A. Intro
Obtaining the Files
Download the files for Lab 9 and make a new Eclipse project out of them.
Learning Goals for Today
This lab introduces you to linked lists, structures in which the first node contains a reference to the second, the second a reference to the third, and so on. (Remember the Account class with overdraft protection? It was essentially a list of Accounts, linked through the parentAccount references.)
One of our first linked lists will use inheritance and abstract classes in its implementation. This is admittedly not a common technique. However, it splits off the exceptional cases—the empty list—from the normal cases—everything else—thereby increasing readability. Activities mainly involve implementing some common list operations. (Don't forget to use test-driven development!)
Your operations on linked lists in this lab will not change the existing list structure. Destructive list manipulation will happen in the next lab.
In this lab, we also consider ways to measure the efficiency of a given code segment. There are problems with using elapsed time for this purpose. Instead, we'll use an estimate of how many statements are executed to complete execution. We'll introduce you to the "big-Oh" notation for estimating these statements. We'll say, for example, that determining if an unsorted array contains at least two identical values, requires O(N2) comparisons in the worst case, where N is the number of elements in the array. More details about big-Oh will come in CS 170.
B. Introduction to Linked Lists
Linked List Introduction
In the next three labs we're going to be working with a data structured called a linked list. A linked list is another way for storing sequential data, like an array. However, operations using linked lists will have different run times than operations using arrays. This difference in run time will make linked lists and arrays useful in different circumstances; we'll study this as we go through the course.
Just like we did with the Line class, we're going to be working with several different implementations of a linked list over the next few labs. Again, these versions will have different runtimes associated with access, adding, or removing elements. It isn't important that you memorize the different implementations of the lninked list, but it is very importnat that you be able to look at the class(es) that define the linked list and be able to reason about how it works.
Here's a picture of a simple implementation of a linked list that contains the items "A", "B", and "C" (can you draw the corresponding picture for an array that stores these items?). A linked list consists of nodes that are chained together. Here we represent nodes with the class ListNode. Each node contains an item called myItem. As you can see, the items form a sequence. In this example, the linked list items are Strings, though our linked list here can contain any type of Object, like ArrayList<Object>.
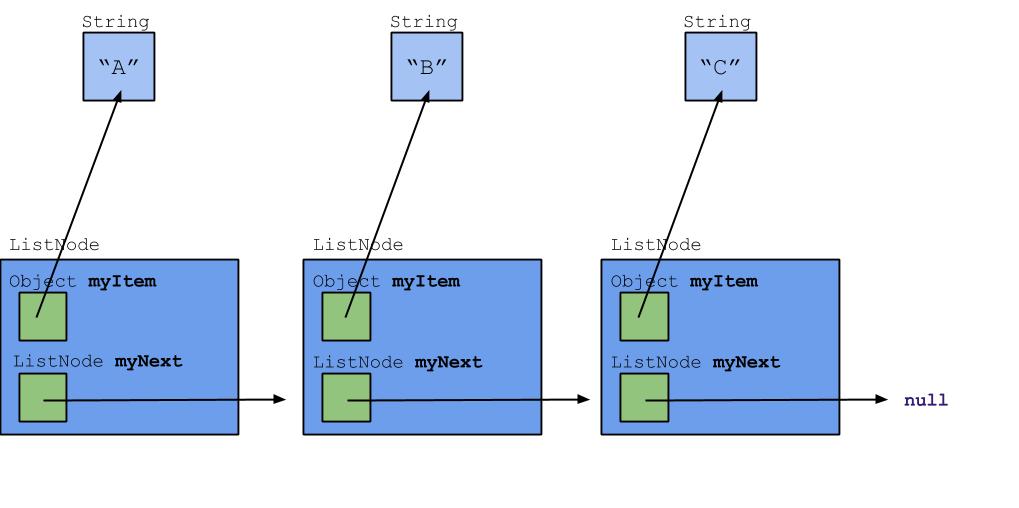
We'll examine the code for this structure in the next slide.
A Straightforward Implementation of a Linked List
Here's an implementation that highlights how each ListNode points to another ListNode. It is important that you feel comfortable with the ideas in this code before moving on. You and your partner should try this on paper:
- Write code that uses the ListNode class to make a list that represent the sequence {1, 2, 3}.
Draw a picture of the ListNodes involved in the list {1, 2, 3}.
public class ListNode { private Object myItem; private ListNode myNext; public ListNode(Object item, ListNode next) { myItem = item; myNext = next; } public ListNode(Object item) { this(item, null); } public Object item() { return myItem } public ListNode next() { return myNext; } }
For those of you who know Scheme, the implementation above is very similar to a Scheme list. Lists in Scheme are linked. Each cons pair is a node; the cdr is the link.
Exercise: A get Method
Implement a method get in the ListNode class. get takes an int position as argument, and returns the list element at the given position in the list, starting with element zero. For example, if get(1) is called, you should return the second item in the list. If the position is out of range, get should throw IllegalArgumentException with an appropriate error message. Assume get is called on the first node in the list.
- First write JUnit tests to provide evidence of the get method correctness.
- Then add the get method to your
ListNodeclass.
Self-test: Testing an Empty List
A CS 61B student suggests that the isEmpty method (tests whether the linked list contains no items) could be implemented as follows:
public class ListNode {
private Object myItem;
private ListNode myNext;
public boolean isEmpty ( ) {
return (this == null);
}
// ...
}Will it return the correct answer (false when it is not empty and true when it is empty)?
If you get the answer wrong, try to write it in Java and test it.
|
True
|
Incorrect. How can
this
ever be
null
, if we can't ever call methods with a null reference?
|
|
|
False
|
Correct. The problem is that we can't call methods with a null reference. Thus we must ensure that
any
list, even an empty list, is represented by a
ListNode
object. One idea is to have a trailer node at the end of each list. This node would not contain any information; it would only be used to satisfy the requirement that each list contains at least one node.
|
C. Linked Lists and Inheritance
Here's an example of using these two types of list nodes to make a list. We claim that it will allow us to solve the problem proposed above.
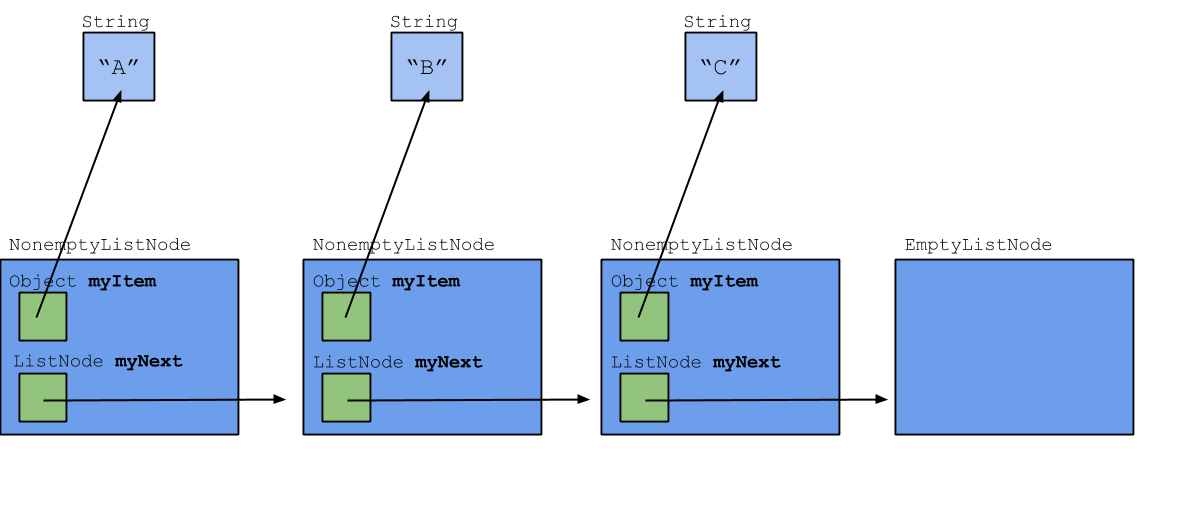
Discussion: Empty and Nonempty List Nodes
Link to the discussion- Why is a trailer node needed for all lists and not just the empty list?
-
What should the trailer node's
myIteminstance variable contain? -
How can the
myNextinstance variable point to both aNonEmptyListNodeand anEmptyListNode?
AbstractListNode Class
Code to be able to create the structure shown in the picture is below. We made a design decision to use inheritance to create this structure (note there aren't any if statements to distinguish between different types of nodes!). We also decided that for this version we won't ever allow any AbstractListNode objects to be changed, so when we "insert" or "delete" things from a List of this type, we create an entirely new list with this change.
The next activities in the lab you will be writing methods for this class.
Here are the classes
abstract public class AbstractListNode {
abstract public Object item();
abstract public AbstractListNode next();
abstract public boolean isEmpty();
// Every other list-processing method goes here.
}
class NonemptyListNode extends AbstractListNode {
private Object myItem;
private AbstractListNode myNext;
public NonemptyListNode(Object item, AbstractListNode next) {
myItem = item;
if (next == null) {
myNext = new EmptyListNode();
} else {
myNext = next;
}
}
public NonemptyListNode(Object item) {
this (item, new EmptyListNode());
}
public Object item() {
return myItem;
}
public AbstractListNode next() {
return myNext;
}
public boolean isEmpty() {
return false;
}
}
class EmptyListNode extends AbstractListNode {
public EmptyListNode() {
}
public Object item() {
throw new IllegalArgumentException ("There is no 'item' value stored in an EmptyListNode.");
}
public AbstractListNode next() {
throw new IllegalArgumentException ("No elements follow an EmptyListNode.");
}
public boolean isEmpty() {
return true;
}
}Self-test: Writing Methods for the AbstractListNode Class
When we write methods for the AbstractListNode we have a lot of options of where we put it. For example the following three versions have the method foo by writing the code in various places. Which version do you think is best?
Disclaimer: This is a design decision with pros and cons so the "correct" answere here is just the version we strongly recommend you use and isn't necessarily "correct".
VERSION 1
// write an abstract method and implement in each of the children
abstract public class AbstractListNode {
//...
abstract public void foo();
}
class NonemptyListNode extends AbstractListNode {
//...
public void foo() {
System.out.println("NonEmpty Foo");
}
}
class EmptyListNode extends AbstractListNode {
//...
public void foo() {
System.out.println("Empty Foo");
}
}VERSION 2
// Don't include an abstract method just implement it in each of the children
abstract public class AbstractListNode {
//...
}
class NonemptyListNode extends AbstractListNode {
//...
public void foo() {
System.out.println("NonEmpty Foo");
}
}
class EmptyListNode extends AbstractListNode {
//...
public void foo() {
System.out.println("Empty Foo");
}VERSION 3
// Take care of everything in the AbstractListNode class
abstract public class AbstractListNode {
//...
public void foo() {
if (this.isEmpty()) {
System.out.println("Empty Foo");
}
else {
System.out.println("NonEmpty Foo");
}
}
}
class NonemptyListNode extends AbstractListNode {
//...
}
class EmptyListNode extends AbstractListNode {
//...
}Choose the best answer below.
|
Version 1
|
Correct! This fully takes advantage of the benefits of inheritance
|
|
|
Version 2
|
Incorrect. If we don't include the methods in
AbstractListNode
, we won't won't be able to call the methods using a
AbstractListNode
reference
|
|
|
Version 3
|
Incorrect. We aren't taking full advantage of the power of inheritance here. Using a conditional statement is comparatively awkward.
|
Exercise: The size Method
Write a JUnit test method to test a size method for AbstractListNode.
Then write the size method. Things to think about:
- What should a
NonemptyListNodedo when thesizemethod is called? - What should a
EmptyListNodedo when thesizemethod is called?
HINTS:
- These bullets above look like a base case and a recursive case, except that they are taking place in two different classes. You might try writing this method recursively, then. In general, both recursive and iterative solutions are possible.
- You might try writing two ways: like VERSION 3 and VERSION 1 (from the last step).
Exercise: Revising the get Method
First, if you haven't yet switched which partner is coding for this lab, do so now.
Then update the get method you wrote earlier in the lab so that it works with our new implementation of the linked list using the AbstractListNode class.
Exercise: the toString Method
The toString method for AbstractListNode returns the String representation of this list, namely:
- a left parenthesis, followed by a blank,
- followed by the
Stringrepresentation of the first element, followed by a blank, - followed by the
Stringrepresentation of the second element, followed by a blank, - ...
- followed by a right parenthesis.
The empty list is represented by the string "( )". The list containing the Integer objects 1, 3, and 5 is represented by the string "( 1 3 5 )".
- Write the
toStringtest cases in your JUnit. - After—and only after—you have written these test cases, write the
toStringmethod.
Exercise: the equals Method
The equals method, given an Object as argument, returns true if this list and the argument list are the same length with equal elements in corresponding positions (determined by using the elements' equals method).
- A bit more test driven development—FIRST write the JUnit tests to provide evidence that your unwritten
equalsmethod works if it passes your tests. - Only after you have written these tests, write the
equalsmethod.
D. Estimating a program's efficiency by timing it
Algorithms
An algorithm is a step-by-step procedure for solving a problem. An algorithm is an abstract notion, simply describing an approach for solving a problem. The code we write in this class, our programs, are implementations of algorithms.
For example, consider the problem of sorting a list of numbers. One algorithm we might use to solve this problem is called bubble sort. Bubble sort says to sort a list by repeatedly looping through the list and swaping adjacent items if they are out of order, until the entire sorting is complete.
Another algorithm we might use to solve this problem is called insertion sort. Insertion sort says to sort a list by looping through our list, taking out each item we find, and putting it into a new list in the correst order. (remember writing this earlier?)
Which is a faster algorithm: bubble sort of insertion sort? And how fast can we make our Java programs that implement them? Much of our subsequent work in this course will involve estimating program efficiency and differentiating between fast algorithms and slow algorithms. This set of activities introduces an approach to making these estimates.
Time Estimates
At first glance, it seems that the most reasonable way to estimate the time an algorithm takes is to measure the time directly. Each computer has an internal "clock" that keeps track of "time" (usually the number of fractions of a second that have elapsed since a given base date); language libraries provide access to the clock. The Java method that accesses the clock is System.currentTimeMillis. A Timer class is provided in Timer.java.
Take some time now to find out
- exactly what value
System.currentTimeMillisreturns, and - how to use the
Timerclass to measure the time taken by a given segment of code.
Exercise: Measuring Insertion Sort
The file Sorter.java contains a version of the insertion sort algorithm you worked earlier. Its main method uses a command-line argument to determine how many items to sort. It fills an array of the specified size with randomly generated values, starts a timer, sorts the array, and prints the elapsed time when the sorting is finished. For example, the unix command sequence
javac Sorter.java
java Sorter 300will time the sorting of an array of 300 randomly chosen elements.
Copy Sorter.java to your directory, compile it, and then determine the size of the smallest array that needs 1 second (1000 milliseconds) to sort. An answer within 100 elements is fine.
Discussion: Timing Results
Link to the discussion
How fast is
Sorter.java
? What's the smallest array size that you and your partner found that takes at least 1 second to sort?
Compare with other people in your lab. Did they come up with the same number as you?
Exercise: Measuring a C Version of Insertion Sort
In this activity we will be running code written in the language C. You don't need to understand it; it is just cool to be able to compare the speed of the same algorithm written in two languages.
The file sort.c is a version of the insertion sort algorithm coded in the language C. Its main function does pretty much the same as the main method of Sorter.java, except that it prints elapsed time in seconds rather than milliseconds.
First, look at the C code and verify the similarity of the C and Java program versions. Then copy sort.c to your directory and compile it with the command
gcc sort.c(If you don't have gcc installed on your computer, try using a lab computer. It might not be worth taking the time to set up gcc right now, because this is just about the only time we'll use C in this class)
The result of this command produces a file named a.out. You then run the program by giving the command ./a.out followed by the size of the array you want to sort, for example,
./a.out 100to sort an array of 100 values.
Run the program, using the array size you just found with Sorter.java, to see how long the C version takes.
Cool huh?
Exercise: Measuring an optimized C version
The C compiler includes an optimizer, which analyzes the program in more depth to produce more efficient compiled code. You access the optimizer using the command-line option "-O2" (that's "minus upper-case Oh 2"):
gcc -O2 sort.cThe compiler again produces a file named a.out that you can use in a command, e.g.
./a.out 100to sort an array of 100 elements.
Conduct the same experiment you did before, finding the smallest array size that needs at least a second to sort. Limit yourself to array sizes that are divisible by 1000.
Compare your Times
Compare your runtime results with other partnerships in your lab nearby. Do they get the same times as you for the Java and C programs?
Discussion: Clock Time and Algorithm Efficiency
Link to the discussionHow appropriate is clock time for measuring algorithm efficiency (not program efficiency)? What is one problem with estimating an algorithm's efficiency by measuring the clock time it takes a program to execute?
E. Analyze the running time of a program
Statement Counting
We learned that timing a program wasn't very helpful for determining how good an algorithm is. An alternative approach is statement counting. The number of times a given statement in a program gets executed is independent of the computer on which the program is run and is probably close for programs coded in related languages.
We make some simplifying assumptions when counting statements. One is that each assignment statement and test that doesn't involve a method call counts as 1. For example, in the program segment
int a = 4 * values[25];
int b = 9 * (a - 24) / (values[1] - 7);
if (a > 0) ...each assignment statement counts as 1 and the if test counts as 1. We will also generally ignore statements not directly relevant to a computation, for example, print statements.
Some easy program segments to analyze:
- A single simple statement or conditionl test counts as 1.
- The count for n simple statements that don't involve conditionals, loops, or method calls is n.
- The count for a method call is the count for evaluating the arguments, plus the count for the body of the method.
Counting Conditionals
With a conditional statement like if, the statement count depends on the outcome of the test. For example, in the program segment
if (a > b) {
temp = a;
a = b;
b = temp;
}there are four statements executed (the test and three assignments) if a > b and only one statement executed if a <= b. That leads us to consider two quantities: the worst case count, namely the maximum number of statements that can be executed, and the best case count, the minimum number of statements that can be executed. The worst case count for the program segment above is 4 and the best case count is 1.
In general, we'll refer to the best-case statement count for a program segment S as bestcount (S) and the worst-case statement count correspondingly as worstcount (S).
Self-test: if... then... else Counting
Consider an if ... then ... else of the form
if (A) {
B;
} else {
C;
}where A, B, and C are program segments. (A might be a method call, for instance.) Give an expression for the best-case statement count for the if ... then ... else in terms of bestcount (A), bestcount (B), and bestcount (C).
Choose one answer.
|
bestCount (A) + bestCount (B) + bestCount (C)
|
Incorrect. If we run the program, will both B and C occur?
|
|
|
minimum (bestCount (A), bestCount (B), bestCount (C))
|
Incorrect. There's no situation where we can run the program and only one of the statements executes.
|
|
|
bestCount (A) + minimum (bestCount (B), bestCount (C))
|
Correct!
|
|
|
bestCount (B) + minimum (bestCount (A), bestCount (C))
|
Incorrect. Does statement B necessarily run? Is there any situation where we could skip A?
|
|
|
bestCount (C) + minimum (bestCount (A), bestCount (B))
|
Incorrect. Does statement C necessarily run? Is there any situation where we could skip A?
|
Selt-test: Statement Counting with a Loop
Consider the following program segment, which you could imagine appears in the IntSequence class.
for (int k = 0; k < N; k++){
sum = sum + myValues[k];
}In terms of N, how many operations are executed in this loop? You should count 1 for each of the actions in the for-loop header (the initialization, the test, and the increment).
3N+2
A Slightly More Complicated Loop
Now consider code for remove:
void remove (int pos) {
for (int k = pos + 1; k < myCount; k++){
myValues[k-1] = myValues[k];
}
myCount--;
}The counts here depend on pos. Each column shows the total steps for a value of pos.
| category | pos = 0 | pos = 1 | pos = 2 | ... | pos = myCount - 1 |
|---|---|---|---|---|---|
| assignment to k | 1 | 1 | 1 | 1 | |
| loop tests | myCount | myCount - 1 | myCount - 2 | 1 | |
| adds to k | myCount - 1 | myCount - 2 | myCount - 3 | 0 | |
| assignments to array elems | myCount - 1 | myCount - 2 | myCount - 3 | 0 | |
| assignment to myCount | 1 | 1 | 1 | 1 | |
| Totals | 3 * myCount | 3 * myCount - 3 | 3 * myCount - 6 | 3 |
We can summarize these results as follows: a call to remove with argument pos requires in total:
- 1 assignment
k; myCount-posloop tests;myCount-pos-1increments ofk;myCount-pos-1assignments tomyValueselements;- 1 assignment to
myCount.
If all these operations take roughly the same amount of time, the total is 3 * (myCount - pos). Notice how we write the number of statements as a function of the input argument.
Statement Counting in Nested Loops
To count statements in nested loops, you compute inside out. As an example, we'll consider an implementation of removeZeroes from an earlier quiz:
public void removeZeroes() {
for (int k = 0; k < myCount;) {
if (myValues[k] == 0) {
remove(k);
}
else {
k = k + 1;
}
}
}Here, there is a best case—no removals at all—and a worst case, removing everything. Again, we create a table:
| category | best case | worst case |
|---|---|---|
| inits of k | 1 | 1 |
| increments of k | myCount | 0 |
| tests of k | myCount + 1 | myCount + 1 |
| array accesses | myCount | myCount |
| comparisons | myCount | myCount |
| removals | 0 | myCount |
The only thing left to analyze is the total cost of the calls to remove in the worst case: the sum of the cost of calling remove, myCount number of times. We already approximated the cost of a call to remove for a given pos and myCount value; that's 3 * (myCount - pos), In our removals, pos is always 0, and only myCount is changing. Thus the total cost of removals is
3 * myCount + 3 * (myCount - 1) + 3 * (myCount - 2) + ... + 3 * 1 = 3 * (myCount + myCount - 1 + myCount - 2 + ... + 1)where myCount is the original number of integers in the IntSequence.
A handy formula to remember is
1 + 2 + ... + k = k * (k + 1) / 2This lets us simplify the cost of removals:
= 3 * myCount * (myCount + 1) / 2Whew!
Abbreviated Estimates
Producing those statement count figures for even so simple a program segment was a lot of work. Normally we don't need so exact a count, but merely an estimate of how many statements will be executed.
The most commonly used estimate is that a program segment runs in time proportional to a given expression, where that expression is as simple as possible. The term "proportional to ..." means "is approximately a constant times ...". Thus 2n + 3 is proportional to n since it's approximately 2 times n; and 3n5 + 19n4 + 35 is proportional to n5 since it's approximately 3 times n5. (The approximation is better for larger values of n.)
Basically what we're doing here is discarding all but the most meaningful term of the estimate and also discarding any constant factor of that term.
Applying this estimating technique to the removeZeroes method just analyzed results in the following estimates:
- The best case running time of
removeZeroesis proportional to the length of the array. - The worst case running time of
removeZeroesis proportional to the square of the length of the array.
This is because the actual statement count,
4 * myCount + 2, is proportional to myCount in the best case, and
3 * myCount + 2 + 3 * myCount * (myCount+1)/2 is proportional to the square of myCount in the worst case.
Big Ɵ
A notation often used to provide even more concise estimates is "big-Theta" (Ɵ). Say we have two functions f(n) and g(n) that take in nonnegative integers and return real values. We could say
f(n) is in Ɵ(g(n))
if and only if f(n) is proportional to g(n) for all large enough values of n.
Why do we say "in" Ɵ? You can think of Ɵ(g(n)) as a set of functions that all grow similarly to g. When we claim that f is in this set, we are claiming that f is a function that grows similarly to g.
There are analogous notations called "big-Oh" (Ο) and "big-Omega" (Ω), where "big-Oh" is used for upper-bounding and "big-Omega" is used for lower-bounding. If f(n) is in O(g(n)), it means f is in a set of functions that are upper-bounded by g.
Formal Definition of Big-Oh
Above we game you some intuition on big-Oh. Here are more formal, mathetmatical definitions. These are two equivalent definitions of the statement "f(x) is in O(g(x))":
There exist positive constants M and N such that for all values of n > N, f(n) < M * g(n). Example: Given f(n) = n2 and g(n) = n3, is f(n) in O(g(n))? Is g(n) in O(f(n))?
We can choose M = 1 and N = 1. We know that for all n > 1, n2 < 1 * n3. Therefore, f(n) is in O(g(n)).
However, it is impossible to find positive integers M and N such that n3 < M * n2 for all n > N. Notice that to satisfy the inequality n3 < M * n2, n must be less than M. But since M a constant, n3 < M * n2 does not hold for arbitrarily large values of n.

This means, essentially, that for very large values of n, f is not a lot bigger than g.
Example: Given f(n) = n5 and g(n) = 5n, is f(n) in O(g(n))? Is g(n) in O(f(n))?
After repeatedly applying L'hopital's rule, we see that f(n) is in O(g(n)):
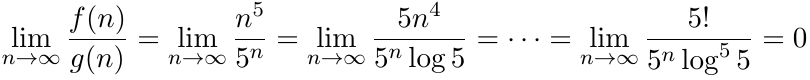
However, g(n) is not in O(f(n)):
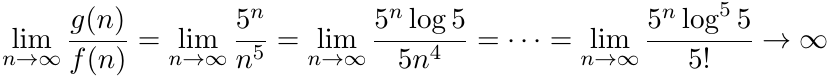
Big-Ɵ and Big-Ω
There are a few different ways to define big-Ω and big-Ɵ.
Big-Ω:
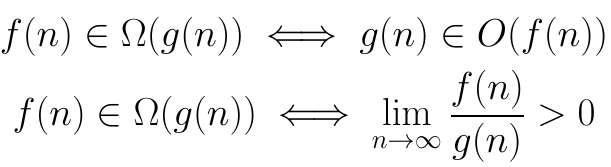
Big-Ɵ:
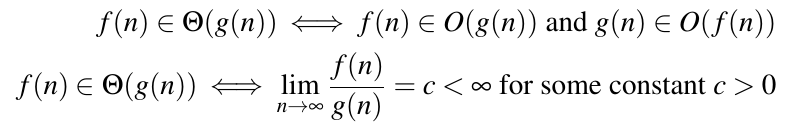
The Variables in the "proportional to" Expression
You may have observed, in our analysis of remove, that we were careful to make clear what the running time estimate depended on, namely the value of myCount and the position of the removal. Unfortunately, students are sometimes careless about specifying the quantity on which an estimate depends. Don't just use "n" without making clear what "n" means.
Self-test: Choosing the Proportionality Variable
Complete the following sentence.
Insertion time of an integer at position k of an IntSequence containing n items, with capacity greater than n, is proportional to ...
|
the capacity of the
IntSequence
|
Incorrect. We won't care what happens to the unused items in
|
|
k
, the position where it is inserted
|
Incorrect. But this would have been correct if our
IntSequence
grew to the left, rather than the right...
|
|
n
, the number of items in the
IntSequence
|
Incorrect. We don't have to touch any items below the kth one that we insert.
|
|
n - k
, the number of items minus the position where it is inserted
|
Correct! Once we insert an item, we have to move over all items above it (and there are n-k of them)
|
Commonly Occurring Time Estimates
Some commonly occurring estimates and situations in which they arise are the following:
- constant time: a single statement or a constant number of elementary operations;
- "proportional to (suitably defined) N": applying a constant-time process to each of a collection of N items;
- "proportional to N2": applying a constant-time process to all pairs of items in a collection of N items.
Logarithmic Algorithms
We will shortly encounter algorithms that run in time proportional to log N for some suitably defined N. Recall from algebra that the base-10 logarithm of a value is the exponent to which 10 must be raised to produce the value. It is usually abbreviated as log10. Thus
- log10 1000 is 3 because 103 = 1000
- log10 90 is slightly less than 2 because 102 = 100
- log10 1 is 0 because 10 0 = 1
In algorithms, we commonly deal with the base-2 logarithm, defined similarly.
- log2 1024 is 10 because 210 = 1024
- log2 9 is slightly more than 3 because 23 = 8
- log2 1 is 0 because 20 = 1
Another way to think of log is the following: logBN is the number of times N must be divided by B before it hits 1.
Thus, algorithms for which the running time is logarithmic are those where processing discards a large proportion of values in each iterations. The binary search algorithm you encountered a few weeks back (in the "guess a number" game) is an example. In each iteration, the algorithm discards half the possible values for the searched-for number, repeatedly dividing the size of the problem by 2 until there is only one value left.
For example, say you started with a range of 1024 numbers in the number guessing game. Each time you would discard half of the numbers so that each round would have the following numbers under consideration:
| Round # | Numbers left |
|---|---|
| 1 | 1024 |
| 2 | 512 |
| 3 | 256 |
| 4 | 128 |
| 5 | 64 |
| 6 | 32 |
| 7 | 16 |
| 8 | 8 |
| 9 | 4 |
| 10 | 2 |
| 11 | 1 |
We know from above that log21024 = 10 which gives us an approximation of how many rounds it will take.
We will see further applications of logarithmic behavior when we work with trees in subsequent activities.
F. Conclusion
Submission
Submit the following files as lab09, one submission per partnership:
- AbstractListNode.java
- ListNode.java
Reading
The reading over the next two labs is DSA chapter 6.