61Ccc Parsing
Deadline: February 16th
Hello again! Let’s get going on part two!
This part is intentionally less scaffolded than 1-1. By now you should be comfortable writing unit and integration tests and have a decent exposure to C through labs and part one of this project. You are expected to read the entire spec before starting the project. We will not answer questions about content that can be found in the spec unless you are asking for clarification. Piazza is our official source of communication for this course and we will expect you to check piazza regularly for updates about the project.
Objectives
-
TSWBAT describe how 61Ccc files are processed by the parser.
-
TSW understand how to allocate and free memory for hierarchical data structures
-
TSWBAT identify statements with a subset of parsing errors and add error handling functionality
-
TSW correctly implement binary operator precedence within the parser.
Getting Started
Accept the github classroom assignment at this link. You’ll want to clone your repository on the hive machines (make sure you don’t clone it in an already-existing git repository; we suggest cloning into your home directory).
You’ll also want to add the staff remote so you can pull changes to the starter code. You can do that with the following command.
git remote add staff https://github.com/61c-teach/sp19-proj1-2-starter
To pull changes, run:
git pull staff master
Autograding and Testing
We have provided the same sample integration test for the parser as we did for the lexer; you can find it in /tests/parser/sample-tests. Though we don’t have any (formal) testing requirements for this portion, it is expected that you will continue to write unit tests and integration tests throughout this project and throughout the course. Your tests should be formatted the same as the tests you wrote in the lexer portion.
This project has an autograder posted on gradescope. Note, there are at least twice as many tests with which we will test your project. The grade you receive from the autograder is not guaranteed to be your final score.
Again, we highly recommend you write your own tests. We will not be providing an oracle or diff-checker for your tests. Instead, we’ve made an assignment on gradescope called ‘Test Error Checking’. You may submit your own tests here and the grader will tell you if your test should produce some output (output expected) or error (error expected).
This assignment will give you a grade, though testing (and passing) will not contribute to your overall project score in any way. In order to submit, you should place your tests in a folder called ‘tests’ and zip it. Submit the zip file to gradescope.
If you are not familiar with our office hours policy, we recommend you review it and the role testing plays in getting instructor assistance. Testing is an important part of software development, and we hope you’ll view this less as ‘something annoying you have to do’ and more as an opportunity to improve your (valuable) testing skills.
See the appendix for an explanation of our testing outputs.
ACTION ITEM: continue testing! :<)
Creating the AST
Much of the parser code you’ll interact with revolves around creating the object we’d like to return; the AST or abstract syntax tree. While our internal parsing functions should modify the structure, we’ll need some boilerplate functions to create a new AST and delete an existing AST. You’ll implement these functions first. See descriptions of them below.
Our AST is defined similarly to the tree structures you may have seen in CS61B with the exception that there is no invariant on the number of children per node (ie. we are not enforcing a binary or ternary tree). Furthermore, ASTs are a recursive structure; the children of an AST node are also ASTs. See the following image for clarification. You can find more information about the contents of each AST node in the appendix.
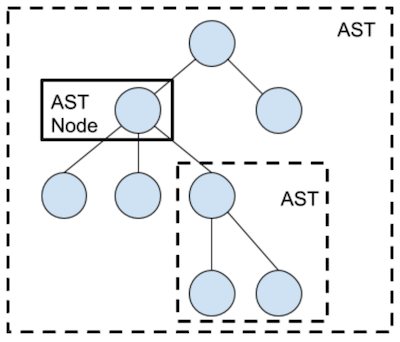
ACTION ITEM: Add support for the following:
-
MakeAST: Creates a new AST from a given type filename and linenum. You should not assume that filename will remain a legal pointer after this function terminates. Look at ast.h to understand what fields an AST struct contains. -
AppendAST: Takes in two ASTs (tree, node) and concatenates the two by making node a child of tree. -
FreeAST: Frees all the memory allocated by an AST (you may find the following method helpful) -
FreeNode: Frees the memory allocated by a single AST node.
After completing this portion you should be able to run tests that parse 61Ccc code without parser errors (for example: sample.61c). The ASTs produced for binary expressions will not work as expected, ie. the precedence will be incorrect. If you have not modified the return value from BinaryExprs from BaseExpr, they will not work at all. You’ll work on this in the next section.
Precedence
One of the most important tasks of a parser is enforcing operator precedence (remember PEMDAS?). You can learn more about C’s operator precedence here. Note that there are four different versions of associativity: L-L, L-R, R-R, R-L. Morgan and Nick did not correctly understand associativity, and as a result, BinaryExprs have incorrect precedence! They’d like you to fix it :)
For more information on how precedence is decided and how it relates to the structure of the AST, check out the appendix!
ACTION ITEM:
-
Fix the precedence code in
GetNextBinaryExprandBinaryExpr. Note that our language should match the C precedence rules described at the link above.GetNextBinaryExprshould be used to introduce the precedence across levels. For each Binary Expression type you will want to make sure that groups with higher levels of precedence bind more strongly. Logical Or has the lowest precedence so all binary expressions begin by checking if they are a logical or. After finishing this you will not be able to have multiple operators in the same precedence level in 1 expression but you should be able to correctly evaluate precedence across multiple levels. Note the default code withBaseExpris not correct and you should check the link above to see what to transition to for the highest precedence binary expresssion.BinaryExpris used to both allow for multiple calls to the same precedence level operators and to make sure it has the proper associativity.
After completing this portion you should be able to run tests that parse 61Ccc code without parser errors (for example: sample.61c). The ASTs produced for binary expressions should be correctly formatted as described in the precedence section of the appendix. In the next section you’ll work on correctly generating errors for ill-formatted 61Ccc code.
Error Handling
After parsing, there are three errors remaining that could exist in our code1, these are continue statements outside of for loops, break statements outside of for loops, and functions that do not always end in a return. You will implement the functionality of scanning the AST for any of these cases (as well as any error nodes) by completing CheckImproperStatements. Here’s some hints on what to consider for each error:
-
Break,Continue: these errors only occur if the statement is seen outside of the context of a for loop. Luckily we have a parameter ‘is_for’ which is true (nonzero) when we’re inside a for loop and false (0) otherwise. What could this be used for..? -
Returnchecking: Checking if a function returns is complicated by if statements. For a function to always return as a result of an if statement both an if and an else must always return. If there are no conditionals, you just have to check if a single return statement is present. Remember you can check ‘type’ to see what kind of node you have!
ACTION ITEM:
- Fix the errors described above by modifying
CheckImproperStatements. - We do not care about the messages you print to stderr/stdout; we will only be checking that you properly return a non-zero value for cases that should produce an error.
After completing this portion you should be able to run all tests that parse 61Ccc code (ie. both sample.61c and bad.61c). The ASTs produced for binary expressions should be correctly formatted as described in the precedence section of the appendix. Your code should pass any set of randomly given tests on the autograder.
Congrats! You’ve finished part two!
Appendix - Project 1-2
How to Test and Debug
You may create your own 61Ccc test files and place them in the tests/parser directory. To run a test, execute the following command which will lex and parse your input file. If you’d like to check for memory leaks, you can append valgrind to the beginning of this command:
./61Ccc -p tests/parser/your-file.61c
If you’d like to use CGDB to step through a test you’ve written, you may use the following commands from your terminal:
make clean
make
cgdb 61Ccc
Once inside your gdb prompt, you can break at a line number (ex. 19) and run your test with:
(gdb) b parser.c:19
(gdb) r -p tests/parser/your-file.61c
The parser will print out a readable AST (abstract syntax tree) after processing your test.

The first node of our AST should always be our GLOBAL node. It will contain information about the filename and our initial line numbering.
Nodes which are one indentation in from our GLOBAL node are its children. Nodes at the same indentation level are siblings. Here, you can see our GLOBAL node has one direct child, the VAR_DECL_LIST node. The VAR_DECL node, on the other hand, has four direct children. You can read more about the AST nodes and their attributes below, including which nodes are valid children of other nodes and how the tree should be organised. The image below represents the output in a more canonical tree form.
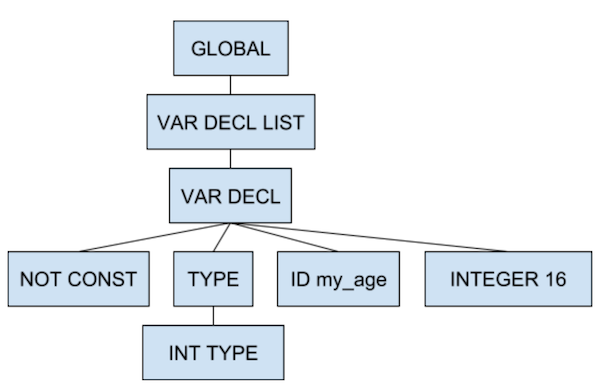
AST Node List
So what actually is an AST? In simple terms an AST holds information about the structure of the whole program and each node refers to the presence of some component of the file. For example the presence of an IF_ELSE Node indicates a point in the program that has begun an If statement and then its children will hold relevant information about the contents of that if statment (for example the condition that will be evaulated).
In addition to the parent-child relationships mentioned above, each AST node has some additional information regarding node type and file name. There are also rules that dictate how each tree is constructed which are shown in detail in Table 1. Crucially the starter code assumes that all ASTs follow the constructions given below even in the presence of errors. If any error occurs, the node’s number of children should remain the same (or satisfy the minimum) and at least one of the children must be an error node (otherwise the entire node should be replaced with an error node).
As an example let’s look at the IF_ELSE Node. It’s displayed in the table like this:

Under the “Node Name” column you can find the the NodeType (found in ast.h) that will be used to create this AST element. “Number of Children” is how many children the node should have. Some nodes, like the one above, have a range of children instead of a single value. This node, for example can have either 2 or 3 children depending on if there is an associated else. The minimum is the number of required children and the maximum is the most children its allowed to have (even with errors it cannot exceed this amount). The “Children” column indicates which node or group of nodes (nodes are sectioned by groups in the table) each child can take, zero index, with a brief comment describing them. Any children that exceed the minimum number of children are optional. Finally “Parent” indicates which nodes or group of nodes this node can have as a parent (be a child of).
You can view the rest of the table here.
Note: We are not expecting you to understand the entire table; it should be used as a reference when debugging the precedence section.
Precedence
Like we said before, the parser has an important role in enforcing precedence. Precedence is enforced by making sure our AST nodes have correct parent-child relationships. Take, for example, the following two trees. Both outline the same expression, but the first requires we evaluate multiplication before addition (result: 17) and the second evaluates addition before multiplication (result: 20)
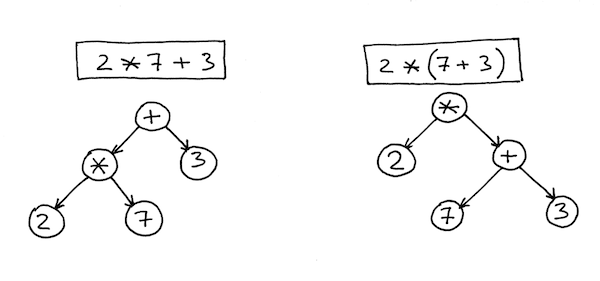
Note expressions are evaluated from the bottom of the tree towards the root.
As you likely remember from learning order-of-operations in math, we’d like our parser to generate the first tree rather than the second. The only case in which we should get the second tree is if we use parentheses (as above) to force the precedence to be different than it would be regularly.
Handling Errors
When parsing, you may come across input tokens that do not match any our allowed expressions, or you may find we run out of tokens while parsing. In both cases, we will produce an error node in our AST and output an error message. The presence of any error tokens in the final AST indicates that parsing was not successful and produces a non-zero exit code.
As mentioned in Project 1-1, it is our goal to display the maximum number of errors when multiple errors are encountered. This is not necessarily always possible. When a token does not match the expected token we step up the AST until we reach either a block, global statement or struct definition. Then we consume tokens without trying to complete a rule until we see either a ‘}’ or ‘;’ (to try and limit cascading incorrect errors). In the following example, the red code represents what we’d catch as an error, and the AST is created likewise.

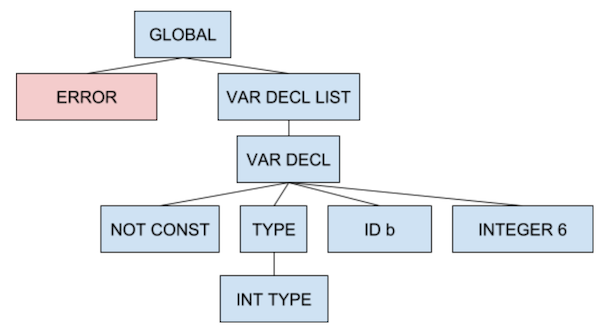
Sometimes the error message will not properly guess the exact change required. Do not concern yourself with the output message and instead focus on if errors are being generated or not.
There are three errors you’ll need to pay close attention to1 these are continue statements outside of for loops, break statements outside of for loops, and functions that do not always end in a return. You will implement the functionality of scanning the AST for any of these cases (as well as any error nodes) by completing CheckImproperStatements. To assist with this task we introduce one more assumption, that all AST nodes will be well formed, meaning that every node will have a number of children matches the number listed in the node list below. To do this we will potentially more than 1 error node in the event of an error and if there is no room for more children will return an error node instead of the AST Node we were building.
Language Features
Our language is mostly a subset of the C language with a few key differences. Traditionally the exact contents of what is allowed in a language is given by a grammar for that language. However we do not want to burden you with having to understand how to read or interpret a grammar and if we gave you a completely correct grammar it would make implementing operator precedence trivial. Instead here we will give you the majority of what is allowed in the language for what you will need to write tests. There may be some other small features that we allow but you should not concern yourself with these are they are not important to this project. If you have any questions about our test files remember you are free to submit to our test autograder to determine if a file can be properly parsed.
Now we are going to highlight what is allowed in each region of the program and provide an example:
Global Elements
Global elements are portion of code outside of any functions. The allowed global statements are:
-
Variable Declarations
Example:
int a, b; -
Variable Declarations with initialization
Example:
int a = EXPR; -
Struct Definitions
Example:
struct nsa { ... }; -
Function Declarations
Example:
int f (int y); -
Function Defintions
Example:
int f (int y) { ... }
Struct Elements
Struct Elements are the language features that can reside inside a struct. The allowed struct element are:
-
Variable Declarations
Example:
int *a, **b;
Function Elements
Function Elements are the elements that can go inside a struct. These elements are:
-
IF ELSE Statements
Example:
if (x) { ... } else { ... } -
For Loops
Example:
for (i = 0; i < n;) { ... } -
Break Statements
Example:
break; -
Continue Statements
Example:
continue; -
Return Statements
Example:
return EXPR; -
Variable Declarations
Example:
char a; -
Variable Declarations with initialization
Example:
char a = EXPR, b = EXPR; -
EXPR (See Below)
Example:
5;
Types
Our language allows for the following types:
- char
- int
- bool
- struct ID
- Pointers to any of the 4 other types
Note that because we do not have a type def you cannot use anything that does not match one of these 5 as a type. Use of a random identifier will result in an error in parsing.
Expr
An Expr is our general blanket statement for expressions. There are many different possible expressions and they can be linked together. The important groups of Expressions are:
-
Assignment Statements:
Example:
ID = EXPR -
Parenthesized Expresions
Example:
( EXPR ) -
Binary Expressions (See Below)
Example:
EXPR + EXPR -
Prefix Expressions (See Below)
Example:
++i -
Postfix Expressions (See Below)
Example:
i-- -
Identifiers (ID)
Example:
x -
Literals
Example:
NULL
Binary Expressions
All binary Expressions are of the form EXPR OPERATOR EXPR, where the acceptable OPERATOR choices are: +, -, *, \, >, >=, <, <=, ==, !=, |, &, ^, ||, &&. Keep in mind you can nest these expressions so you are tasked with ensuring they perform the correct operator precedence.
Prefix Expressions
All Prefix Expressions are of the form OPERATOR EXPR, where the acceptable OPERATOR choices are &, *, ( TYPE ), ++, --, -. Their precedence is handled for you.
Postfix Expressions
Postfix expressions have two forms. The first is EXPR OPERATOR, where the acceptable OPERATOR choices are ++, --. The second is EXPR OPERATOR ID, where the acceptable OPERATOR choices are -> and .. For both of these precedence is handled for you.
Notable Differences from C
There are a few notable difference from C in our language that we think you might want to be aware of. There are also other differences but these are less important so we will omit them.
If Statements
All If and Else groups must use braces. This means the following legal pieces of c code are not legal.
if (x) return 0;
if (x) { ... } else if (y) { ... }
For Loops
You may not declare variables inside the header of a for loop and we also require braces. This means the following legal pieces of c99 code are not legal.
for (int i = 0; i < 10; i++) { ...}
for (i = 0;;i++) i;
Function Declarations
All function declarations must have named parameters. This means the following piece of legal c code is not legal.
int f (int);
Debugging your test files
If a test errors that you did not expect try fixing the very first error output. Unfortunately our backtracking mechanism is far from perfect so you should not rely on it to be consistent throughout the whole file. Another piece of advice is to keep your tests small. Smaller tests means you are likely to have fewer errors. Finally to create error tests try and do things you know are illegal in C, such as int;. Keep in mind that no type checking is done at this stage so type mismatches will not produce errors.
-
In reality there are more than three errors our code could contain. Most of them are resolved by the strictness of our grammar, the specifications by which we determine if a program has a valid arrangement of tokens or not. We have a grammar written up, however the grammar makes solving the precedence problem trivial, so we’ve elected to not distribute it to you. If you’re interested in seeing what it looks like, we’ll be happy to post it after the project deadline has passed. If our grammar was stricter, we could’ve prevented the need for additional handling for continue/break statements. ↩ ↩2