Project 4: Caches
Created By: Nicholas J Riasanovsky, Zubair Marediya
Due Date: Monday, 08/07/17 @ 23:59:59

Updates
| Date | Time | Description |
|---|---|---|
| 08/05/17 | 03:30 PM | Code Update: N is now uint32_t instead of uint8_t. Special merge instructions. |
| 08/04/17 | 05:30 PM | Spec Update: Bit location is left to right, 0 to 7. Independent of endianness. |
| 08/04/17 | 03:30 AM | Spec Update: Improved directions for Part 2 Problem 2. |
| 08/04/17 | 03:30 AM | Spec Update: resetDirty and setInvalid don't exist. |
| 08/03/17 | 6:00 PM | Code Update: Fixed a typo in the Part 3 snoopbucket struct. |
| 08/03/17 | 6:00 PM | Code Update: Improved comments for read functions. |
| 08/03/17 | 6:00 PM | Code Update: Fixed Makefile and CUnit to remove files not provided. |
| 08/03/17 | 1:30 AM | Code Update: Improved comment for findEviction. Added extra tests to help debug. |
| 08/01/17 | 11:20 PM | Code Update: Improving function comment for clearCache |
| 08/01/17 | 11:10 PM | Spec Update: Using clearCache in createCache |
| 07/31/17 | 9:05 PM | Project is released! |
To apply updates, please run the following commands:
git fetch su17-proj4-starter
git merge su17-proj4-starter/master -m "merge proj4 update"
Introduction
Theory
So far in this course, we have learned that going to and from physical memory is expensive. We introduced caches and how they speed up memory accesses by storing data closer to the CPU. From project 3, you saw your CPU spit out memory addresses to read and write to. What we didn't incorporate was the layer of cache(s) that sit in between the CPU and physical memory.
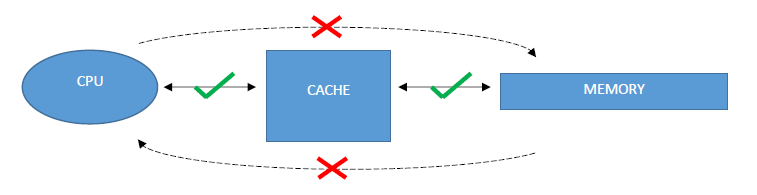
So, all your cache will be given is a 32 bit address. To understand how to make sense of these address bits, let's review some basics.When data is stored in a cache, it is stored in terms of blocks. Recall that a block is just a size of data, much like a byte, word, double word, etc. Typically, we define a block to be some number of bytes. Just how many bytes depends on the cache design. Within a block, we pick the data we want relative to the beginning of the block. This is called the offset. The offset tells us which byte to start grabbing data from, relative to the beginning of the byte addressed block. Some cache designs will group multiple blocks together. This is called a set. We denote N as the number of blocks within a set. Lastly, to distinguish the blocks within a set, each must have a unique identifier. The unique identifier is called the tag. From left to right, the tag, index, and offset bits are concatenated to form the 32 bit address that the CPU wants.
Direct Mapped
In a Direct Mapped cache, each block is a set. As we cycle through contingous addresses, they get mapped directly block to block, contigously. Because there is only one block in each set, the Tag, Index, Offset breakdown maximizes the number of Index bits. The number of Index bits will be log(M) where M is the number of blocks. One key issue with Direct Mapped caches is the ping pong effect. We often continuously evict blocks mapping to the same slot. Increasing the associativity (N) usually helps ease this issue.
Fully Associative
A Fully Associative cache is the opposite extreme of Direct Mapped. In this cache, there is only one set, composed of all blocks in our cache. Blocks can go anywhere in the cache since there's no idea of mapping anywhere. Because of this, finding a specific block in the cache can be more difficult since it could be anywhere. This lookup process requires extra hardware, making Fully Associative caches more expensive.
N-Way Set Associative
An N-Way Set Associative cache attempts to take the best of both worlds. We want to reduce the number of tag comparators from Fully Associative, but also reduce the ping ponging from Direct Mapped. So, this is where we really use the idea of sets. We partition our blocks into groups of N blocks, and call each a set. We directly map to a set, and then go fully associative within it. A direct mapped cache is an extreme of an N-Way Set Associative cache, with N = 1. Fully Associative caches can be viewed as an extreme of N-Way too. If M is the number of blocks in the cache, then N = M for a Fully Associative cache.
Project
In this project, you will implement a software version of a cache. There are three parts of this project. Part one will make you fill in helper methods to finish the functionality of the cache. Part two will have you answer exam level cache questions, trying to find cache parameters that give the optimal hit rate. You will also write a hit rate function to help you double check this. Part three will make you implement the MOESI protocol for cache coherence.
Let's first step through critical information on how our cache is designed. We will provide a cache struct that generalizes to the three cache types. You will need to specify the appropriate parameters, depending on which type you want.
Our cache will be a write back cache with an allocate on write miss policy. So, in addition to the tag, data, and LRU bits, our block will contain a valid and dirty bit. Lastly, our block will contain a shared bit. This will be used in the MOESI protocol for Part 3. So, as a recap, each block will contain (in this specific order) a valid bit, dirty bit, shared bit, LRU bits, tag bits, and data bits.
Furthermore, we can stack these blocks as rows in our cache. A set of N rows (blocks) will form a set. This visual is the one we abided by when designing the project. Be sure you fully understand it!
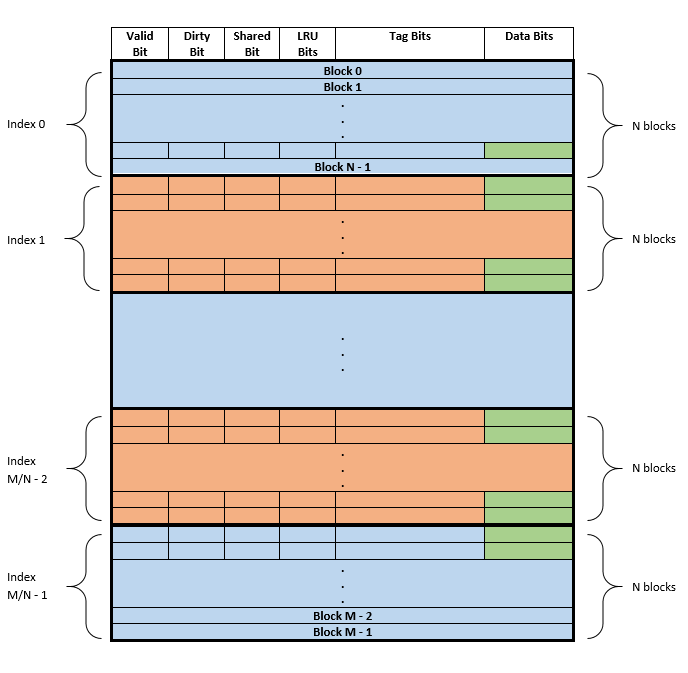
In this visual, there are M blocks with N blocks in a set. All the data in our cache is highlighted in green. The variable in the code that refers to the total size of this data is called totalDataSize. The variable that refers to how much data is in one block is called blockDataSize. You should see how totalDataSize = M * blockDataSize. We also enumerate our blocks from 0 to M-1 and call this variable the blockNumber.
To store all the contents of the cache, we use an array of unsigned bytes. By contents, we mean all the bits mentioned above, not just the data. As you might expect, the total number of bits in our cache isn't always a multiple of 8. This means that we may have anywhere from 0 to 7 extra bits in our array. We will store these bits at the beginning of our contents array, and refer to them as garbage bits. Our array will contain the content from the above diagram using row major order. Here is a visual of how the cache contents array looks:

Because we can only access our contents at the byte level, it's very probable that particular things we want from the cache may lie across multiple bytes. For example, we may have four LRU bits that span across two different bytes (at the end of the first, and the beginning of the second). Please keep this in mind when you deal with any bitwise manipulations.
Before getting into the code, here are some details you should know:
-
In the case a function can error, we will tell you what to return. If we do not state anything about it in the function comments, you can safely assume it won’t be error checked.
-
Don’t mess with any header files. We will only accept .c files.
-
All testing will be done on the Hive machines. You MUST check that your code runs and passes tests on there. Failure to do so may result in a low score.
-
You can write your own helper functions, but cannot modify the header files. This will require you to write your functions higher in the file than they are called.
-
Remember that when functions return pointers in C, it's safe practice to have that pointer point to data on the heap.
-
We will use Big Endian. So, if you load a word with 4 bytes, the most significant byte will have the lowest memory address.
-
The given tests are not comprehensive and you must have no memory leaks. We will check with Valgrind.
-
For each part of the project, be sure you read through an entire file before writing functions in it.
-
Your tests will segfault until you write the
createCachefunction in early Part 1. -
We are working with a 32 bit address space, however the range of addresses we will use is only 20 bits wide. It ranges from
0x61c00000to0x61cfffff. This is so that our physical memory files don’t get too large.
While we're at it, let's talk about "memory" and how it's simulated in this project. If you look at the dataSets directory in the root of this project folder, you will find files named physicalMemory*.txt. Go ahead and open one of these. You will see that it's a stream of bytes, each written as two nibbles. Each byte represents data at a byte address in memory. The first address is 0x61c00000. We have 2^20 bytes of data in each file, making the addresses range to 0x61cfffff. When we read from or write to memory, we will need to specify which physical memory file. However, the implementation for reading from and writing to memory has been taken care of for you. You are only responsible for understanding the code and how to use it. More on this will be mentioned below in Part 1.
Setup
We will be using Git and Bitbucket. First, go to Bitbucket and create a private repo with the title "proj4-XXX-YYY" where XXX is your login, and YYY is your partners. Only one of you should create this repo. Please give each other Admin access, and give the staff Admin access as well. You should review Lab 0 if you forgot how to do this. Once you have made this repo, cd to where you want your project to exist, and run the following commands. When doing so, please be sure to replace <YOUR BITBUCKET USERNAME>, XXX, and YYY with the appropriate information!
git clone https://<YOUR BITBUCKET USERNAME>@bitbucket.org/<YOUR BITBUCKET USERNAME>/proj4-XXX-YYY.git
cd proj4-XXX-YYY
git remote add su17-proj4-starter https://github.com/61c-teach/su17-proj4-starter.git
git fetch su17-proj4-starter
git merge su17-proj4-starter/master -m "merge proj4 skeleton code"
git push -u origin masterPart 1
Overview
In Part 1, you will fill in functions to make our cache fully functional. There are six files you should be familiar with. Don't worry, there's a lot of code, but we'll tackle it in pieces! The six files are: utils.c, getFromCache.c, setInCache.c, cacheRead.c, cacheWrite.c, and mem.c. Below is a short description of each file, and how you will interact with it:
utils.cThis file contains many of the utilities needed for your cache. You can find the cache struct along with other helpful structs in
utils.h. You may find theprintCachefunction particularly helpful in debugging. You may also find thelog_2andoneBitOnfunctions useful. Be sure you carefully read the function comments for proper use.getFromCache.cThis file contains helper functions to get useful information from the cache. You will write some of the functions in this file.
setInCache.cThis file contains helper functions to set useful information in the cache. You will write some of the functions in this file.
cacheRead.cThis file contains functions to read data from the cache. You will write functions to read different data sizes. Again, you may find the structs in
utils.hhelpful.cacheWrite.cThis file contains functions to write data to the cache. You will write functions to write different data sizes.
mem.cLastly, this file contains functions to read from and write to memory. You should NOT modify anything in this file, however please read and understand it.
WARNING: The subparts below build on the previous ones. Please approach them linearly and do not move forward until you have the current one working.
DEBUGGING TIPS: For Part 1, you will find the following commands helpful: make part1 and cgdb caches. The former will compile all necessary files, but won't run the executable. The latter will let you step through the executable in cgdb. You can use this to debug the individual subparts below.
Utility Functions
In this subpart you will fill functions in utils.c. You will write:
-
createCache -
deleteCache -
getIndex -
getOffset -
getNumSets -
getTagSize -
numLRUBits -
totalBlockBits -
cacheSizeBits -
getBlockStartBits -
getValidLocation -
getDirtyLocation -
getSharedLocation -
getLRULocation -
getTagLocation -
getDataLocation
The createCache function has been partially filled in for you. The function comments should give you enough guidance on what to fill in. Just a reminder that you need to error check for this function, and will find the oneBitOn function useful for that.
UPDATE: 08/01/17 11:10 PM
Remember when creating a new cache you should remember to invalidate every block and need all LRU values to be at a maximum. We provide the function clearCache in setInCache.c to help you do this. Though you haven't written this function yet (or maybe not even skimmed the file), go ahead and use the function assuming it works. You can fill it in later when you hit that part of the spec.
You may find implementing the getBlockStartBits function first helpful in implementing all the get*Location functions.
Keep in mind how we designed our blocks and how bits are assigned in them. You may find other given functions helpful, although not necessary. There are multiple ways to do these functions, so don't fret! You can test this part by running make test-part1-utils.
UPDATE: 08/04/17 05:30 PM
When looking at a byte, the bit locations start from 0 on the leftmost bit (MSB) to 7 on the rightmost bit (LSB). So if my location is 2, then I want the 3rd bit from left in the byte.
Getter Methods
In this subpart you will fill functions in getFromCache.c. You will write:
-
getValid -
getDirty -
getShared -
getBit -
getLRU -
extractAddress -
findEviction
If you understand the design of our block and cache well, then all these functions should be simple. You may find getBit helpful in writing getValid, getDirty, and getShared. You may find the given functions useful in seeing how we use bitwise operations.
For the extractAddress, the function comments should provide enough guidance. Essentially, you are given the TIO fields and asked to form the concatenated address depending on the cache parameters.
When implementing getLRU, remember that the bits may exist across different bytes. They may exist in one byte as well. Account for both cases!
Please read through all given functions as some may help with findEviction. You will also find the evictionInfo_t struct in utils.h helpful.
Again, there are multiple ways of doing these functions. This part cannot be tested individually as we rely on Setter Methods. You can successfully test it after finishing the next subpart.
Setter Methods
In this subpart you will fill functions in setInCache.c. You will write:
-
setValid -
setDirty -
setShared -
setBit -
setLRU -
clearCache
You may find writing setBit first helpful.
For setLRU, you may find that reading the given setData and setTag functions helpful. Also remember how you handled byte boundaries from getLRU, as that applies again.
When finished, run make test-part1-get-set and check that you pass the tests for both the getters and setters subparts.
Reading from the Cache
In this subpart you will fill functions in cacheRead.c. You will write:
-
readFromCache -
readByte -
readHalfWord -
readWord -
readDoubleWord
Reading through the given fetchBlock function may be helpful.
As you fill in these read functions, recall how a cache read works. Draw out the process and list all the steps. Use this as a guide to writing the different steps of each function. The functions should be very similiar as they only differ in the sizes of data they read. Again, you should review the structs in utils.h.
Here are some questions/thoughts to get you thinking: What happens when you miss in the cache? Where does the data have to come from? What fields need to be set and updated? Does any data need to be kicked out the cache? If so, does it need to be synced up with physical memory? Or is it just safe to overwrite the data?
As you draw out the steps for these functions, try modularizing your code with helper functions that have been given or written by you. Here are some functions you may need/find helpful (you may not need all of them, in fact you probably shouldn't use all of them):
-
validAddresses -
findEviction -
evict -
readFromMem -
setDirty -
resetDirty -
setTag -
getTag -
setData -
setValid -
setInvalid -
getData -
setLRU -
updateLRU
You may find the given getData function helpful in writing readFromCache. That in turn will help with the other four read functions.
Remember, when reading from a cache, the data you are looking for may or may not exist in the cache. You should handle both cases. Lastly, remember to free any pointers once you're done with them to avoid memory leaks down the road.
Lastly, there are some edge cases you should handle. What happens if you try to read a word, but your blockDataSize is only two bytes long? Generally speaking, what happens if you try to read data that's larger in size than your blockDataSize? We will handle this by making multiple cache accesses. So for the given example, you would want to handle your word read as multiple half word reads. You should handle the breakdown of reads into the fewest number of necessary cache accesses. Be sure you account for these cases in your read functions!
When finished, run make test-part1-read to run tests for this subpart.
Writing to the Cache
In this subpart you will fill functions in cacheWrite.c. You will write:
-
writeToCache -
writeByte -
writeHalfWord -
writeWord -
writeDoubleWord
The writeWholeBlock function will be used in Part 3. You should first read the given evict and writeDataToCache functions. Then you should write writeToCache and think of how you can use these two functions to help you. As you did with reading from the cache, consider the cases of when your data already exists in the cache vs. when it doesn't. Again, recall when data should and shouldn't be synced with physical memory. Once you finish writeToCache, use it to help write the remaining required functions.
Again, the same edge cases for writing exist as they did for reading. Namely, what happens if you try to write an amount of data that's larger than blockDataSize? You should handle this with the same logic as before.
When finished, run make test-part1-write to run tests for this subpart.
At this point, you should be passing all tests for Part 1 from make test-part1. You should check for memory leaks by running make part1-memCheck.
Part 2
Overview
In Part 2, you will track the number of hits and accesses a cache has in order to compute hit rates. You will also tackle exam level questions, trying to find some cache parameters that give the highest hit rate for the given scenarios.
In the first subpart, you will implement the functionality to compute hit rates. This will require adding a little code to some functions from Part 1. In the remaining subparts, you will be given a cache scenario as done for exam questions. We will give you at least one of the cache parameters. We will ask you to find the remaining cache parameters of the cache design that maximizes the hit rate.
The first subpart should not take you that long. It's very straightforward. The other subparts will require thought. We recommend you individually try solving the problems on paper. Then discuss with your partner and try converging to an answer.
We will be working with four new files. They are hitRate.c, problem1.c, problem2.c, and problem3.c. Below is a short description of each and its use to us:
hitRate.cThis file contains three functions you will write to compute hit rates.
problem1.c,problem2.c, andproblem3.cThese files contain one function each. The
params*function in each will have you return acache_tpointer with your desired cache parameters. Each file corresponds to the given subparts below.
DEBUGGING TIPS: You can run make part2 to compile your Part 2 code, but not run the executable. Then you can debug with cgdb caches.
TESTING NOTE: We have provided unit tests for the first subpart (Hit Rates). For the remaining subparts, you might notice that you pass the tests as long as your cache_t pointer isn't null. That means your cache parameters could be anything, yet you still pass the tests. This is because we have inserted dummy tests to check that you actually implemented the functions. All they do is check that you don't return null, which is initially returned. So, these tests do NOT verify that your parameters are correct. In fact, there are no "actual" unit tests for these subparts to prevent leaking the optimal parameters. So, work carefully for these subparts and only move forward when you're confident in your answers.
Hit Rates
In this subpart you will fill in functions in hitRate.c. You will write:
-
findHitRate -
reportAccess -
reportHit
Each of these functions are very short. Take a look at the cache_t struct again in utils.h. Each of these functions should not take more than a minute to code up. Otherwise you're overthinking it.
Once you write up these three functions, it's time to make use of them. When we access the cache, it's to read or write. In each access, we either hit or miss. Knowing that, go back to the appropriate functions from Part 1 and make slight modifications to call reportHit and reportAccess when appropriate. Injecting these calls shouldn't take much time if you have properly modularized your code according to the tips given for cacheRead.c and cacheWrite.c.
WARNING: Do not inject these calls in the fetchBlock function. That function is strictly used to fetch a block. It does not count as a read or write. You should only have to inject the calls in functions you have written.
When finished, run make test-part2 and check that you pass all the hit rate tests.
Problem 1
Below is the C code for the first cache question. Below it is the cache scenario. You will fill in your answers in the params1 function in the problem1.c file. Find the parameters we ask for, and create a cache with those parameters.
#define ARRAY_SIZE 256
uint64_t func1(uint16_t* A, uint16_t* B, uint32_t* C) {
uint32_t temp1;
uint32_t temp2;
uint64_t concatMax;
uint64_t tempMax;
for (int i = 0; i < ARRAY_SIZE; i++) {
if (i % 2 == 0) {
temp1 = A[i];
temp1 = (temp1 << 16) | B[i];
} else {
temp2 = A[i];
temp2 = (temp2 << 16) | B[i];
C[i / 2] = temp1 + temp2;
}
}
concatMax = 0;
for (int j = 0; j < ARRAY_SIZE / 4; j++) {
tempMax = C[2 * j];
tempMax = (tempMax << 32) | C[(2 * j) + 1];
concatMax = (tempMax > concatMax) ? tempMax : concatMax;
}
return concatMax;
}Assume that A exists at address 0x61c00400, B exists at address 0x61c60000, and C at address 0x61c00000. Suppose you are given a totalDataSize of 8192 bytes. What is the smallest value of blockDataSize that results in the highest hit rate? At that value, what is the smallest value of N that maintains this hit rate? Assume our cache is write back with write miss allocation.
Problem 2
The directions for this subpart are the same as the previous. You should instead write your answers in the params2 function in the problem2.c file.
#define SIZE 32768
typedef struct longArrayList {
uint32_t cap;
uint64_t* data;
} longArrayList_t;
longArrayList_t* createLongArrayList() {
longArrayList_t* lst = malloc(sizeof(longArrayList_t));
lst->cap = 8;
lst->data = malloc(sizeof(uint64_t) * 8);
return lst;
}
void addToArrayList(longArrayList_t* lst, uint32_t location, uint64_t data) {
if (location < lst->cap) {
lst->data[location] = data;
} else {
while(location >= lst->cap) {
lst->cap *= 2;
}
lst->data = realloc(lst->data, lst->cap * sizeof(uint64_t));
lst->data[location] = data;
}
}
uint64_t fetchItem(longArrayList_t* lst, uint32_t location) {
if (location >= lst->cap) {
return 0;
} else {
return lst->data[location];
}
}
void freeLongArrayList(longArrayList_t* lst) {
free(lst->data);
free(lst);
}
longArrayList_t* func3(uint64_t* array) {
longArrayList_t* lst = createLongArrayList();
for (uint32_t i = 0; i < SIZE; i++) {
addToArrayList(lst, i, array[i]);
}
return lst;
}
uint64_t func2(uint64_t* array) {
uint64_t sum = 0;
longArrayList_t* lst = func3(array);
for (uint32_t i = 0; i < SIZE * 2; i++) {
sum += fetchItem(lst, i);
}
free(lst);
return sum;
}Assume array is at address 0x61c00000, lst is malloced to take address 0x61c40040 and that its data is malloced to be at address 0x61c80040. Our blockDataSize is fixed to be 8 bytes.
Also assume that we are in a 32 bit address space and that no padding is needed for our struct. Further assume our malloc and free will not involve our cache. Also assume that realloc never moves our pointer. What is the smallest value of totalDataSize that results in the largest hit rate? For this totalDataSize, what is the smallest value of N at which this hit rate exists? The totalDataSize is also upper bounded by 2^14 bytes. This means the hit rate we calculate may not be the best hit rate we could get if we had a larger cache. Assume our cache is write back with write miss allocation.
UPDATE: 08/04/17 03:30 AM
The code is run by calling func2(array).
Problem 3
The directions for this subpart are the same as the previous. You should instead write your answers in the params3 function in the problem3.c file.
mipstery:
addu $t0, $0, $0
Loop1: slt $t3, $t0, $a3
beq $t3, $0, end
addu $t1, $0, $0
Loop2: slt $t3, $t1, $a3
beq $t3, $0, increment_i
addu $t2, $0, $0
Loop3: slt $t3, $t2, $a3
beq $t3, $0, increment_j
mult $a3, $t0
mflo $t3
addu $t3, $t1, $t3
sll $t3, $t3, 2
addu $t3, $t3, $a2
lw $t4, 0($t3)
mult $a3, $t0
mflo $t3
addu $t3, $t2, $t3
sll $t3, $t3, 2
addu $t3, $t3, $a0
lw $t5, 0($t3)
mult $a3, $t2
mflo $t3
addu $t3, $t1, $t3
sll $t3, $t3, 2
addu $t3, $t3, $a1
lw $t6, 0($t3)
mult $t5, $t6
mflo $t5
addu $t4, $t4, $t5
mult $a3, $t0
mflo $t3
addu $t3, $t1, $t3
sll $t3, $t3, 2
addu $t3, $t3, $a2
sw $t4, 0($t3)
increment_k: addiu $t2, $t2, 1
j Loop3
increment_j: addiu $t1, $t1, 1
j Loop2
increment_i: addiu $t0, $t0, 1
j Loop1
end: jr $raTake a look at this mipserable function. It takes in four arguments, passed in through
$a0-$a3. $a0 to $a2 are memory addresses. $a3 is a variable called size that has value 16. You can assume that all the content that $a2 points to has value zero. Suppose $a0 contains 0x61c10000, $a1 contains 0x61c20000, and $a2 contains 0x61c50000. Assume we have a cache with totalDataSize of 512 Bytes. The blockDataSize is equal to 64 Bytes. Find the lowest N that maximizes the hit rate.
HINT: At first, this function may seem daunting because it's in MIPS. Take the code line by line and you'll realize that it's not so bad. Note the three loops, and the way we jump to each one when incrementing. You may find it useful to try converting this to C first, and then computing the best hit rate.
At this point, you should be passing all tests for Part 2 from make test-part2. You should check for memory leaks by running make part2-memCheck.
Part 3
Overview
In Part 3, you will implement the MOESI protocol for cache coherency. If you haven't already, review the lecture slides, wiki page, and discussion worksheet for it.
The idea behind MOESI is to keep our caches coherent and minimize the number of writes to memory. In addition, we will assume that our reads from memory are also expensive and thus want to minimize reading from memory. Each block in a cache can be in one of five states: Modified, Owned, Exclusive, Shared, or Invalid (in no particular order - only to make pronunciation easier). The state depends on three bits: valid, dirty, and shared. Recall that the valid bit tells you whether or not the block contains garbage data. The dirty bit is our cache's belief of whether or not the block is synced with memory. The shared bit tells us if the block is shared across different caches. Depending on the permutation of these three bits for a block, it will take on one of five states. You can see this in the truth table below:
| Valid | Dirty | Shared | State |
|---|---|---|---|
| 0 | 0 | 0 | Invalid |
| 0 | 0 | 1 | Invalid | 0 | 1 | 0 | Invalid |
| 0 | 1 | 1 | Invalid |
| 1 | 0 | 0 | Exclusive |
| 1 | 0 | 1 | Shared | 1 | 1 | 0 | Modified |
| 1 | 1 | 1 | Owned |
We are interested in how the states can change. To understand this, we need to consider four cases:
- We read from our own cache.
- We write to our own cache.
- Some other cache receives a read, misses, reads from our cache, and copies the block to itself. This is called a probe read.
- Some other cache receives a write, misses, reads from our cache, copies the block to itself, and writes to its version of the block. This is called a probe write.
From each state, one of the four cases can occur. Depending on the current state and the selected case, we transition to another state (may be the same state as well). These words should sound familiar as we are describing a Finite State Machine (FSM). If you're rusty on that, now's a good time to review.
Below is an FSM Diagram that depicts our transitions. Carefully analyze this and justify the transitions to yourself. Think carefully about being in state A and receiving a particular case. How does that effect your three bits, making you transition to state B?
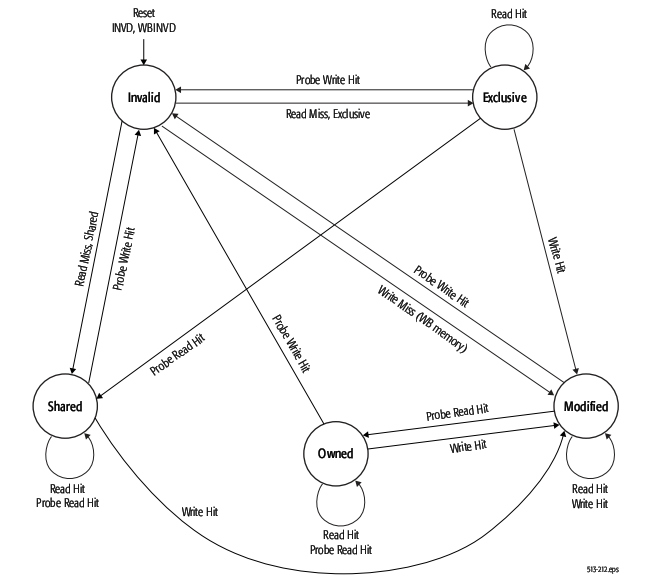
Note that there are also other scenarios that the diagram doesn't capture. For example, what happens if several blocks are valid and have their shared bit on, and all but one become invalidated? Then the last remaining copy is no longer shared, thus its shared bit needs to be flipped off. That would make that last block transition from Owned to Modified, or Shared to Exclusive. You should keep these types of situations in mind. Namely, think of all cases when bits can be flipped on or off.
The last bit to mention is how caches communicate with each other. When we have a small number of caches, which we will for this project, caches communicate by "snooping" on each other. To do this, they often use a snoop filter. This keeps track of what addresses are stored in each cache. When caches need to communicate with each other, they act through the snoop filter. This reduces redundancy by preventing you from visiting every cache. We have provided a snoop filter for you as a hash table called a snoopy_t. We will mention more on this below, but you will find it useful.
Now that we have the theory out of the way, let's talk about the project implementation. You will be dealing with the following files: coherenceUtils.c, coherenceUtils.h, coherenceRead.c, and coherenceWrite.c. Below is a description of each and its use to us:
-
coherenceUtils.cThis file contains the utility functions for cache coherency. You will write some functions in it. You may find the structs in
coherenceUtils.huseful for these. -
coherenceUtils.hThis file contains many useful functions and structs for Part 3, so let's explain some of them in detail.
-
cacheNode_tThis wraps your
cache_tstruct with an id. -
addressList_tThis is the linked list data structure we use for the hash table implementation.
-
snoopBucket_tThis wraps the linked list above into a bucket in the hash table.
-
snoopy_tThis is the actual hash table that wraps the buckets above.
-
cacheSystem_tThis wraps all the caches in the system along with the snooper.
-
-
coherenceRead.cThis file contains the read functions for cache coherency. You will write some functions in it.
-
coherenceWrite.cThis file contains the write functions for write coherency. You will write some functions in it.
DEBUGGING TIPS: You can run make part3 to compile your Part 3 code, but not run the executable. Then you can debug with cgdb caches.
Utility Functions
In this subpart you will fill functions in coherenceUtils.c. You will write:
-
determineState -
setState -
updateState
You will find the truth table above useful to writing determineState. This is essentially determining the state of a block based off the given cache and address. You may also find the findEviction function useful.
For setState, you will again find the truth table useful along with some functions in setInCache.c. Remember, to change the state of a block, the appropriate bits needs to be updated!
For updateState, you will again find findEviction useful. Suppose there are two caches: A and B. If some operation is performed on A results in an update on B, then updateState should be called on B with the new state in A. Both the truth table and FSM will be useful for this. Consider the current state you are in, the otherState, and how those determine the new state. Looking at the three main bits (valid, dirty, shared) will help.
Lastly, you'll need the provided decrementLRU function to write this. Remember that when a block gets invalidated, its LRU bits are set to the maximum value. This means all blocks in the set with values greater than the original LRU value of the now invalid block, should be decremented by one. This has been implemented for you, however you need to use it correctly.
When finished, you can test with make test-part3-utils.
Reading Coherency
In this subpart you will fill functions in coherenceRead.c. You will write:
-
cacheSystemRead
First you'll see that this function has been cut up for you. It's rather long so we have broke it up into parts that you need to fill in. The other four read functions in this file simply wrap the one you have to write. However you will need to error check for these. Again, you'll find all the structs in coherenceUtils.h and functions in coherenceUtils.c useful. You should read through all the code for the snooper and understand what you can do with it. The inline comments should guide you on what to fill in.
When finished, you can test with make test-part3-read.
Writing Coherency
In this subpart you will fill functions in coherenceWrite.c You will write:
-
cacheSystemWrite
All the tips for cacheSystemRead apply here, so we won't repeat them. Again, you'll need to error check for the other write functions. Compared to the coherence read subpart, there is a slight difference. What does writing a block to one cache do to all copies in other caches? Does the same happen with a read? With that in mind, implement cacheSystemWrite. It should be similar to cacheSystemRead since they're very symmetrical, with the exception hinted at above.
When finished, you can test with make test-part3-write.
At this point, you should be passing all tests for Part 3 from make test-part3. You should check for memory leaks by running make part3-memCheck.
Testing
Our Tests
At this point, you should be passing all the given tests! You can verify this by running make test-all. If you're failing some, you can narrow them down by individually running make test-part1, make test-part2, and make test-part3. Note that these are NOT comprehensive tests. We will also have hidden tests that will be autograded. So, you must do some testing of your own. We discuss more below.
Valgrind
You should make sure you have no memory leaks in your code. You can verify this by running make memCheck. If you're having leaks, you can narrow down to which part by individually running make part1-memCheck, make part2-memCheck, and make part3-memCheck.
Your Own Unit Tests
We have set up an easy framework for you to write your own unit tests! We have been using CUnit. In the root of your project folder, open up the testFiles folder. Inside you will find problem1UnitTests.c, problem2UnitTests.c, and problem3UnitTests.c. Within these, you should see how we create a test function and use CUnit commands to test functionality. Once you make this function, you need to run it in main. At the bottom of each file, you'll find the main function. Towards the bottom of this, you'll find the line labeled CU_basic_set_mode(CU_BRM_VERBOSE);. Please add your suite(s) above this line. Scroll to the top of main to see how we create and add a test suite.
Submission
Submitting for the First Time
There are two steps required to submit proj4. Failure to perform both steps will result in loss of credit:
First, you must submit using the standard unix submit program on the instructional servers. This assumes that you followed the earlier instructions and did all of your work inside of your git repository. To submit, follow these instructions after logging into your cs61c-XXX class account:
cd <proj4 repo directory> # Your proj4 git repo, should contain all the files for the project
submit proj4Once you type submit proj4, follow the prompts generated by the submission system. It will tell you when your submission has been successful and you can confirm this by looking at the output of glookup -t.
Second, you must submit proj4 to your Bitbucket repository. To do so, follow these instructions after logging into your cs61c-XXX class account:
cd <proj4 repo directory> # Your proj4 git repo, should contain all the files for the project
git add -u # Should add all modified files in proj4 directory
git commit -m "your commit message here"
git tag -f "proj4-sub" # The tag MUST be "proj4-sub". Failure to do so will result in loss of credit.
git push origin master --tags # Note the "--tags" at the end. This pushes tags to bitbucketResubmitting
If you need to re-submit, you can follow the same set of steps that you would if you were submitting for the first time. This means you should resubmit through both the submit program and bitbucket. The only exception to this is in the very last step, git push origin master --tags, where you may get an error like the following:
Counting objects: 7, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (4/4), done.
Writing objects: 100% (4/4), 372 bytes | 0 bytes/s, done.
Total 4 (delta 3), reused 0 (delta 0)
To https://Zubair-Marediya@bitbucket.org/Zubair-Marediya/proj4-tag-taj.git
d134f4e..69cbd65 master -> master
! [rejected] proj4-sub -> proj4-sub (already exists)
error: failed to push some refs to 'https://Zubair-Marediya@bitbucket.org/Zubair -Marediya/proj4-tag-taj.git'
hint: Updates were rejected because the tag already exists in the remote.
If this occurs, simply run the following instead of git push origin master --tags:
git push -f origin master --tagsNote that in general, force pushes should be used with caution. They will overwrite your remote repository with information from your local copy. As long as you have not damaged your local copy in any way, this will be fine.