A. Intro
Download the code for Lab 23 and create a new Eclipse project out of it.
Learning Goals
Today's activities tie up some loose ends in the coverage of sorting. First, an algorithm, derived from Quicksort, to find the kth largest element in an array is presented. Then comes an activity that maintains a file sorted by multiple keys. Next, the property of stable sorting is discussed. Finally, some linear-time sorting algorithms are described.
B. Finding the Kth Largest Element
Finding the Kth Largest Element
Suppose we want to find the kth largest element in an array. We could just sort the array largest-to-smallest and then index into the kth position to do this. Is there a faster way? Finding the kth item ought to be easier since it asks for less information than sorting. Indeed, finding the smallest or largest requires just one pass through the collection.
You may recall the activity of finding the kth largest item (1-based) in a binary search tree augmented by size information in each node. The desired item was found as follows:
- If the right subtree has
k-1items, then the root is thekitem, so return it. - If the right subtree has
kor more items, find thekth largest item in the right subtree. - Otherwise, let
jbe the number of items in the right subtree, and find thek-j-1st item in the left subtree.
A binary search tree is similar to the recursion tree produced by the Quicksort algorithm. The root of the BST corresponds to the divider element in Quicksort; a lopsided BST, which causes poor search performance, corresponds exactly to a Quicksort in which the divider splits the elements unevenly. We use this similarity to adapt the Quicksort algorithm to the problem of finding the kth largest element.
Here was the Quicksort algorithm.
- If the collection to be sorted is empty or contains only one element, it's already sorted, so return.
- Split the collection in two by partitioning around a "divider" element. One collection consists of elements greater than the divider, the other of elements less or equal to the divider.
- Quicksort the two subcollections.
- Concatenate the sorted large values with the divider, and then with the sorted small values.
Discussion: Quickselect
Link to the discussionCan see how you can adapt the basic idea behind the Quicksort algorithm to finding the kth largest element? Describe the algorithm below.
Note: The algorithm's average case runtime will be proportional to
N
, where
N
is the total number of items, though it may not be immediately obvious why this is the case.
C. A Linear Time Sort
Counting Sort
Suppose you have an array of a million Strings, but you happen to know that there are only three different varieties of Strings in it: "Cat", "Dog", and "Person". You want to sort this array to put all the cats first, then all the dogs, then the people. How would you do it? You could use merge sort or Quicksort and get a runtime proportional to N log N, where N is ~one million. Can you do better?
We think you can. Take a step back and don't think too hard about it. What's the simplest thing you could do?
We propose an algorithm called counting sort. For the above example, it works like this:
- First create an int array of size three. Call it the
countsarray. It will count the total number of each type of String. Iterate through your array of animals. Every time you find a cat, increment
counts[0]by 1. Every time you find a dog, incrementcounts[1]by 1. Every time you find a person, incrementcounts[2]by 1. As an example, the result could be this: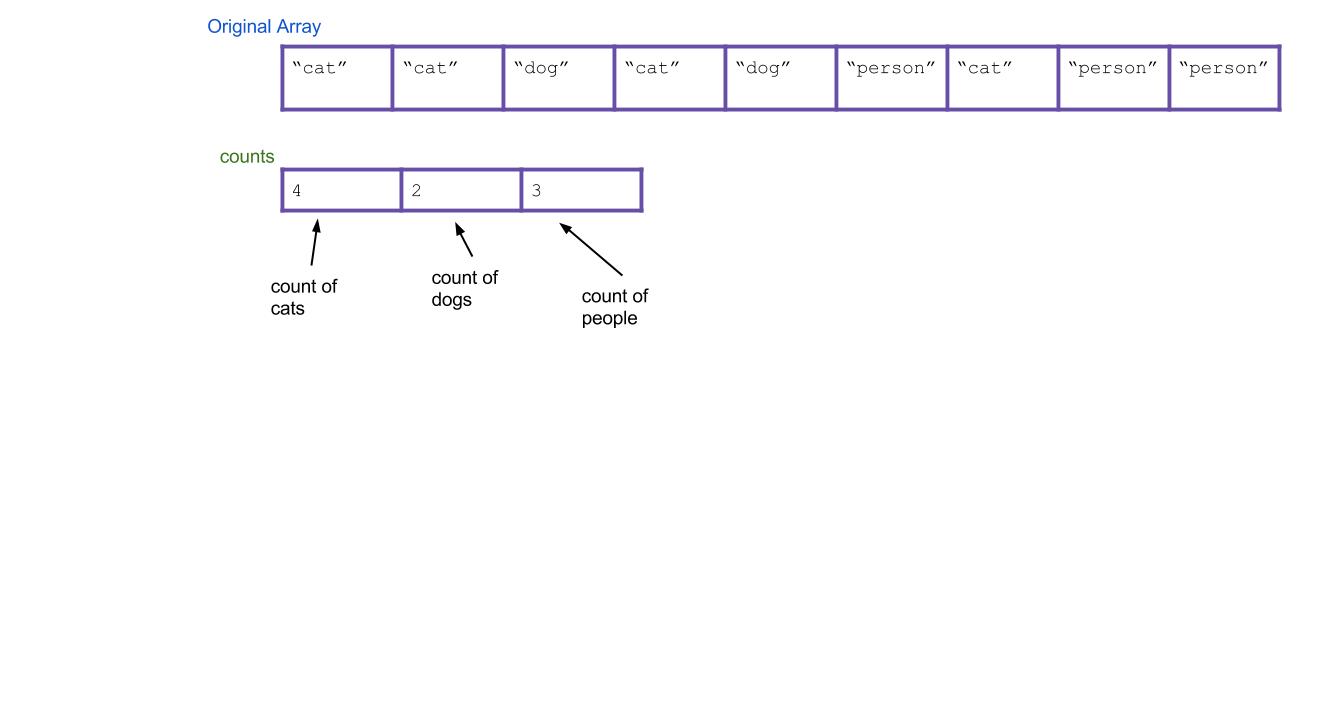
Next, create a new array that will be your sorted array. Call it
sorted.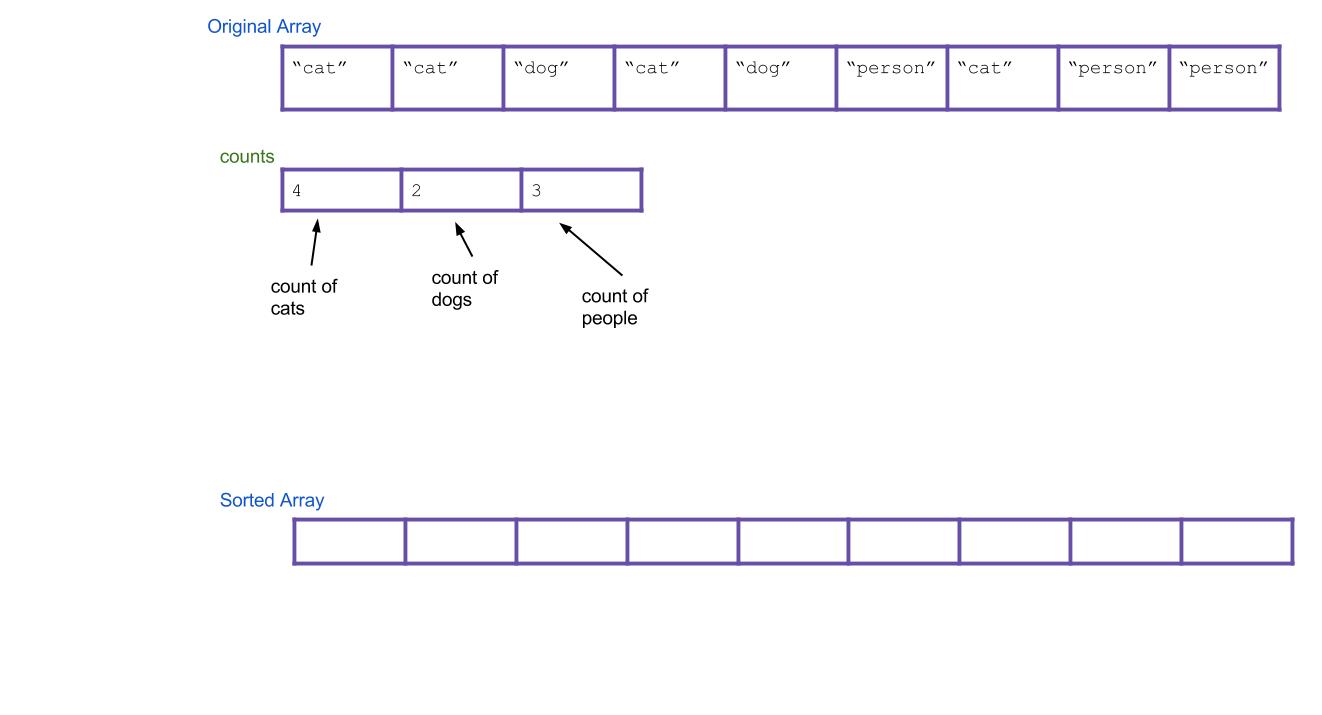
Think about it: based on your
countsarray, can you tell where the first dog would go in the new array? The first person? Create a new array, calledstarts, that holds this information. For our example, the result is: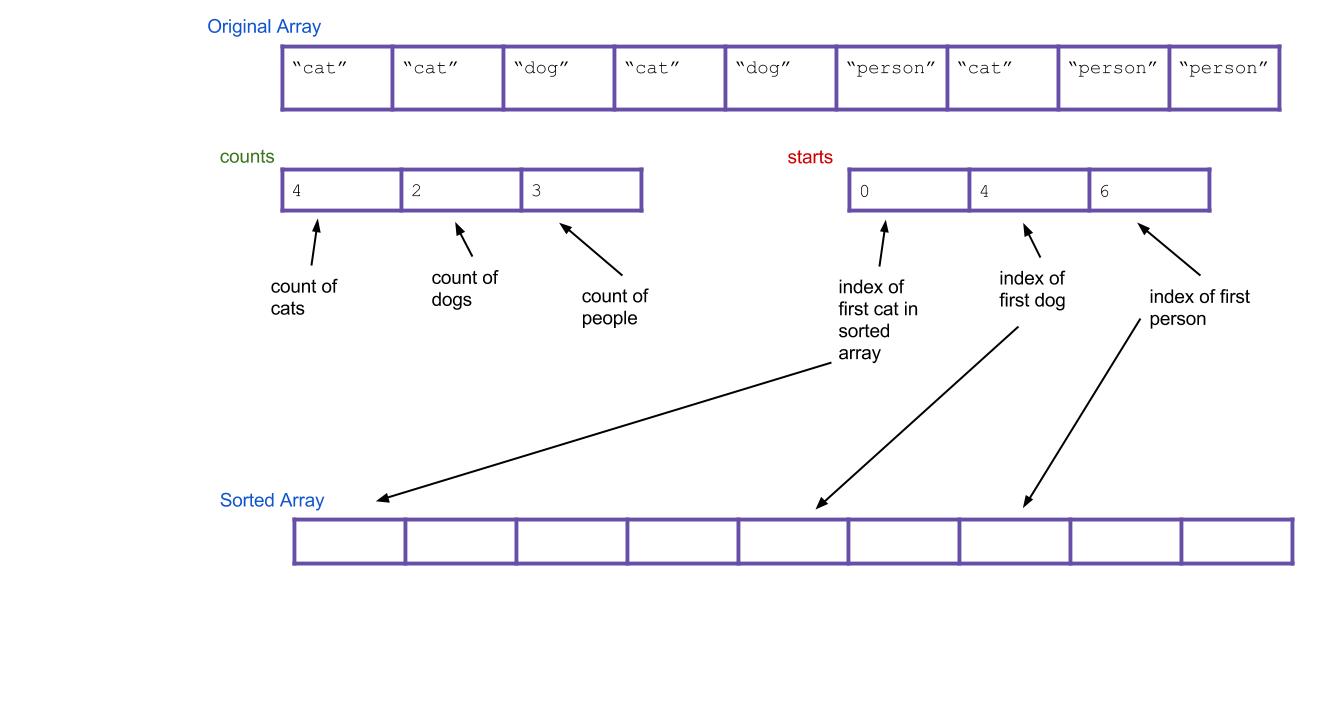
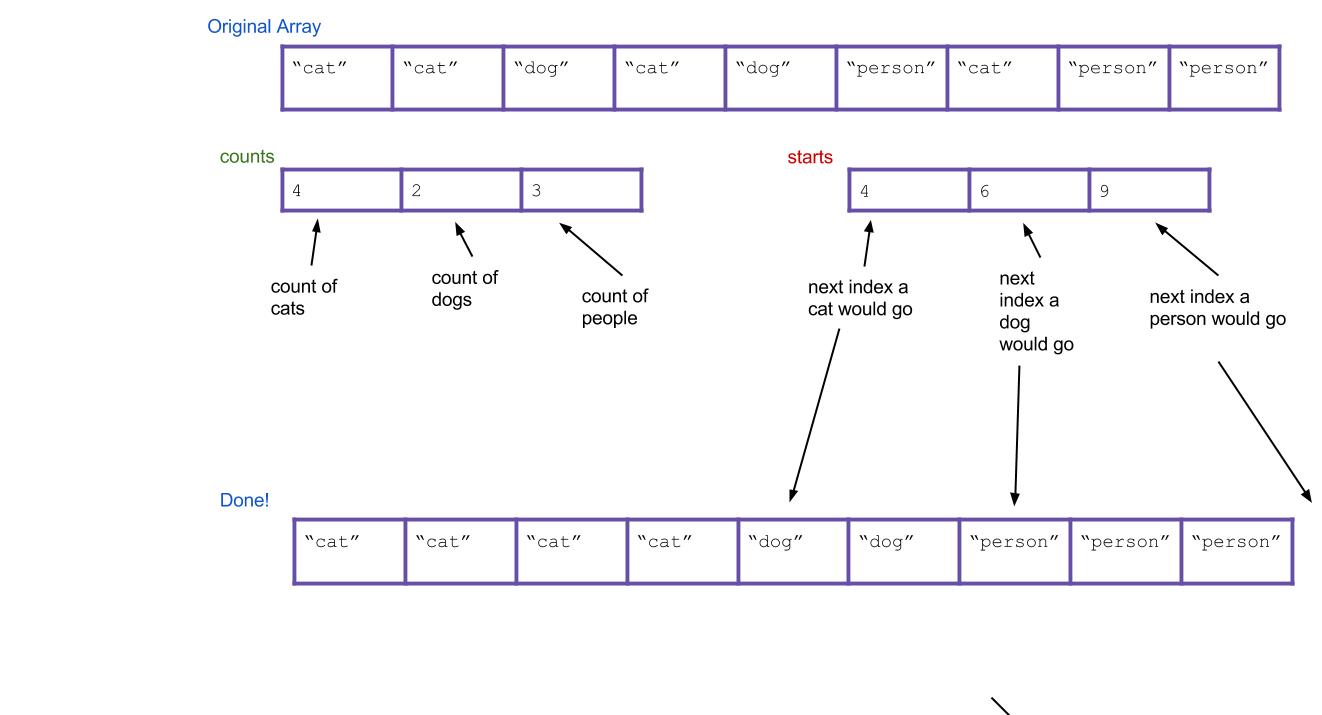
- Now iterate through all of your Strings, and put them into the right spot. When I find the first cat, it goes in
sorted[starts[0]]. When I find the first dog, it goes insorted[starts[1]]. What about when I find the second dog? It goes insorted[starts[1]+1], of course. Or, an alternative: I can just incrementstarts[1]every time I put a dog. Then the next dog will always go insorted[starts[1]].
Here's what everything would look like after completing the algorithm. Notice that the values of starts have been incremented along the way.
Does the written explanation of counting sort seem complicated? Here is a pretty cool animated version of it that might make it more intuitive.
Exercise: Code Counting Sort
Implement the countingSort method in DistributionSorts.java. Assume the only integers it will receive are 0, 1, 2, 3, 4, 5, 6, 7, 8, and 9.
The Runtime of Counting Sort
Inspect the counting sort method you just wrote? What is its runtime? Consider the following two variables: N: the number of items in the array, and K, the variety of possible items (in the code you wrote, K is the constant 10, but treat it as a variable for this question).
|
N
|
Incorrect. Your code should have a loop over K at some point, adding in a factor of K somewhere.
|
|
|
N*K
|
Incorrect. Your code should not involve a loop over K nested in a loop over N, so you shouldn't get a multiplicative factor.
|
|
|
N^2*K
|
Incorrect. Although your code has loops over N and K, they shouldn't be nested, so you shouldn't get multiplicative factors.
|
|
|
N + K
|
Correct! Your code should have sequential loops over N and K, but NOT nested loops. This means the runtimes of the loops add rather than muliply.
|
|
|
N^2 + K
|
Incorrect. Although your code has two loops over N, they shouldn't be nested, so you shouldn't get a squared factor.
|
Wow, look at that runtime! Does this mean counting sort is a strict improvement to Quicksort? Nope! Counting sort has two major weaknesses:
- It can only be used to sort discrete values.
- It will fail if K is too large, because creating the intermediate
countsarray (of size K) will be too slow.
The latter point turns out to be a fatal weakness for counting sort. The range of all possible integers in Java is just too large for counting sort to be practical in general circumstances.
Suddenly, counting sort seems completely useless. Forget about it for now! The next portion of the lab will talk about something completely different. But counting sort will reappear once again when you least expect it...
C. Sorting with Multiple Keys
Sorting with Multiple Keys
So far, we've been concerned with structuring or sorting using only a single set of keys. Much more common is the situation where a key has multiple components, and we'd like the keys to be sorted using any of those components.
An example is the collection of files in a UNIX directory. The command
lslists the files sorted by name. The command
ls -slists the files sorted by size.
ls -tlists the files sorted by the time of the last modification.
Sorting with Multiple Keys - An Example
Consider the following example, that represents a flat (nonhierarchical) directory of file entries.
public class Directory {
private FileEntry [ ] myFiles;
private class FileEntry {
public String myName;
public int mySize;
public GregorianDate myLastModifDate;
...
}
public void listByName ( ) ...
public void listBySize ( ) ...
public void listByLastModifDate ( ) ...
public void add (FileEntry f) ...
public void remove (FileEntry f) ...
}How would you sort the myFiles array by name? One option is to write a Quicksort method to do it. But let's stop and instead take advantage of Java's existing Arrays.sort() method, which sorts arrays, conveniently enough.
Arrays.sort(myFiles)Done! Right? Wrong. Arrays.sort requires you to pass in an array of Comparable objects, of course, or else it won't know how to sort them! So we could make FileEntry implement Comparable<FileEntry> and add the following method:
public int compareTo(FileEntry f) {
return myName.compareTo(f.myName);
}And now Arrays.sort(myFiles) would correctly sort by name. But now we have a new problem. How do we sort by size instead? We can't have FileEntry implement two kinds of Comparable. The solution is to introduce an auxiliary object called a comparator which is reponsible for ordering the objects. It's probably just easiest to show you how it works. We create the following classes:
public class FileSizeComparator implements Comparator<FileEntry> {
@Override
public int compare(FileEntry f1, FileEntry f2) {
if (f1.mySize < f2.mySize) {
return -1;
} else if (f1.mySize > f2.mySize) {
return 1;
} else {
return 0;
}
public class FileNameComparator implements Comparator<FileEntry> {
@Override
public int compare(FileEntry f1, FileEntry f2) {
return f1.myName.compareTo(f2.myName);
}
}And now we can sort FileEntrys either way by passing in whichever we want.
Arrays.sort(myFiles, new FileSizeComparator()); // sorts by size
Arrays.sort(myFiles, new FileNameComparator()); // sorts by nameCool, huh?
Self-test: Sorting by All Keys at Once
Suppose I wanted to sort my files by all all three qualities at once, with size taking precedence over time taking precedence over name. In other words, I want to sort my files by size, but among files that are the same size, I sort them by time. And among files that are the same size and the same time, I sort them by name. How could you do this?
|
Create a new Comparator that considers all three qualities.
|
Correct? This can work, but that comparator could be complicated. There's another solution we were looking for!
|
|
|
First sort the files by size, then sort them again by time, and lastly by name.
|
Incorrect. The later sorts will ruin the ordering created by the first sort, which is the one we are considering the most important.
|
|
|
First sort the files by name, then sort them again by time, then sort them again by size.
|
Correct! But there's one caveat: this requires the sorts be
stable
. (More on that in the next section!)
|
|
|
First sort the files by size. Split the array into groups based on files with the same size.
Within each group
, sort them by time. Then split those groups further based on files with the same time, and within the resulting groups, sort them by name. Finally concatenate all the of the groups back together, making sure not to reorder the groups relative to each other.
|
Correct!
|
|
|
First sort the files by name. Split the array into groups based on files with the same name.
Within each group
, sort them by time. Then split those groups further based on files with the same time, and within the resulting groups, sort them by size. Finally concatenate all the of the groups back together, making sure not to reorder the groups relative to each other.
|
Incorrect. This will result in name taking precedence, because the groups created from sorting by name are never reordered.
|
Maintaining Multiple Sorts
Take another look at the Directory class above. Let's think about how to code the three listBy... methods. One strategy is simply to have one copy of the directory's file entries—the myFiles array—and to sort the file entries in the array into an appropriate sequence at every time we call listBy.... The figure below shows an example of this approach.

Another way, which trades memory efficiency for time efficiency in the case where the directory doesn't change very often, is to maintain a separate array for each list order, as shown below.

Those of you with experience using data base programs may recognize this technique. Each entry in the data base typically contains a bunch of fields, and the data base program maintains index arrays that allow the entries to be listed by one field or another.
Discussion: Implementing the "add" Method
Link to the discussion
Briefly explain how to implement the add method in the directory class above. i.e. assuming the directory has three arrays:
myFilesByName
,
myFilesBySize
, and
myFilesByDate
as just described, what needs to happen when adding in one new file?
Now you know how to sort objects with multiple keys! Awesome! Now forget about it. The next portion of the lab will talk about something different. But sorting with multiple keys will also return when you least expect it...
D. Stability
Stable Sorting
A sorting method is referred to as stable if it maintains the relative order of entries with equal keys. Consider, for example, the following set of file entries:
data.txt 10003 Sept 7, 2005
hw2.java 1596 Sept 5, 2005
hw2.class 4100 Sept 5, 2005Suppose these entries were to be sorted by date. The entries for hw2.java and hw2.class have the same date; a stable sorting method would keep hw2.java before hw2.class in the resulting ordering, while an unstable sorting method might switch them.
A stable sort will always keep the equivalent elements in the original order, even if you sort it multiple times.
Discussion: Importance of Stability
Link to the discussionWe described one reason why stability was important: it could help us with the multiple-key sorting example. Can you think of another reason why stability might be important? Describe an application where it matters if the sorting method used is stable.
Exercise: Instability of Selection Sort
In UnstableSelectionSort.java you'll find — surprise — an unstable version of selection sort. Verify this fact, and implement a small change in the code that makes the method stable.
Quicksort: A Sad Story
Quicksort in its fastest form on arrays is not stable. Aside from its worst case runtime, this is Quicksort's major weakness, and the reason why some version of merge sort is often preferred.
(The Quicksort you implemented on a linked list is stable, though!)
E. Radix Sort
Linear Time Sorting with Distribution Sorts
Aside from counting sort, all the sorting methods we've seen so far are comparison-based, that is, they use comparisons to determine whether two elements are out of order. One can prove that any comparison-based sort needs at least O(N log N) comparisons to sort N elements. However, there are sorting methods that don't depend on comparisons that allow sorting of N elements in time proportional to N. Counting sort was one, but turned out to be impractical.
However, we now have all the ingredients necessary to describe radix sort, another linear-time non-comparison sort that can be practical.
Radix Sort
The radix of a number system is the number of values a single digit can take on. Binary numbers form a radix-2 system; decimal notation is radix-10. Any radix sort examines elements in passes, one pass for (say) the rightmost digit, one for the next-to-rightmost digit, and so on.
We'll now describe radix sort in detail. We actually already secretly described radix sort when talking about sorting files with multiple keys. In radix sort, we pretend each digit is a separate key, and then we just sort on all the keys at once, with the higher digits taking precedence over the lower ones.
Remember how to sort on multiple keys at once? There were two good strategies:
- First sort everything on the least important key. Then sort everything on the next key. Continue, until you reach the highest key. This strategy requires the sorts to be stable.
- First sort everything on the high key. Group all the items with the same high key into buckets. Recursively radix sort each bucket on the next highest key. Concatenate your buckets back together.
Here's an example of using the first strategy. Imagine we have the following numbers we wish to sort:
356, 112, 904, 294, 209, 820, 394, 810
First we sort them by the first digit:
820, 810, 112, 904, 294, 394, 356, 209
Then we sort them by the second digit, keeping numbers with the same second digit in their order from the previous step:
904, 209, 810, 112, 820, 356, 294, 394
Finally, we sort by the third digit, keeping numbers with the same third digit in their order from the previous step:
112, 209, 294, 356, 394, 810, 820, 904
All done!
Hopefully it's not hard to see how these can be extended to more than three digits. The first strategy is known as LSD radix sort, and the second strategy is called MSD radix sort. LSD and MSD stand for least significant digit and most significant digit respectively, reflecting the order in which the digits are considered. Here's some pseudocode for the first strategy:
public static void LSDRadixSort(int[] arr) {
for (int d = 0; d < numDigitsInAnInteger; d++) {
stableSortOnDigit(arr, d);
}
}(the 0 digit is the smallest digit, or the one furthest to the right in the number)
Radix Sort's Helper Method
Notice that both LSD and MSD radix sort call another sort as a helper method (in LSD's case, it must be a stable sort). Which sort should we use for this helper method? Insertion sort? Merge sort? Those would work. However, notice one key property of this helper sort: It only sorts based on a single digit. And a single digit can only take 10 possible values (for base-10 systems). This means we're doing a sort where the variety of things to sort is small. Do we know a sort that's good for this? It's counting sort!
So, counting sort turns out to be useful as a helper method to radix sort.
Exercise: Your Own MSD Radix Sort
First, if you haven't recently switched which partner is coding for this lab, do so now.
Now that you've learned what radix sort is, it's time to try it out yourself. Complete the MSDRadixSort method in DistributionSorts.java. You won't be able to reuse your counting sort from before verbatim, because you need a method to do counting sort only considering one digit, but you will be able to use something very similar.
In MSD radix sort, there is a step where you recursively radix sort each bucket of items that have the same digit. You can accomplish this recursion without needing to split up the array into new, separate, smaller arrays. Instead, each bucket of the array will just be a portion of the array known to be between two given indices. To make recursive calls, make recusive calls that only sort the array between the indices that are the boundaries of the bucket. You can see the skeleton for this in the code we gave you.
Disclaimer: Radix sort is commonly implemented at a lower level than base-10, such as with with bits (base-2) or bytes. You should do yours in base-10, however, because these types of numbers should be more familiar to you, since we didn't teach you about bits in this class.
Runtime of LSD Radix Sort
To analyze the runtime of radix sort, examine the pseudocode given for LSD radix sort. From this, we can tell that its runtime is proportional to numDigitsInAnInteger * the runtime of stableSortOnDigit.
Let's call numDigitsInAnInteger the variable D, which is the max number of digits that an integer in our input array has. Next, remember that we decided stableSortOnDigit is really counting sort, which has runtime proportional to N + K, where K is the number of possible digits, in this case 10. This means the total runtime of LSD radix sort is O(D * (N + K)). Since K is a clearly bounded constant, often this is just written O(D * N).
Discussion: Runtime of MSD Radix Sort
Link to the discussionWhat is the runtime for MSD radix sort? How does it differ from LSD?
Hint: Unlike LSD radix sort, it will be important to distinguish best-case and worst-case runtimes for MSD.
Radix Sort: The Great Anticlimax
With radix sort, we have found a sorting alrogithm that runs in time linear with the number of items we are sorting! It runs in O(N * D) time, instead of O(N log N), like merge sort.
So why don't we use radix sort all the time? Two problems:
- Not everything can be broken down into digits easily. Numbers and Strings can, but maybe not more complicated types of objects.
- Unless N is very very large, D is often larger than log N, or comparable to it. This means that O(N * D) may be worse than O(N log N), or not significantly better. How anticlimactic!
F. Conclusion
Summary
We hoped you enjoyed learning about sorting! Remember, if you ever need to sort something in your own code, you should take advantage of your language's existing sort methods. In Java, this is Arrays.sort for sorting arrays, and Collections.sort for sorting other kinds of things. You shouldn't really attempt to write your own sorting methods, unless you have a highly specialized application!
The reason we teach you about sorting is so that you have an understanding of what goes on behind the scenes, and also to give you a sense of the different trade-offs involved in algorithm design. What was important was the thought-process behind evaluating scenarios in which the different algorithms show advantages or disadvantages over each other.
Submission
As lab23, please turn in UnstableSelectionSort.java and DistributionSorts.java. This is your last required lab for the class. We hope you enjoyed 61BL!
Finally, please fill out this self-reflection form before this lab is due, as a part of your homework assignment. Self-reflection forms are to be completed individually, not in partnership.