Ambiguous Grammars
We have seen in lecture the problem of ambiguous grammars. Consider the following grammar, where E is expressions in the language.
E ::= if E then E | if E then E else E | ...
This is obviously a common feature in programming languages. And it turns out that it is ambiguous. For example, consider the following string.
if e1 then if e2 then e3 else e4
There are two different parse trees for this string:
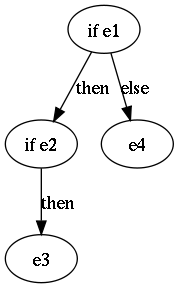 and
and 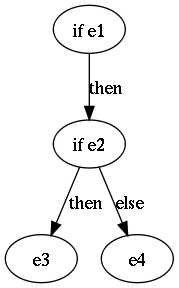
Programming languages prefer the second parse where the else belongs to the closest-enclosing if. But how do we disambiguate?
- If we're using a parser generator like the ones Ras showed in lecture, we can use %dprec directives. We'll see an example of this later.
- We can also rewrite the grammar. One simple way is to require { and } braces or to explicitly use an end statement (as many older languages do). We could also rewrite the grammar without this new requirement as follows.
| E | ::= | MatchedIf | UnmatchedIf | ... |
| MatchedIf | ::= | if E then MatchedIf else MatchedIf | ... |
| UnmatchedIf | ::= | if E then E | if E then MatchedIf else UnmatchedIf |
This rewritten grammar does not allow the first parse tree above.
Writing a Parser
We will now try to get some experience with using a parser generator to generate a parser and show how powerful this technique is.
Because we apparently haven't seen enough of them yet in this course, we'll use regular expressions. We can first build a parser that simply prints out the regex. You can see this grammar here. We can now change the code to instead generate an AST for the regex (see here). This is pretty cool: in about five easy-to-read lines we implemented what took us about a full section and over fifty lines of code last week. This shows how useful such parser generators can be.
Now let's move on to something even cooler. The Graphviz program takes a text file as input and draws a graph representing it. For example, Graphviz can take this input and output a graph showing (a bit of) the secret of life.
Given Graphviz and our parser generator, we can do some cool stuff. Previously, we generated the AST of a regular expression. That is useful, of course, but it's hard to read and comprehend manually. What if we want to generate a visual graph of the AST? With a parser generator, it's easy.
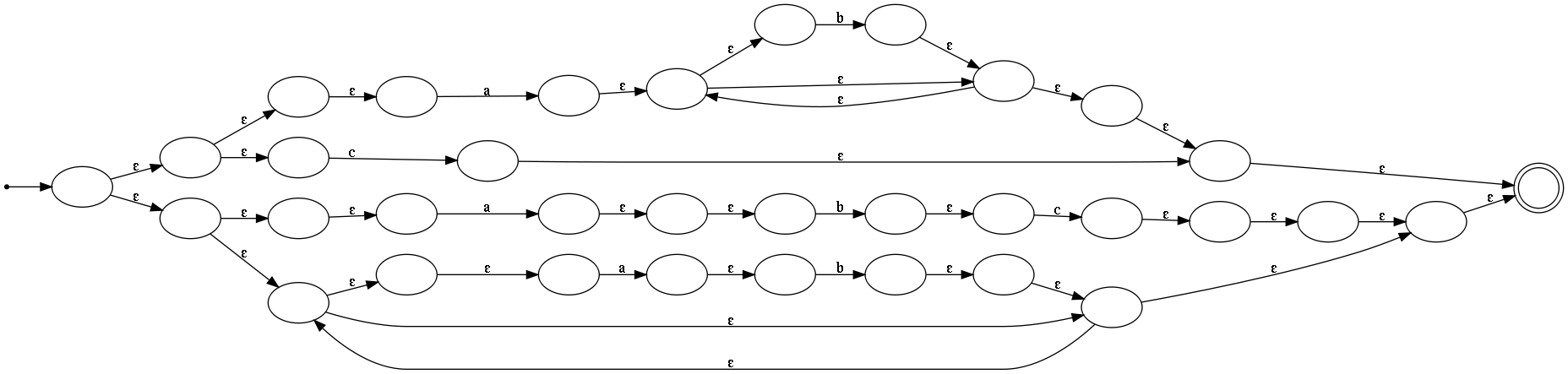
A few weeks ago, we saw that there was a mechanical transformation for converting regular expressions into NFAs. Could we apply that and automatically build a NFA for a regular expression? Yes. Here's an example of the output. Pretty cool, isn't it? Also, imagine that we were using a NFA library rather than a graph visualization tool. Given a good API, it wouldn't be hard to modify this to build a data structure for the NFA, right? And with that, we could actually match the regular expression.
If you want to run these examples, you'll need a wrapper script. Here is one for the first two grammars, one for the third example, and one for the final example. You'll also need a parser generator, of course, but that will come later.
{kind=link}
{kind=link}