O(N)
A. Intro: Balancing search trees
An Overview of Balanced Search Trees
Before we begin remember to download files for lab18.
Over the past couple of weeks, we have analyzed the performance of algorithms for access and insertion into binary search trees under the assumption that the trees were balanced. Informally, that means that the paths from root to leaves are all roughly the same length, and that we won't have to worry about lopsided trees in which search is linear rather than logarithmic.
This balancing doesn't happen automatically, and we have seen how to insert items into a binary search tree to produce worst-case search behavior. There are two approaches we can take to make tree balancing happen: incremental balance, where at each insertion or deletion we do a bit of work to keep the tree balanced; and all-at-once balancing, where we don't do anything to keep the tree balanced until it gets too lopsided, then we completely rebalance the tree.
In the activities of this segment, we start by analyzing some tree balancing code. Then we explore how much work is involved in maintaining complete balance. We'll move on to explore two kinds of balanced search trees, AVL trees and 2-3-4 trees.
B. Making a Balanced Tree
Exercise: Build a Balanced Tree from a Linked List
In BST.java complete the linkedListToTree method which should build a balanced binary search tree out of an already sorted LinkedList. Also, provide a good comment for the method linkedListToTree
Question: If it's a BST, why are the items just of Object type? Why not Comparable?
Answer: Because you shouldn't need to ever do any comparisons yourself. Just trust that the order in the LinkedList is correct.
Self-test: linkedListToTree Speed
Give the runtime of linkedListToTree, where N is the length of the linked list. The runtime is in:
|
|
Correct! Notice we can only call
iter.next()
N times, and since we call it at most once per recursive call, this must be the runtime of the algorithm.
|
|
O(N^2)
|
Incorrect. Notice how in each recursive call we call
iter.next()
exactly once (or return null). How many of these recursive calls can there be?
|
|
O(log N)
|
Incorrect. Even though we make a recursive call where we divide the problem in half, we make two of these recursive calls, so we don't reduce to log N time.
|
|
(N*log N)
|
Incorrect. Notice how in each recursive call we call
iter.next()
exactly once (or return null). How many of these recursive calls can there be?
|
Discussion: Shape of linkedListToTree
Link to the discussion
Is the tree built by
linkedListToTree
maximally balanced
(recall from lecture)? Briefly explain why, or give a counter-example.
Self-test: Maintaining Balanced Search Trees
Suppose we wished to maintain a maximally balanced binary search tree after each insertion. Insertion of 1 into the tree below, as marked in bold, is a worst case.
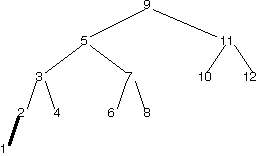
Imagine the maximally balanced version of this binary search tree that has ALL of the TreeNodes in the tree above (including the new 1).
How many TreeNodes are already in the right place where we define "right place" as having the correct parent and children.
|
3
|
Correct! 10, 11, and 12 are in the right place. If you didn't get this right the first time, try to see if you can draw the tree now.
|
|
|
4
|
Incorrect.
|
|
|
5
|
Incorrect.
|
|
|
8
|
Incorrect.
|
C. "Almost-balanced" trees
"Almost-balanced" Trees
The preceding steps suggests that imposing a restriction that our search trees must be maximally balanced after every insertion requires a lot of effort. We might worry that the time spent balancing the tree is greater than the time benefit from keeping it balanced, if we do a lot of inserts.
A solution is to relax our definition of balance. Trees don't have to be maximally balanced, they can be "almost-balanced". A height-balanced tree is one example of a tree that is balanced in some sense but not maximally balanced. In a height-balanced tree, the heights of two subtrees for any node in the tree differ by at most 1. Here are some examples of height-balanced trees.
o
/ \
o o
/
oHeight of left subtree is 2, height of right subtree is 1. Balance requirements also hold recursively for the children.
o
/ \
o o
/ / \
o o o
/
oHeight of left subtree is 2, height of right subtree is 3. Balance requirements also hold recursively for the children.
AVL Trees
AVL trees (named after their Russian inventors, Adel'son-Vel'skii and Landis) are height-balanced binary search trees, in which information about tree height is stored in each node along with the myItem information. Restructuring of an AVL tree after insertion is done via a process known as a rotation, an example of which is shown below.
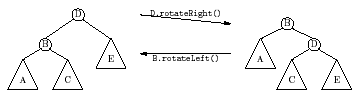
(Note: a triangle indicates a subtree that we haven't fully drawn out)
A rotation preserves the order relationships among the elements (so it is still a BST), but changes the levels of the nodes.
Usually when you insert a new item into an AVL tree, nothing special has to happen. However, there are two special cases where, after you insert, you must perform rotations in order to rebalance the tree. The two cases are shown below:
- Case 1
Before insertion
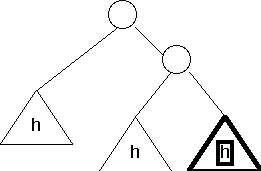
(Note the h inside the subtrees indicate their height)
After insertion
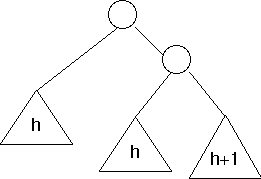
Notice that the subtree to the right of the root now has height h+2, but the subtree to the left of the root has height h. This is not height-balanced, because they differ by more than 1.
After rotation
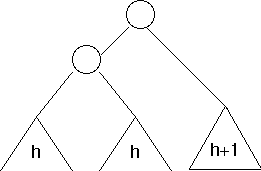
Now both the left and right subtrees of the root have height h+1.
- Case 2
Before insertion
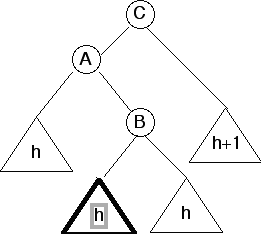
After insertion
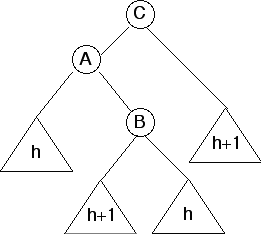
Notice that the subtree to the right of A (rooted at B) has height h+2, but subtree to the left of A has height h. They differ by 2, so this is not height-balanced.
After rotations
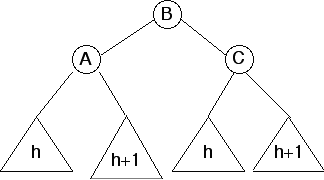
This second case is essentially a left rotation followed by a right rotation.
There are two other cases of insertions for when you might want to use rotations, but these are mirror images of the ones shown.
How exactly do you decide what and where to apply a rotation? After inserting a new node, check its ancestors one by one. As soon as you find an ancestor that isn't balanced, you must be in one of the cases above. Apply the appropriate rotation, and you're done.
Self-test: AVL Tree Insertion Time
Assume there are N items in a tree.
How many operations are required to do a single rotation?
|
a constant number
|
Correct! In order to do a rotation, all we have to do is move the references at the top of the unbalanced subtrees. No matter how big the subtrees are, just moving the references at the top moves the whole subtree.
|
|
|
a number proportional to log N
|
Incorrect. Look back carefully at the algorithm. How many references do we have to change in order to move a whole subtree?
|
|
|
a number proportional to N
|
Incorrect. A rotation applies locally to a small portion of the tree; there should be no need to move the whole tree.
|
|
|
a number proportional to N log N
|
Incorrect. Incorrect. A rotation applies locally to a small portion of the tree; there should be no need to move the whole tree.
|
|
|
a number proportional to N^2
|
Incorrect. Incorrect. A rotation applies locally to a small portion of the tree; there should be no need to move the whole tree.
|
How many rotations are required for a single insertion?
|
a constant number
|
Correct. Assuming the tree is already an AVL tree before the insertion, at most two rotations are necessary.
|
|
|
a number proportional to log N
|
Incorrect.
|
|
|
a number proportional to N
|
Incorrect.
|
|
|
a number proportional to N log N
|
Incorrect.
|
|
|
a number proportional to N^2
|
Incorrect.
|
Discussion: Apply a Rotation by Hand
Link to the discussionConsider the following tree. Assuming that the 9 was just added, which rotation would be appropriate? It might be helpful to look back at the previous section.
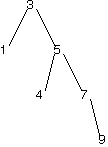
Describe the result of applying a rotation to balance the tree.
Exercise: Coding Rotations
Check out the file AVLTree.java. It contains code for an AVL tree class, but its insert method is incomplete! Fill it in with your own implementation. There's a main method that runs some very basic tests. You may want to write your own tests to be more sure of correctness.
Note: The file contains a fair amount of skeleton code. Don't get ovewhelmed! You'll want to spend some time reading the file before you get started coding. Be aware that we coded some useful helper methods for you already, so be sure to take advantage of those.
Also note that this tree class has two classes of nodes: empty and nonempty nodes. Do you remember this design pattern from working with linked lists? We chose to use this design pattern here becaues it should greatly simplify the code you have to write, freeing you from needing to do any null checks. You also shouldn't have to do any casting.
Deletion in AVL Trees
Deletion in an AVL tree can also result in an imbalance. Luckily, the process for fixing this is very similar to that for insertions. Here's how it works.
- Delete as you normally would in a BST (review this if you don't remember!)
- Starting from the node you just deleted, travel up the tree and check if each node is unbalanced. (If it is unbalanced, it should look like one of the After insertion pictures we showed you for insertion — also, the balance factor has a certain value) If a node is unbalanced, fix it with the appropriate rotation like you did in the insertion case. Unlike with insertion, however, you may have to do this with multiple nodes as you go up the tree.
Luckily for you, you don't have to code deletion into your AVL tree. Just understand the concept.
D. B-trees
2-3-4 Trees
Another approach to "almost-balanced trees" don't involve rotations. Instead, it relaxes the constraint that nodes can only have one item in it and stuffs more into a node.
In a 2-3-4 tree, each node can have up to 3 keys in it. The additional invariant is that any non-leaf node must have one more child than it does keys. That means that a node with 1 key must have 2 children, 2 keys with 3 children, and 3 keys with 4 children. That's why it's called a 2-3-4 tree.
Here's an example of one:
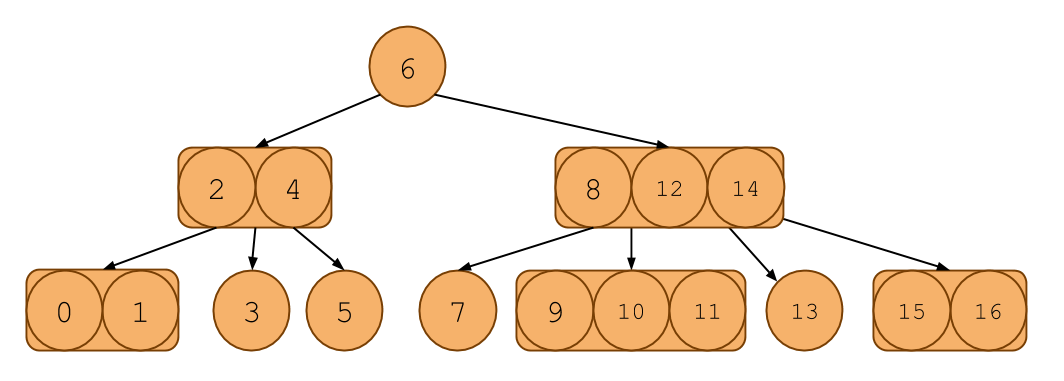
It looks like a binary search tree, except each node can contain 1, 2, or 3 items in it. Notice that it even follows the ordering invariants of the binary search tree.
Searching in a 2-3-4 tree is much like searching in a binary search tree. Like a BST, if there is only one key in a node, then everything to the left of the key is less than it and everything to the right is greater. If there are 2 keys, say A and B, then the leftmost child will all have keys less than or equal A, the middle child will have keys between A and B and the rightmost child will have keys greater than or equal to B. You can extend this to the 3 key case as well.
Discussion: Height of a 2-3-4 Tree
Link to the discussionWhat does the invariant that a 2-3-4 tree has one more children than keys tell you about the length of the paths from the root to leaf nodes?
Insertion into a 2-3-4 Tree
Although searching in a 2-3-4 tree is like searching in a BST, inserting a new item is a little different.
We begin with insertion just like in a BST, where we must find the correct place for the key that we insert to go, by traversing down the tree. The difference comes as soon as we come across a node that already has 3 keys. We'd like to put the new item here, but it won't fit, because each node can only have a max of 3 keys in it. What should we do?
We do NOT add the item as a new child of the node. Instead, we will push the existing middle key up into the parent node and split the remaining two keys into two 1-key nodes (Because we are doing this from the top down, the parent will always have room). Then we add the new item to one of the split nodes.
For instance, say we had this 2-3-4 tree:
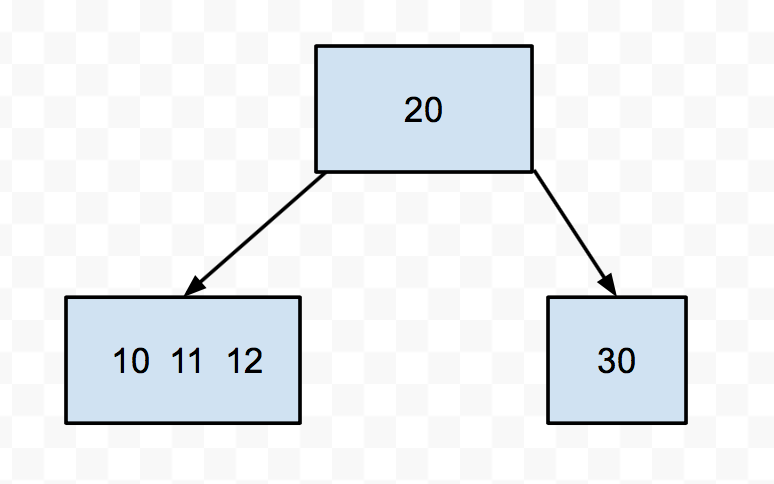
Let's try to insert 9 into this tree. We see it's smaller than 20, so we go down to the left. Then we find a node with 3 keys. We push up the middle (11), then split the 10 and the 12. Then we put the 9 in the appropriate split node.
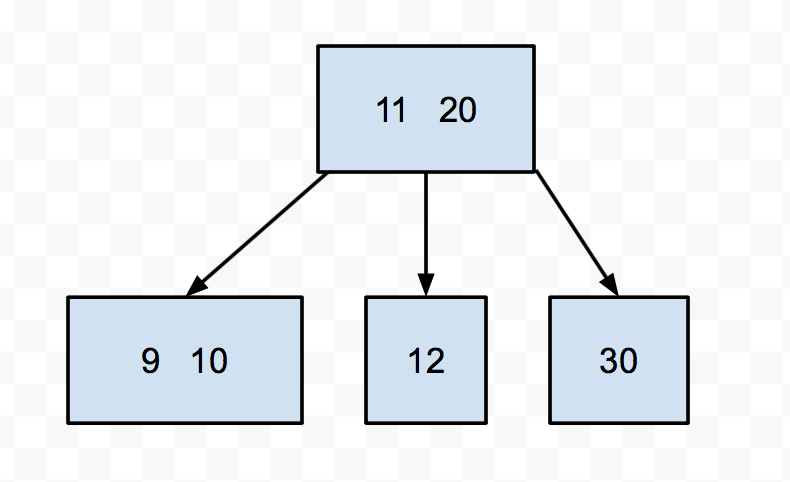
There is one little special case we have to worry about when it comes to inserting, and that's if the root is a 3-key node. After all, roots don't have a parent. In that case, we still push up the middle key and instead of giving it to the parent, we make it the new root.
Self-test: Growing a 2-3-4 Tree
Suppose the keys 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10 are inserted sequentially into an initially empty 2-3-4 tree. Which insertion causes the second split to take place?
|
2
|
Incorrect.
|
|
|
3
|
Incorrect.
|
|
|
4
|
Incorrect.
|
|
|
5
|
Incorrect
|
|
|
6
|
Correct! The insertion of 4 splits the 1-2-3 node. Then the insertion of 6 splits the 3-4-5 node.
|
|
|
7
|
Incorrect.
|
|
|
8
|
Incorrect.
|
|
|
9
|
Incorrect.
|
|
|
10
|
Incorrect.
|
B-trees
A 2-3-4 tree is a special case of a structure called a B-tree. What varies among B-trees is the number of keys/subtrees per node. B-trees with lots of keys per node are especially useful for organizing storage of disk files, for example, in an operating system or database system. Since retrieval from a hard disk is quite slow compared to computation operations involving main memory, we generally try to process information in large chunks in such a situation, in order to minimize the number of disk accesses. The directory structure of a file system could be organized as a B-tree so that a single disk access would read an entire node of the tree. This would consist of (say) the text of a file or the contents of a directory of files.
E. Red-Black Trees
We have just seen two ways that we can implement balanced search trees. However there is a third that is quite common in real applications. There is a third type of self-balancting BST is called the red-black tree. Like an AVL Tree, a red-black tree also uses rotations to balance; however there are some additional invariants related to "coloring" each node red or black. Overall it turns out similar to an AVL tree with a slightly less strict height balance invariant.
We won't make you code up a red-black tree (they are notoriously tedious to code: 5 different cases for insertion and 6 different cases for deletion, not counting left/right differences!), but just be aware that there are different balanced trees available to you depending on your needs. On the theoretical side, it is cool to note that there is a isometry (a mapping) between 2-3-4 trees and Red-Black trees. That means that you can turn one into the other really easily. Neat, huh?
The java.util.TreeMap and TreeSet classes are implemented as red-black trees.
F. Tries
Tries
A structured called a trie (pronounced "try") is a tree structure that can be useful for storing a set of words. Probably the easiest way to explain what a trie is is just to show it.
Suppose we want to store the following words: "can", "cap", "cat", "to", "too", and "two". The trie looks like this:
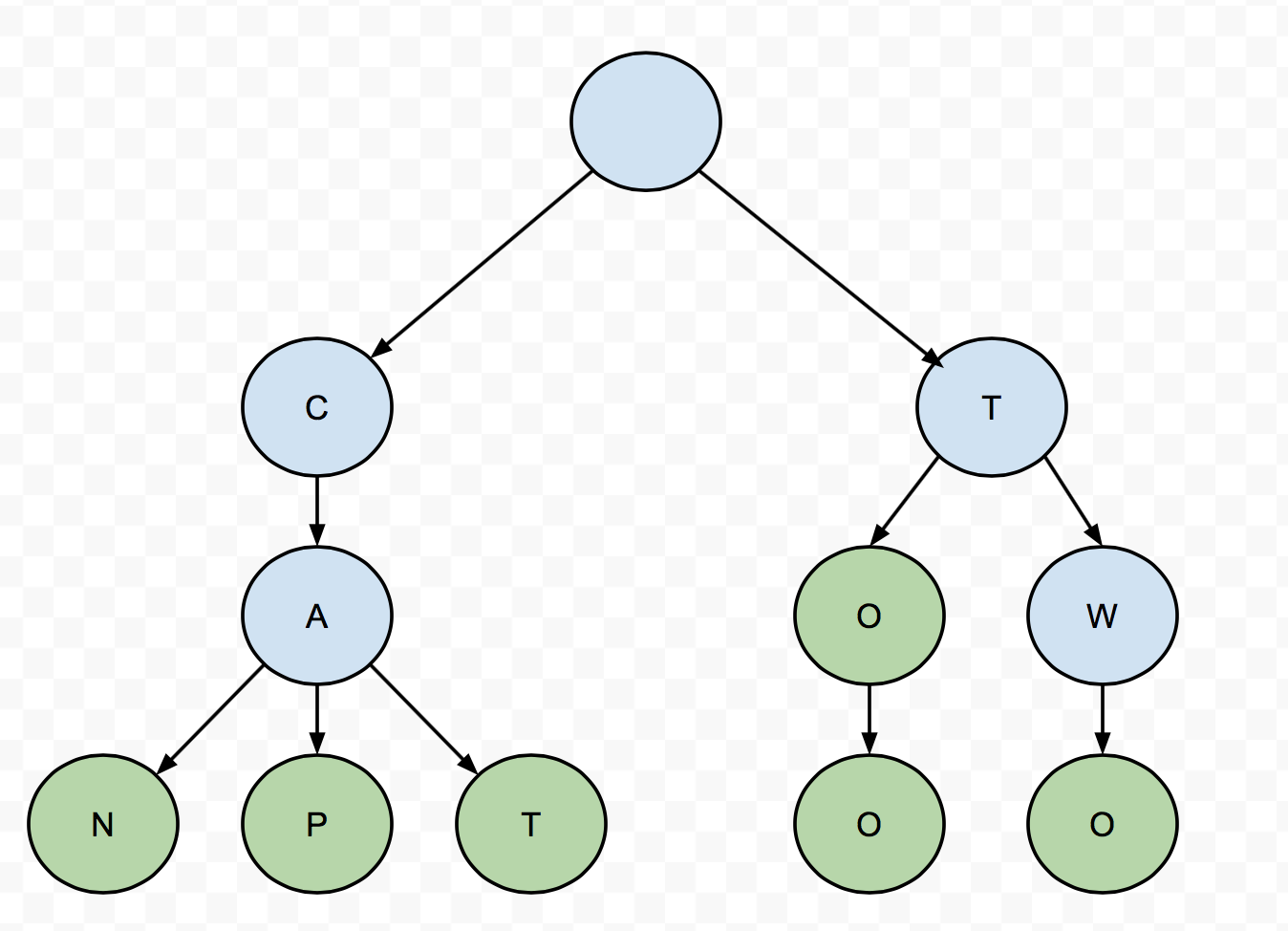
The green nodes are terminal nodes that contain valid words. The blue nodes are nonterminal nodes that contain prefixes of other words, but not valid words themselves. To check if the trie contains a particular word, you just follow the tree down letter-by-letter until you find the terminal node containing the word. Notice that the time required to find a word in the structure will be at worst proportional to the length of word.
Depending on how many words we're storing, this can provide a dramatic improvement over structures we've considered so far. Suppose, for example, that we want to store most of the 265 words consisting of five lower-case letters. Putting them in an array and using binary search requires over 20 comparisons to find a given word, as compared to 5 using a trie.
Tries are said to have a fail-fast property. What this means is, if you lookup a word in a trie, and it turns out the trie does not contain that word, the try can tell you very quickly that it doesn't. Convince yourself that the time it takes to determine a word is NOT in a trie is proprotional to less than (or equal to) the length of the word.
The big disadvantage of using a trie is that we trade space efficiency for time efficiency. If we're storing English words, the branching factor at each level can be as much as 26! Although this is a constant number, it can lead to a very large tree very quickly.
Exercise: Lookup in a Trie
First, switch which partner is coding for this lab, if you haven't already.
We want to make a Dictionary class that stores words and associated definitions. Complete the class in the file Dictionary.java to allow you to add words and definitions to the dictionary, and to allow you to lookup the definitions associated with words. The class should store words and definitions in a trie structure.
Note: Words can consist of any characters, not just the 26 alpha characters. Capital and lowercase letters are considered different characters.
G. Conclusion
Summary
We hope enjoyed learning about balanced search trees. They can be a bit tricky to implement compared to a normal BST, but the speedup in runtime helps us immensely in practice! Now that you've seen them, hopefully you can appreciate the work that went into Java's TreeMap and TreeSet that you can use as a black box.
Even though we gave you only a glimpse at tries, we hope that you can see how fun of a data structure they are. Tries are an example of how we can make tradeoffs between space efficiency for time efficiency, a common theme when it comes to data structures. Although we didn't cover tries very deeply in these labs, you might imagine some of the applications that tries have, including autocompletion and spell checking!
Submission
Please turn in AVLTree.java, Dictionary.java, and BST.java.
Readings
For next lab, read DSA chapter 8 (Priority Queues).