The source language is composed of four types of lexical units: identifiers, keywords, literals, and special symbols.
An identifier is a sequence of letters, digits, and the special character `_' (underscore). Identifiers must begin with a letter. Two or more `_'s may not appear together. Identifiers are case sensitive (e.g., i and I are different identifiers), and must be distinct from the keywords of the language. They will be represented in grammar rules by the generic token IDENT. Identifiers may be of arbitrary length, so the implementation should not impose length limits.
There is a list of keywords in  cs264/assignments/assn1/keywords.
cs264/assignments/assn1/keywords.
A keyword is a sequence of letters. Your scanner should be designed so that modifying the keyword list is easy. A keyword can be all upper or all lower case, but not mixed. Thus, begin and BEGIN are the same keyword, but Begin is just an identifier.
Literals are the primitive values manipulated by the language. There
are five built-in primitive types: integer, float, character, text,
and boolean, represented, respectively, by the generic tokens INTLIT,
FLOATLIT, CHARLIT, TEXTLIT, and BOOLLIT. Integer literals are
sequences of digits. Float literals are of the form n.m, n.mEk, or n.mE+k, where n, m, and k are
integer constants (i.e., sequences of digits). Note that .m,
n., nEk, and nE+k are not legal float literals. The
letter E can also be the lower case e; the + sign
can also be a -. Character literals are single characters in
single quotes: 'a', '%', etc. Strings are sequences of characters in
double quotes: "abcdefg", "12&^#%$", etc. In character and
text literals, the backslash character is used as an escape (as in C):
'\'' is a single quote character, '\"' is a double
quote, and '\\ ' is a single backslash. Finally, a boolean
literal is one of the reserved words TRUE, true, FALSE, or false.
Special symbols comprise the operators and delimiters of the language. For the purpose of this assignment, your scanner should recognize these symbols:
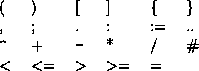
The lexical units of the source program may be separated by the formatting characters (blank, tab, end-of-line, form-feed) and by comments. At least one formatting character is needed between two lexical units when neither is a special symbol.
Comments are arbitrary character sequences enclosed by (* and *). Comments may be nested and may occur between any two lexical units. They may contain embedded formatting characters.