,1} | 0 | {0,2} |
| {0,1} | 1 | {0,1,2} |
| {0,2} | 0 | {0,3} |
| {0,2} | 1 | {0,1,3} |
| {0,1,2} | 0 | {0,2,3} |
| {0,1,2} | 1 | {0,1,2,3} |
| ... | ... | ... |