Projects for Fall 2014, CS 250
This web page describes project topics for the class. Each project describes a class of special-purpose instructions that are a good fit for the RISC-V (pronounced: "risk five") accelerator.
Here is a Table of Contents for this web page:
- Interface Description
- Sparse Dot Products
- Linear Equation Solver (Determinants)
- Flexible String Comparisons
- Audio Pulse Density Modulation
- Image Compression
- Convolution Engine
- Vision
- Matrix Transposition
- Fixed-Point Implementations
- Sorting
- Memcached
- Viterbi Algorithm, Cryptographic Hashing
- Support Vector Machines, Error Correcting Codes
The project topics on this web page are offered as a starting point, not a specification. Project teams are free to revise an instruction as they see fit to make an interesting project. Furthermore, teams may propose an alternative project topic, as long as the project is a good match for the RISC-V interface.
A goal of the class is to learn how to design an integrated circuit to meet a specific energy-performance-area target. And so, teams will design several accelerators for their topic, each optimized for a different set of tradeoffs.
For example, one accelerator may be targeted for lowest energy, while another may be optimized for smallest area. In each case, the designs should optimize the other secondary variables as much as possible, given the primary constraint. In order to fairly compare your designs, all accelerators should produce identical results for your testing algorithms, in a bit-accurate sense.
The options at your disposal for optimization include:
- Technology-independent techniques, such as clock-gating and data-dependent processing.
- The Vdd value for a design (libraries are characterized at multiple Vdd values).
- The mix of library cells in a design (library cells are offered in low-power and high-speed versions).
You will be able to implement simple versions of the "trading hardware for power" and "slowing down slack paths" techniques described in the power and energy lecture. Techniques that rely on multiple power islands, or on dynamically varying Vdd, will not be possible.
We will provide comprehensive documentation of the RISC-V accelerator interface in a later document. Here, we provide a brief description, so that we can introduce the project topics using a common notation.
The Accelerator Interface
The RISC-V CPU is a scalar processor with 32-bit instructions. The processor has a 64-bit address space, and its 32-entry register file holds 64-bit values.
Accelerator instructions act, in many ways, like normal RISC-V instructions. Your instructions are 32 bits in length, and may appear in the scalar instruction stream of a user-land program. All 32 bits of an accelerator's instructions are forwarded to the accelerator. The accelerator instruction format appears below.
|
|

Your accelerator should ignore the opcode field; it acts like the "to" address of a postal envelope, and is used by the CPU to route your accelerator instructions (and only your accelerator instructions) to you.
If the xd, xs1, and xs2 bits are set, the accelerator instructions have the register semantics of normal RISC-V ALU instructions. The 64-bit values of the registers coded by the rs1 and rs2 fields are delivered to the accelerator along with the instruction. Upon instruction completion, the accelerator returns a 64-bit value to the RISC-V core, which writes it to the register coded by rd.
The funct7 field encodes an opcode space for the accelerator's own use. Thus, an accelerator may define 128 instruction types.
The system diagram of a RISC-V core with an attached accelerator appears below.
|
|
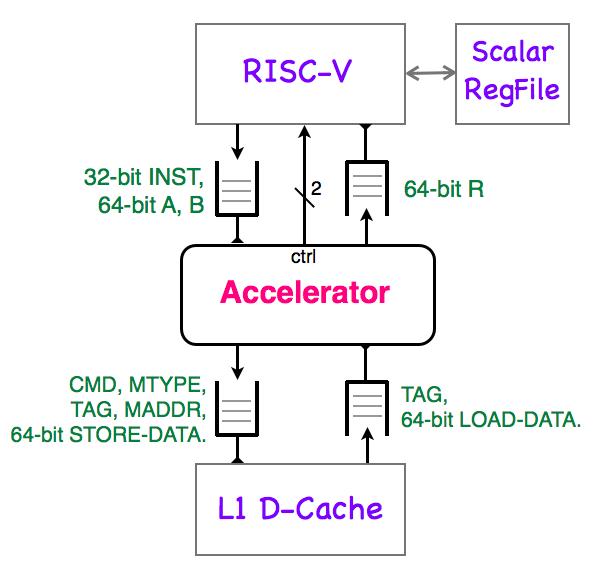
Your accelerator communicates with the RISC-V core via a set of queues, each of which is specialized for a single purpose.
The issue queue lets RISC-V issue instructions to the accelerator. The issue queue holds the 32-bit instruction INST and the contents of the two operand registers (64-bit values A and B).
The accelerator signals the completion of an instruction to the RISC-V core by placing the 64-bit value R in the result queue. The RISC-V will store the result value in the register specified by the rd field of the retired instruction. The R value has no tag field -- accelerator instructions must complete in the order they issue.
An accelerator has direct access to the memory system, and can issue loads and stores to the L1 data cache. There is one pair of queues between the accelerator and the memory system. The CMD field identifies a memory operation as load or store.
Memory requests can be 1, 2, 4, or 8 bytes long, as indicated by the MTYPE field. The memory address, coded by the MADDR field, must be aligned to the boundary implied by MTYPE.
The accelerator tags each memory request, using the 9-bit TAG field. Tags allow the memory system to service loads out of order (load data is returned with a tag). The memory system also returns tagged write acknowledgements to the accelerator.
The 64 KB L1 data cache has lines that are 64-bytes long. If an accelerator load hits the cache, the minimum return latency is 4 cycles. A miss may take 50-60 cycles to return. The L1 data cache can service memory requests after a load miss, up to a maximum of 4 misses.
The accelerator sends two control wires to the RISC-V core. The busy signal is used to manage memory coherency, while the interrupt bit signals an illegal instruction. The semantics of these wires is somewhat complex, and will be addressed by Ben in a discussion section.
If an accelerator does not wish to fully use the RISC-V register file, any or all of the xd, xs1, and xs2 bits in the accelerator instruction (collectively, the x bits) may be cleared. In this case, the RISC-V core does not perform the semantics associated with the cleared bits, and the accelerator may re-purpose up to 15 bits of its instruction space for its own use (rd, rs1, and rs2 fields).
The x bit semantics are particularly useful for accelerators that include a private 32-element register file (let's call it an A-file). In this case, each of the 128 instruction types could have several types of semantics. If all x bits are set, the instruction would act on the RISC-V register file, as described above. If all x bits are clear, the instruction acts on A-file registers. Combinations of set and clear x bits could correspond to data transfers between the RISC-V register file and the A-file.
An illustration of an accelerator with an A-file is shown below.
|
|
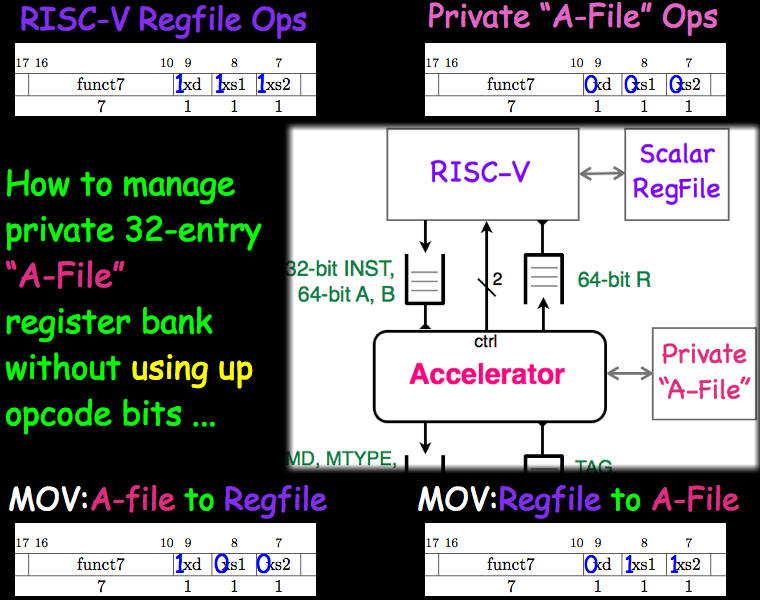
An accelerator is free to define its instruction semantics to have side effects with respect to main memory. If the accelerator uses writes to main memory to communicate with the program running on the RISC-V core, this program should use memory fences to ensure consistency. The accelerator signals information about memory consistency to the RISC-V core using one of the control wires (the "busy bit").
In an industrial design, an accelerator would need to handle a host of secondary issues (internal state management on context switches, page table faults for memory operations, etc). To make the project tractable, we will provide an accelerator interface that lets you ignore these issues, so that you can focus on the core operation of your instructions.
Accelerator Project List
Below, we present our project ideas, as a numbered list. Most project descriptions include links to papers for background reading. In some cases, the paper links will only work when accessed from a UC Berkeley campus IP address, because of publisher copyright restrictions.
Sparse Dot Products
The arithmetic dot product of length-n vectors a and b is defined by the equation:
|
|
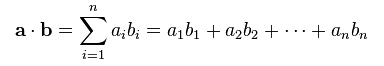
In this project, we wish to accelerate dot products of high-dimensional vectors (n from thousands to billions), where most vector elements have the value 0 (known as "sparse" vectors). Sparse dot products are used in many application areas, including web advertising click prediction and chemical similarity analysis.
We first consider a special class of sparse vectors, called binary sparse vectors, whose vector elements may only take on the values 0 or 1. In a click-prediction application, the vector may have dimensions of 4 billion, with a typical vector having 4,000 non-zero elements (thus, 99.999975% of elements are zero).
Sparse binary vectors have a natural representation: a list of the indices of all 1-valued vector elements. In our accelerator, we restrict the list representation in several ways. Indices are coded as 32-bit unsigned integers, and span the range [1, 4294967295]. Index 0 is reserved to act as a list termination symbol. Lists must be stored in sorted form. No index may appear twice in the list.
The lists:
a: 1, 13, 1827, 2000, 1938475, 0
b: 12, 13, 2000, 1602938, 0
are examples of vector encodings. Vector a uses 24 bytes of storage; vector b uses 20 bytes. The dot product of a and b is 2, because two indices (13 and 2000) appear in both lists.
We are now ready to define our accelerator instruction:
SBDT dest_reg, a_reg, b_reg
The a_reg and b_reg fields identify the RISC-V scalar registers that hold 64-bit memory addresses of sparse binary vector lists a and b. The addresses stored in a and b must be aligned to 32-bit boundaries. Vector list lengths are restricted to 65536 elements (including the terminating 0 element).
The dest_reg field identify the register for the return value. The return value has several computed quantities packed into the 64-bit payload. The lower 32 bits hold the dot product, as an unsigned integer. The upper 32 bits are divided into two 16-bit unsigned integers, which hold the number of 1-valued elements (the "vector density") of a (upper 16-bits) and b (lower 16-bits).
Below, we show a simple implementation of the accelerator.
|
|
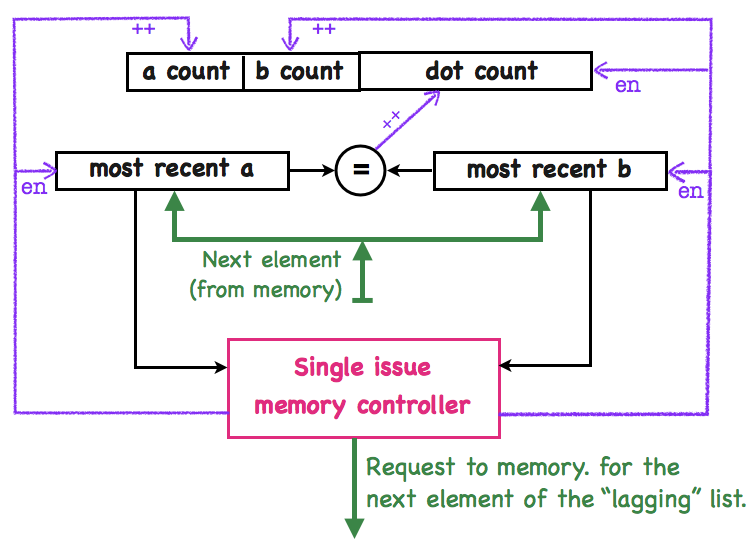
The counters at the top of the diagram accumulate the result values for the instruction, and are initialized to zero at the start of each SBDT instruction. The accelerator computes the result by incrementing the counters as it scans through the two lists.
The accelerator has a simple memory controller, with only one memory request in flight at a time. During the execution of the instruction, the controller loads elements of each list in sequence, starting from the first element. After both lists are fully scanned, the controller completes instruction processing by queuing the counter register values to the RISC-V core.
The controller decides which list element to fetch based on the values stored in the most recent a (element) and most recent b (element) registers, shown in the center of the diagram. The controller fetches the next element of the "lagging" list, and clocks its value into the appropriate register. It also updates the count register for the list.
On the following clock cycle, the "=" comparator tests for an index match, and updates the dot-product counter as needed. The comparator is not a simple bit-wise comparator: matches to the zero index are ignored. The controller qualifies the counting action, via an enable line.
In this implementation, the average number of comparisons per cycle are low. Ways to improve performance include:
- Improve the memory controller to sustain one 64-bit memory access per cycle, while avoiding cache misses by using prefetching.
- Take advantage of the sorted nature of lists, to speculatively skip loading of list elements. Ideally, the controller would only load elements that contribute to the dot product. This tactic is only practical if the list lengths are known by the accelerator in advance.
- Change the list data structure to store a compressed representation of list indices, so that a 64-bit memory access would (on average) hold more than two indices.
A simple example of a compressed list representation is delta encoding. For example, the vector:
a: 200, 300, 301, 400, 402, 0
could be recoded as:
a: 200, 100, 1, 99, 2, 0
when each "delta element" is a number to add to the previous index to compute the next one (the first element in a list is added to 0). The elements could be stored using the compressed format that the MIDI standard uses, as shown below:
One-Octet Delta Time:
Encoded form: 0ddddddd
Decoded form: 00000000 00000000 00000000 0ddddddd
Two-Octet Delta Time:
Encoded form: 1ccccccc 0ddddddd
Decoded form: 00000000 00000000 00cccccc cddddddd
Three-Octet Delta Time:
Encoded form: 1bbbbbbb 1ccccccc 0ddddddd
Decoded form: 00000000 000bbbbb bbcccccc cddddddd
Four-Octet Delta Time:
Encoded form: 1aaaaaaa 1bbbbbbb 1ccccccc 0ddddddd
Decoded form: 0000aaaa aaabbbbb bbcccccc cddddddd
For the example a vector above, this lossless compression technique results in a 3.4x gain in memory bandwidth.
Many variations on this project concept are possible. For example, you may choose to let the a vector be sparse but not binary (the click prediction paper uses a 16-bit fixed-point vector representation for a).
As a second example, you may choose to remove requirement for the lists to be sorted, which would change your acceleration strategies in fundamental ways.
As a third example, you could make the binary vector representation be a long binary bitstream stored in memory, whose "1" density is extremely low. Your accelerator design would define a compression format for these bistreams that took advantage of the density using a different approach than the "list of indices" method.
Linear Equation Solver (Determinants)
This project is an accelerator for solving systems of linear equations using determinants. The accelerator defines two instructions, and contains programmer-visible state.
We begin with a brief review of determinants. A determinant is a reduction of a square matrix to a scalar value. The determinant of a 2-by-2 matrix is defined as:
|
|
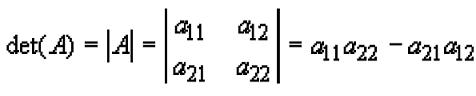
and the determinants of larger matrices may be calculated by the recurrence relation:
|
|

We can use determinants to solve a system of linear equations:
|
|
where A (an N-by-N matrix) and b (a length-N column vector) are the equation coefficients, and x is the length-N column vector holding the solution
The solution to this matrix equation is given by Cramer's rule:
|
|
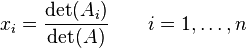
where Ai is the matrix formed by replacing the i'th column of A by the column vector b.
If we use a fast algorithm for computing the determinant, the time complexity of solving equations via Cramer's rule is O(N^3), competitive with Gaussian elimination (see this paper for details).
---------
We now define two accelerator instructions, DETA and DETAI, which work together to implement Cramer's rule.
DETA dest_reg, a_reg, len_reg
The DETA instruction is called at the start of the Cramer's rule algorithm. The a_reg field identifies the RISC-V register that holds the 64-bit memory address that points to the start of the A matrix. The len_reg field identifies the RISC-V register that holds the dimension of A.
The instruction returns the determinant of A as a 64-bit value, that will be written in the RISC-V register coded by the dest_reg field. In addition, the accelerator maintains sufficient state information about A to execute subsequent DETAI instructions. The accelerator maintains this information until it is asked to execute another DETA instruction instance. The amount of saved state is a function of the dimension of A, and so a practical accelerator will only be able to solve equation systems up to a certain size.
DETAI dest_reg, b_reg, col_reg
The DETAI instruction computes the determinant of the Ai matrix formed by replacing the i'th column of A by the column vector b. The b_reg field identifies the RISC-V register that holds the 64-bit memory address that is the start of the b column vector. The col_reg field identifies the RISC-V register that holds the i subscript of Ai, as a 64-bit unsigned integer.
The instruction returns the determinant of Ai as a 64-bit value, that will be written in the RISC-V registed coded by the dest_reg field. The computation uses local state information in the accelerator that was stored by the most recently executed DETA instruction, and by DETAI commands that followed that DETA. Each DETAI instruction saves local state information to speed up solving other Ai determinants.
---------
An algorithm to solve a set of N equations starts by calling DETA once, followed by N calls to DETAI. To complete the algorithm, N scalar divisions are performed on the RISC-V core, to compute each xi = det(Ai)/det(A).
This project is "reasonable" to complete in a semester if the A matrix and b column vector are restricted to be small signed integers (perhaps as small as 8 bits). This restriction ensures that the determinant will also be an exact signed integer, as the determinant computation uses only multiplication, addition, and subtraction.
This property makes it possible for your designs to hit different points in the energy-area-performance space by changing the size of the multiplier array. You may wish to look into bit-serial multipliers, as described in this classic paper.
The description above leaves many details of the project unspecified. To do this project, you will need to study this paper to fully understand the algorithm.
Flexible String Comparisons
This project topic is flexible acceleration for character string processing.
It builds on the string acceleration instructions in recent versions of the Intel ISA (see linked documentation excerpts for an introduction, four opcode descriptions, and code examples).
Below, we show a block diagram of the Intel string accelerator, with annotations that resize its datapath to match RISC-V.
|
|
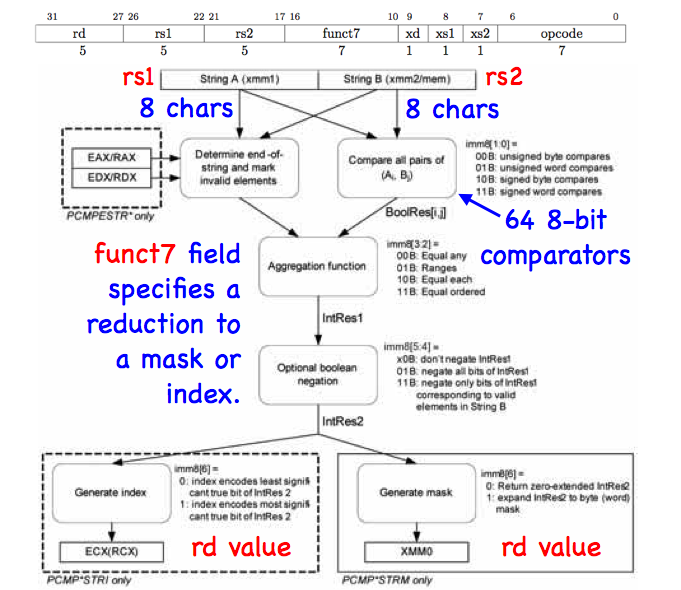
In the mode annotated above, 64-bit operands A and B are organized as lists of 8 8-bit characters. An array of 64 ALUs compares each character in A with each character in B, producing a 128-element bit vector as an intermediate result. The 2-bit output of each ALU codes the "less than". "equals to", "greater than", and "at least one null" conditions.
To complete the computation, the accelerator reduces the vector to an 8-bit mask or a 3-bit index value. Reduction modes are hand-crafted for common programming tasks (for example, C string library functions strcmp() and strstr() have dedicated modes). The comparator array also has several modes of operation, customized for common lexical tasks.
Altogether, the accelerator offers 9-bits of configurable options (4 instruction opcodes, each with a 7-bit configuration field coded in funct7).
One good class project for the class would be to reimplement the Intel architecture, or if this turns out to be too challenging, an appropriate subset.
Another approach would be to take the Intel architecture as a starting point, and then replace the comparison array and reduction logic with regular, configurable blocks that are borrowed from Field-Programmable Gate Arrays (FPGAs). This idea is reminiscent in some ways of the GARP architecture, described in this paper.
Below, we sketch a block diagram of the project idea.
|
|
The motivation of this architecture is to support string comparisons with irregular equivalence classes (for example, case-insensitive comparison).
A look-up table (LUT) is a natural way to support this functionality. To save chip area, the 64 LUTs in the array share one block of LUT SRAM. Accelerator instructions directly access the memory system to update the LUT SRAM.
On a final note, some types of bioinformatics problems can be seen as a specialized type of string processing. The acceleration ideas described above can be used as a starting point for a DNA comparison engine. A good example of such an accelerator can be found in the paper available here.
Audio Pulse Density Modulation
This project is a good fit for someone with an interest and a background in audio digital signal processing (DSP). If you haven't taken a DSP class, and try to do this project, you will spend most of the semester teaching yourself DSP instead of doing acceleration design. So don't do that!
To begin, the image below shows two representations of an audio signal. The left representation is the more familiar one: a waveform of 16-bit samples at a 44,100 Hz sample rate, like a standard compact disc (CD). We call this representation Pulse-Coded Modulation (PCM).
|
|
The waveform on the right is a different representation of the same signal: a 2.4 MHz one-bit waveform (-1 or +1). The amplitude of a particular sinewave sample of the left is equivalent to the local density of +1 samples on the right. Thus, we call the representation Pulse Density Modulation (PDM).
PDM is an interesting format because it is the first digital representation in a Sigma-Delta A/D converter, which is the most popular audio converter topology. In a traditional Sigma-Delta A/D chip, much of the die is taken up by digital circuits that post-process PDM into PCM.
It is becoming popular to make products with arrays of microphones (many smart phones have two or more microphones). Another trend is to use MEMS microphones, that combine the microphone and the A/D in the same package. Given these trends, it improves system performance to design MEMS microphones with A/D converters that send PDM off the chip, and post-process the PDM to PCM elsewhere. An example part that works this way is the Analog Devices MEMS microphone ADMP521 (pictured below, with data sheet available here.
|
|
With this background, we can now describe PDM-related project ideas. One idea is to create an accelerator with a single instruction that converts stereo PDM to stereo PCM. The A register would point to the region of memory that contains PDM samples, and the B register would point to the region of memory that the accelerator should deposit the PCM samples. The funct7 field would encode the length of the sample blocks, etc.
A good introduction to the algorithms behind PDM to PCM conversion is an Analog Devices application note, available here. The figure below shows the basic algorithm in the application note. There are other documents you should read to get a more theoretical description of PDM to PCM conversion; a good starting point is the Professor Boser's lecture slides on the topic, available here.
|
|
A related project idea is to implement an accelerator instruction that does audio signal processing using the PDM representation. A practical example is an accelerator that takes as input interleaved PDM bitstreams from an array of microphones, and performs beam-forming to "focus" on sounds in a particular point in space.
Two website references serve as a good start for such a project. The first website provides a self-contained introduction to audio beamforming, and is available here. The second set of links is a five-part series on doing signal processing in the PDM domain, available here (one, two, three, four, five). Unfortunately, time has not been a friend to the latter website, and the formatting breaks in some browsers; try using the "print" link on that webpage for a more readable version.
Image Compression
A black-and-white image, that consists mostly of white pixels, can be considered to be a sparse binary matrix. An algorithm that compacts that matrix into an efficient representation is, in effect, a lossless image compression algorithm.
This observation was the starting point for an interesting set of image compression algorithms, described in a paper available here (note that you will need to be on the campus Internet to access this paper for free). An interesting accelerator project would be to implement instructions for the compression and decompression algorithms from this paper.
A related acceleration project would be to use the quadtree sparse matrix representation they describe in their paper as a starting point for a sparse vector-matrix multiply engine.
Convolution Engine
The convolution operator is a computationally intensive part of many image processing and computer vision algorithms.
Recently, a group at Stanford published a paper on an acceleration architecture for convolution, that is a good fit for our class project.
Below is a diagram from their paper, that shows a key part of their architecture.
|
|
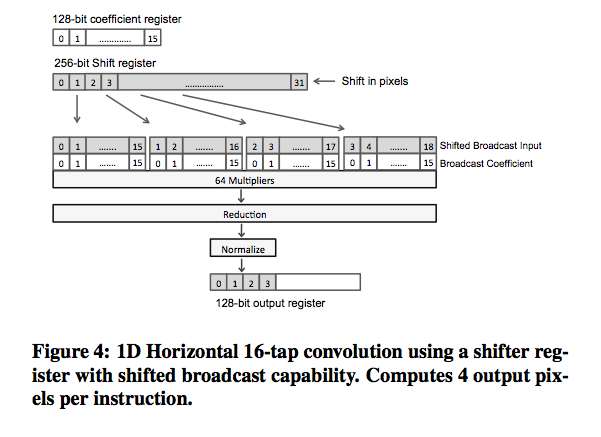
The paper is available for download here, and the slide deck from their ISCA talk is available here.
Vision
Visual motion processing is a natural target for hardware acceleration, because it is a key bottleneck in video compression algorithms. Intel processors have extensive support for these algorithms, both in the CPU and the on-chip GPU. A good starting point is this recent JSSC paper from an Intel chip design group, available here.
Another popular topic for vision acceleration is finding abstract "corners" in real-world images. Such corner detectors are a key bottleneck in many object recognition algorithms. Recent JSSC papers on such accelerators are available here and here, which are based on an algorithm described here.
A final vision accelerator idea is "image hashing", whose accelerator is described in a JSSC paper available here.
Matrix Transposition
In numerical analysis programs, it is sometimes necessary to transpose matrices before performing operations on them. One approach to accelerating transposition is to design SIMD register files that can be written and read in both a per-row and a per-column. A recent Intel paper implements this approach to matrix manipulation, and is available here.
On a related note, partitioning vector-matrix operations into smaller blocks is another type of matrix manipulation that may be amenable to acceleration. A good introduction to this sort of partitioning is available here.
Fixed-Point Implementations
In some application domains, floating point numeric representations are always used in a restricted range (for example, -1.0 to +1.0), and the resolution and accuracy requirements within that range are relaxed.
For these applications, it makes sense to consider accelerators that compute on floating-point numbers using fixed-point math.
A well-implemented example of accelerators of this type is an Intel graphics pipeline paper, available here.
Sorting
Accelerators for sorting large databases have a long history in computer architecture. The memory interface of the RISC-V accelerator makes it a good fit for implementing some of these classic algorithms. Two good starting points are papers available here and here.
Memcached
Memcached is a popular image caching system used in large websites, like Facebook. It is typically run on standard server CPUs.
However, there has been recent interest in building special-purpose hardware for memcached, as described in papers available here and here.
It would be interesting to repurpose the architectures developed in these papers in the RISC-V accelerator format. Alternatively, it may be interesting to accelerate a key building block in cache systems of this type, the Bloom filter, apart from memcached itself. A good starting reference for Bloom filters is available here.
Viterbi Algorithm, Cryptographic Hashing
Krste thought that a Viterbi algorithm accelerator would make a good project. A good example of such an accelerator is available here.
Krste also suggested that a cryptographic hash function would be a tractable cryptography accelerator for the class. Good examples of such an accelerator are available here and here.
Support Vector Machines, Error Correcting Codes
John Platt and David MacKay are Caltech alumni who were at the school when I was in the 1980s. Each has implemented an algorithm whose inner loops would be a good fit for an accelerator project.
John Platt's algorithm concerns fast implementation of Support Vector Machine learning, and is available here.
David MacKay's algorithm concerns error-correcting codes, and is available here.
Both algorithms will require floating-point operations, and are a good match for someone interesting in exploring Chisel's support for floating point.
A related idea is to do accelerator instructions for encoding and decoding QR codes ("2-D barcodes"), which are based on error correcting codes. A tutorial introduction is available here.