Navigation
A. Preliminaries
As usual, you can retrieve the files for this lab (after first using
git status and git tag to make sure you have cleaned up,
committed, and pushed everything that needs it) with
$ git fetch shared
$ git merge shared/lab3 -m "Start lab3"
$ git push This will add 'shared/lab3' to your current branch (in this case, master).
When you are ready to submit your work, use the usual procedure, whichever of the methods you used to start it. First, commit and push everything, and then use
$ git tag lab3-1 # Or whatever sequence number you get to
$ git push
$ git push --tagsIf you want to download lab3 in another local repository (e.g., you started on the instructional machines and now want to work entirely on your own laptop) then go into this other repository (presumably cloned from your central cs61b repository) and (after committing and pushing anything you already have there) run
$ git pullB. IntDLists
In class, you've seen what is called a singly linked list,
IntList. The term "singly linked" refers to the single pointer (or link),
.tail, used to traverse the elements of the list. For this
problem, we'll define a new data structure, the IntDList, which uses a
doubly linked list.
The IntDList class uses another internal data structure, called a
DNode, to actually house its data. Read through IntDList.java to see why
we refer to this as an internal data structure!!! Each DNode has two links,
one to the next DNode in the sequence (as for IntList) and one to
the previous one.
Note that the IntDList itself contains two pointers, one to
the first DNode in the chain (_front) and one to the last (_back). In the drawing below,
it is referred to as 'A DblList'. This is what is normally called the sentinel node.
In our implementation, however, we just have two pointers _front and _back.
For example, this is how we could represent the sequence [3, 14, 15]:
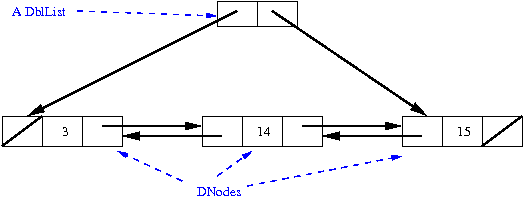
If we wanted to get 14, we could say either "_front._next._val" or "_back._prev._val". Think about what data types _front, _back, _prev, _next, and _val are.
As you can see, unlike IntList, there's an extra level of
indirection at work here. The user (or client) of IntDList
doesn't see the actual DNodes that hold the data. This has various
advantages. One of them is that the client can now do operations that modify
the list without having to return and reassign its value (that is, we
can use void methods to insert and delete things). That's because
we never change the pointer to the IntDList itself; we only modify
its fields.
The doubly linked list with a sentinel node is typically used in practice as the linked list representation,
like in Java's own standard library class, java.util.LinkedList.
Among the skeleton files, you'll find IntDList. Fill in the methods get(i), size(), insertFront(d)
insertBack(d). Note that the IntDList constructor calls insertBack, so you will need to implement insertBack before
running any unit tests in the IntDListTest class.
C. Debugging
We have provided you with a BuggyIntDList.java file that contains a buggy remove method. We have also provided you with a BuggyIntDListTest.java that will test the buggy method and give you some context as to how to fix it. Make all changes to the remove method in BuggyIntDListSolution.java, which you can test by running BuggyIntDListSolutionTest.java. Also, fill in the functions getException, getErrorFunction, and getErrorLineNumber in BuggyIntDListSolution.java after running the debugger and reading its output. DO NOT MAKE ANY CHANGES TO BuggyIntDList.java.
You should see the following when you run BuggyIntDListTest.java.

There are a few important things to note here. First, we can read the type of exception that was thrown - NullPointerException. To read the Oracle docs on what a NullPointerException is, take a look here. To summarize what they say, a NullPointerException is thrown when null is used where an object is required. For example, when trying to call an instance method of a null object, or accessing or modifying the instance variables of a null object.
Next, we can see the stack trace. This is a listing of all functions that were called before the exception was thrown. The stack trace can be read chronologically from bottom to top - that is, first the method BuggyIntDListTest.testRemove was called, and then the method BuggyIntDList.remove was called. Since BuggyIntDList.remove is at the top of our stack trace, we know that it was the function in which the exception was thrown. The stack trace also provides us the exact line numbers where functions are called. We can see that a function call was made at line 14 of BuggyIntDListTest.java, and the NullPointerException occurred at line 33 of BuggyIntDList.java.
If you'd like, take a look at this Stack Overflow Post on what a stack trace is.
Use the stack trace, along with the skeleton code provided to you to fix the remove method in BuggyIntDListSolution.java. Once you understand what a NullPointerException is, the next question is why would this occur? To answer this, use the IntelliJ Debugger and set a break point at the d.remove(0) call in BuggyIntDListTest.java. If you'd like to review using the IntelliJ Debugger, take a look at lab2.

Once you do this, you can use the Step Into button to walk through the remove method.
After pressing Step Into once, you should see the following in your Debugging window at the bottom.

As you step through the program further, the information in this window will change to reflect variables that you come across. Continue pressing the Step Into button, noting the values of variables as you come across them. Stop when you reach the line with the NullPointerException. Does the debugging window tell you what exactly is null? Now, use this information to answer the question of why we would get a NullPointerException here. If you're unsure, feel free to ask your TA for some assistance.
Now that we understand what the error is, and why the error occurred, we can start to think about fixing it. See how the provided code handles the pointer manipulation for p._next and _back, and think about how you can do something similar to fix the buggy line. Remember to make all changes to BuggyIntDListSolution.java.
D. Collections
So far, we've seen fairly primitive types for representing lists of things.
Arrays:
- Advantages: fast random access to items.
- Disadvantages: hard to insert items or delete items.
Hand-made linked lists (e.g., IntList, IntDList):
- Advantages: easy to expand, insert, delete.
- Disadvantages: random access (as opposed to in-sequence access) is slow, requires more space (for pointers) than arrays, and pointer manipulation can be tricky.
Both allow us to represent a sequence of objects, but their syntax is very different, so it's hard to switch from one to the other if you change your mind.
The Java library has types to represent collections of objects and save us from the burden of implementing such collections ourselves, including:
- Lists (sequences) of objects:
ArrayList,LinkedList. - Sets (like lists, but with no order and disallowing duplicates)
of objects:
TreeSet,HashSet. - Maps (a.k.a. associative arrays, symbol tables, and
dictionaries):
TreeMap,HashMap.
All of the collections above are found in the package java.util. A
package is a set of (supposedly related) classes and subpackages.
As elsewhere in Java, the notation java.util.ArrayList means "The
class named ArrayList in the (sub)package named util in the
package named java". To make your life easier, you'll want to import
them before you can use them:
import java.util.ArrayList;
import java.util.LinkedList;(otherwise, you have to write java.util.ArrayList everywhere instead
of just ArrayList).
For today's lab, we'll familiarize ourselves with how to use lists and sets, which you'll be welcome to use on any future homeworks, projects, labs, discussion worksheets, and exams, except where explicitly prohibited.
For example, the following code creates an ArrayList L of integers
and adds 5 and 23 to it:
ArrayList<Integer> L = new ArrayList<>();
L.add(5);
L.add(23);In the code above, don't worry too much about the mysterious
<Integer> or <> syntax. We'll learn about this in the coming weeks --
for now, just accept that somehow this means our L
will contain integers.
Since the LinkedList class is supposed to represent essentially the
same abstraction (a numbered list of items), it has almost the same
API (Application Programming Interface) as ArrayList. For our
purposes today, that means it supports almost the same methods. This
makes it easy to change back and forth between an ArrayList
and a LinkedList.
For our toy example, since LinkedList also has an
add method, we could easily change our code to read:
LinkedList<Integer> L = new LinkedList<>();
L.add(5);
L.add(23);That is, only the declaration of L changes.
It is nice that the Java designers gave us many implementations of the same collection, since each of these implementations has its own strengths and weaknesses (we'll see a glimpse of these tradeoffs in today's lab). However, with what we know so far, we run into a potential problem.
Imagine that Alice and Bob are working on a project together. Alice
needs Bob to write a method readList that reads information and
returns it as some kind of list. Alice doesn't care much what kind of
list it is, since her application is just going to read it in order, a
task at which every list implementation excels. Bob, on the other
hand, isn't 100% sure what kind of list he needs for his task.
With what we know so far, Alice would have to guess what Bob is going to end up deciding and write either:
ArrayList<Integer> myList = readList();or
LinkedList<Integer> myList = readList();This is a huge pain. One potential fix is for Bob stop being such a slacker and get his work done so Alice can use his code, but as we all know, this is just not going to happen. Bob is just that kind of a guy. Through a mechanism known as an interface (upcoming topic) we can avoid this problem.
Java provides not just ArrayList and LinkedList types, but also
a type called List, of which ArrayList and LinkedList are said
to be implementations. List is not a class, but instead an
interface. There are interfaces Set and Map in
java.util as well. What this means is that Alice can actually just
write:
List<Integer> myList = readList();In an upcoming lecture, we'll discuss about how a Java interface is an abstraction of an API (usually without any implementation) that may be shared by many classes. By specifying such an interface as the type of a variable, you get a program that is able to accommodate any of the implementing classes without having to change most of the program. For today, we just want you to know how to use interfaces and implementation classes.
Let's get started with a concrete example by considering the
program in Dups1.java, provided with this lab. Dups1 goes through the
provided input, identifies all duplicates, and then prints all
duplicates to the screen. It takes a single command line argument that
tells it whether to use a linked list or an array list to solve this
problem.
Before you follow the next step, first read the next section, "Running the Dups Files", then proceed.
Compile this program and execute it with
java Dups1 linked < magus.txt
java Dups1 arrays < magus.txtYou should find that the results of the two runs are identical. Look
at the code, and observe that the duplicates method, which actually
does the work of finding duplicates, doesn't actually know whether
it's using a linked list or an array list. It just tells the List to
do its job, and since the LinkedList and ArrayList classes
implement the List class, it can make the exact same calls to both.
Running the Dups Files
Note the code in the main method of the Dups files. What do you think is going on here? Examining all the methods in the Dups java files will also help your understanding.
Essentially, once you run the program, it will wait for user input. Input some strings and terminate the system scanner when you are done (On Unix, this can be with ctrl-d; on Windows, this will be with ctrl-z). The program should print out any duplicates you have.
The command "< magus.txt" is a UNIX command that basically writes out all the words from text file. You cannot use this as a program argument in IntelliJ's "Edit Configurations" tab, because it is a UNIX command. You will have to run that on terminal. You will also notice that if you run the Dups files without any arguments on either IntelliJ or the terminal, the process doesn't seem to end. This is because the program is waiting for you to input arguments. Follow the steps from the previous paragraph to input arguments (if you are using IntelliJ, just click on the Run window to start typing).
Feel free to also experiment with Junit testing, especially if you're using IntelliJ.
ListIterators Part 1
Now look at the duplicates function and get a feeling for how it works.
Observe that it involves repeated calls to the get(i)
method of the List, which returns the ith item of a list. You should check
out the get(i) documentation online.
Think back to the IntDList class that you implemented above. The get
operation in that class has to crawl along a potentially
long list, whereas getting any element of an array can be
done trivially by looking at only one item total.
Since LinkedList is essentially a more-elaborate version of IntDList under
the hood, its get(i) method is slow for the same reason.
Let's do our first computational experiment to measure performance. Try the Unix time commands
time java Dups1 linked < hammurabi110.txt
time java Dups1 array < hammurabi110.txtCompare the results. (We've also set up 'make time' to run these and a couple of other timings. You might want to look at Makefile to how that is done).
In this case, the problem isn't the LinkedList class itself, but the
bone-headed way in which we're trying to use it. Supposing L is a
LinkedList, it's rather silly to be making the sequence of
calls L.get(65), L.get(66), L.get(67), and
so forth. Under the hood (this is not an obvious fact), the LinkedList
is seeking all the way to item #65 and returning it, and then when we
tell it to get item #66, it starts all the way over from the beginning
instead of starting from 65.
Our fundamental problem is that we are using indices to iterate
through the LinkedList using get() instead of letting it handle
the iteration using abstractions that are built specifically around
iteration.
As a warmup to the rather tricky next part of this lab, we'll use
another interface built to support iteration. The interface types
Iterator and ListIterator describe "moving fingers" that effectively
point at elements in the middle of one of the collection types from
the Java library and allow a program to move through the collection
sequentially, regardless of how the collection is actually
implemented. Iterators move only forward, and ListIterators move in
either direction (and make sense only for Lists, which have an order).
As an example of code using a ListIterator, see ListTour.java. Read
and run the code, and make sure you understand
quickIteratorExamples. Then fill out the printTour method as
described. If you want to fix the style errors, feel free to delete
the quickIteratorExamples code, which was provided only for
pedagogical purposes. To do a quick test of your ListTour method, take a look
at the comments in the main method.
ListIterators Part 2
The program Dups2.java uses the ListIterator abstraction to get
around the problem in Dups1.java and puts the two implementations on a
more nearly equal footing, albeit in a rather obtuse way.
Again time the two programs:
time java Dups2 linked < hammurabi110.txt
time java Dups2 array < hammurabi110.txtIf you haven't already, read and understand both programs. The
continue keyword (covered in the reading, but not lecture) means to
terminate the current iteration of the current loop and move on to the
next one immediately.
You may find to be useful the Java library documentation for the java.util.ArrayList and java.util.LinkedList classes and the java.util.List and java.util.ListIterator interfaces.
We'll finish off this section of the lab by finally having you do some coding: Clean up our asinine implementation of Dups2. The Dups2.duplicates method uses two int variables, m and n, to keep track of positions in the list L (and stops once we have scanned back to the position of element we are checking for duplication). To ensure that you've maintained the functionality of Dups2.java, compile it and check the output of
java Dups2 array < hammurabi110.txtagainst
java Dups1 array < hammurabi110.txtBy making better use of the ListIterator interface, we can remove both
of these variables. Create a new file called Dups3.java. Copy and paste
Dups2.java to Dups3.java, and modify the duplicates method so that
duplicates does not use any integer variables. Your code should end up
looking much more elegant than Dups2.java. If you're stuck make sure to
see the java.util.ListIterator
documentation.
We're throwing you in the deep end here with strange new entitites.
There are weird symbols and syntactical strangenesses like the angle
brackets in ListIterator<String>, but by doing some pattern
matching, you should be fine -- we'll learn these new things later.
Don't be afraid to experiment with method calls you aren't sure will
work. Try and cajole
your neighbors into discussion for more efficient progress. This will
probably seem very hard because of all the new syntax, so collaborate
away! To do a quick test of your code, compile Dups3.java and run
java Dups3 array < hammurabi110.txtand check that the output is the same as running the command with Dups1
and Dups2.
Utilities
Currently, the list of duplicate words gets printed in whatever order the words occur in the text. By adding one short line to the program, you can arrange for the list to be printed in sorted order. Figure out how to do this (there is a hint about where to look towards the top of the file) and change Dups3.java accordingly.
Optional: With a bit more searching (this time in the documentation for
java.lang.String), you may be able to find out how to get the sort to
ignore the case of letters, instead of putting all capital letters
before all lower-case letters. If you do this, modify Dups3.java accordingly.
Sets
We used an ArrayList called result to store our result in Dups1
through Dups3. To avoid having duplicate duplicates in result, we
used the result.contains() method to continue to the next
iteration whenever a redundant duplicate was found.
The problem is that the contains method scans the ArrayList
sequentually. While this is not much of a problem for the small inputs
we've been using, it can cause difficulties with larger ones.
The Java library provides collections that are faster for the purpose
of collecting sets of objects without duplicates, namely the TreeSet
and HashSet. Create a new file called Dups4.java. Copy and paste
Dups3.java to Dups4.java. Modify the duplicates method to use a
java.util.TreeSet for the storing results.
See the TreeSet
documentation for a list of methods supported by the TreeSet class.
You'll only need a couple of the methods from the list. In case you
are tempted by dark forces beyond my comprehension, do not try to read
the entirety of the TreeSet documentation.
To make things a little more interesting, you must still return the
result as a List<String>, which a TreeSet<String> is not. Hint: A
TreeSet is a kind of Collection<String>. Take a look through the
documentation of ArrayList. Again, compile Dups4.java
and run the command
java Dups4 array < hammurabi110.txtand be sure that the output is the same as
java Dups3 array < hammurabi110.txtE. Submissions
Make sure your Dups3.java and Dups4.java work as intended. You will be turning in IntDList.java, BuggyIntDListSolution.java, Dups3.java, Dups4.java, and ListTour.java. As usual, tag your files, stage, and commit. Push to your central repository, then push your tags by running (git push --tags).