Project 4: Build a Distributed Key-Value Store
Summary
In Project 4, you will implement a distributed key-value store that
runs across multiple nodes.
- Data storage is durable, i.e., the system does not lose data if
a single node fails. You will use replication for fault tolerance.
- The key-value store is to be built optimizing for read
throughput. Accessing data concurrently from multiple replicas of
the data will be used to improve performance.
- Operations on the store should be atomic. i.e., either the
operation should succeed completely or fail altogether without any
side effects. You will use the Two-Phase Commit protocol to ensure
atomic operations.
Multiple clients will be communicating with a single coordinating server
in a given messaging format (KVMessage) using a client
library (KVClient). The coordinator contains a write-through
set-associative cache (KVCache), and it uses the cache to
serve GET requests without going to the (slave) key-value servers it
coordinates. The slave key-value servers are contacted for a GET only
upon a cache miss on the coordinator. The coordinator will use
the TPCMaster library to forward client requests for PUT and
DEL to multiple key-value servers (KVServer)
using TPCMessage and follow the 2PC protocol for atomic PUT
and DEL operations across multiple key-value servers. Note
that, TPCMessage uses the same KVMessage class used
in Project 3 with extra fields and message types. KVServers
remain the same as Project 3.
Project Clarifications: https://piazza.com/class#fall2012/cs162/727
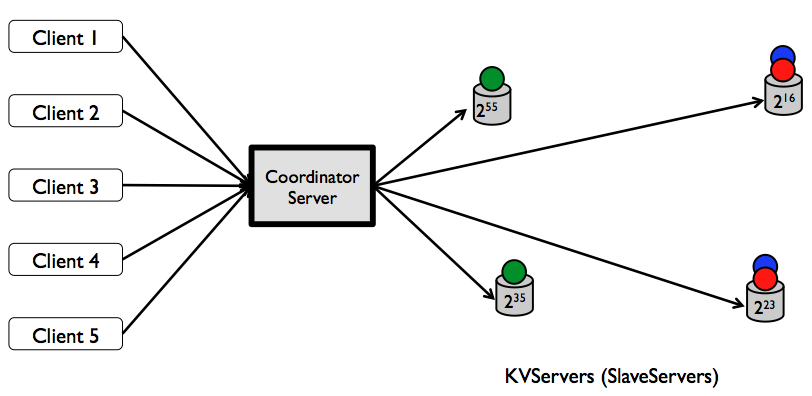
Figure: A distributed key-value store with replication factor of two.
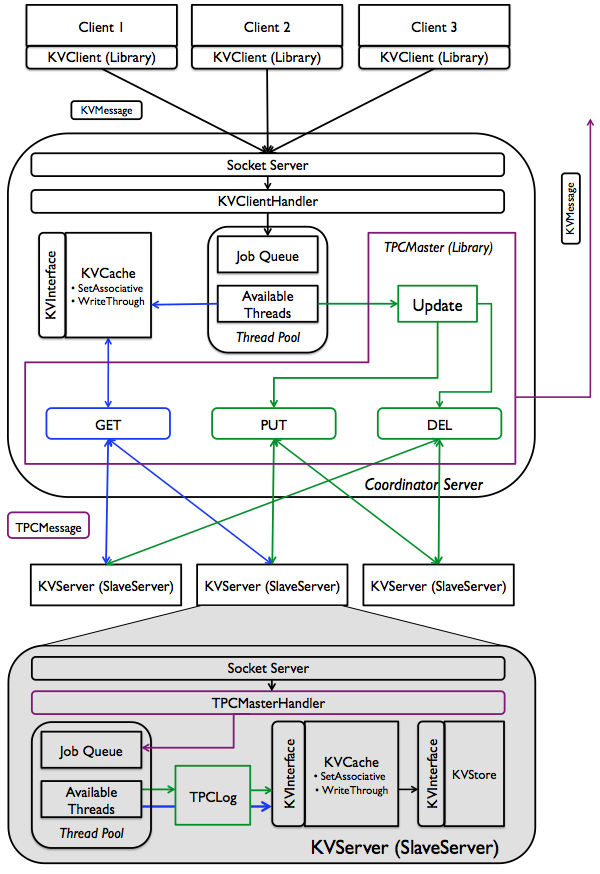
Figure: Functional diagram of a distributed key-value store. Components in colors other than black are the key ones you will be developing for this project. Blue depicts GET execution path, while green depicts PUT and DEL; purple ones are shard between operations. Note that, components in black might also require minor modifications to suite your purposes. Not shown in the figure: PUT and DEL will involve updating the write-through cache in the coordinator.
Skeleton Code
The project skeleton you should build on top of is
posted
at https://bitbucket.org/prashmohan/project4skeleton. If
you have git installed on your system, you can run git clone
https://bitbucket.org/prashmohan/project4skeleton.git. Project 4
builds on top of the Single Server key-value Store developed in
Project 3; however, several interfaces have been extended to support
the required functionalities for Project 4. You can reuse the code
developed for Project 3 and define additional classes and methods as
you see fit. You can feel free
to change the
skeleton as you deem fit. We will only test against end-to-end
semantics. However you should still submit your own unit tests.
You can also download the skeleton without using git from the above-mentioned URL (look for the download link in that page).
Requirements
- Unless otherwise specified below, you will have to satisfy the requirements described in Project 3.
- Each key will be stored using 2PC in two
key-value servers; the first of them will be selected
using consistent hashing, while the second
will be placed in the successor of the first one. There will
be at least two key-value servers in the system. See below
for further details.
- Key-value servers will have 64-bit globally unique IDs (use
unique long numbers), and they will register with the
coordinator with that ID when they start. For simplicity, you can
assume that the total number of key-value servers are fixed, at any
moment there will be at most one down server, and
they always come back with the same ID if they crash (Note that this
simplification will cause the system to block on any failed
key-value server. However, not assuming this will require dynamic
successor adjustment and re-replication, among other
changes.).
- You do not have to support concurrent update operations
irrespective of which key they are working on (i.e., 2PC PUT and DEL
operations are performed one after another), but retrieval
operations (i.e., GET) of different keys must be concurrent unless
restricted by an ongoing update operation on the same set.
- For this particular project, you can assume that the coordinator
will never fail/crash. Consequently, there is no need to log its
states, nor does it require to survive failures. Individual
key-value servers, however, must log necessary information to
survive from failures.
- The coordinator server will include a write-through
set-associative cache, which will have the same semantics as the
write-through cache you used before. Caches at key-value servers
will still remain write-through.
- You should bulletproof your code, such that the server does not
crash under any circumstance.
- You will run the client interface of the coordinator server on
port 8080.
- Individual key-value servers must use random ports assigned upon
creating respective SocketServers for listening to 2PC requests
(Note that when you see the SocketServer's constructor, the
port is set to -1. This must be replaced with a random port
number). They must register themselves with the 2PC interface of the
coordinator server running on port 9090. To make things simpler,
assume that the TPC master will always respond with a ack message
during registration.
Tasks (Weights)
- (40%) Implement the TPCMaster class that
implements 2PC coordination logic in the coordinator
server. TPCMaster must select replica locations
using consistent hashing.
- (40%) Implement the TPCMasterHandler class
that implements logic for 2PC participants in key-value
servers.
- (10%) Implement registration logic in SlaveServer (aka
key-value Server) and RegistrationHandler
in TPCMaster. Each SlaveServer has a unique ID that it uses
to register with the TPCMaster in the coordinator.
- (10%) Implement the TPCLog class that
key-value servers will use to log their states during 2PC operations
and for rebuilding during recovery.
- Extra Credit (5%) Upon receiving a
request at the coordinator server, the server would need to contact
the slave servers the key is replicated to (only upon cache miss in
the case of GET requests). For the previous tasks, it is fine to
contact the slave-server sequentially. For extra credit, you should
improve the performance of the system by contacting the slave server
in parallel.
- Extra Credit (5%) In order to improve
the performance even further, the 2PC operations themselves should
be done in parallel. If the key in the requests hash to different
sets in the coordinator cache, then these requests should be
executed in parallel. Otherwise, the operations should be blocked
and executed one after the other.
Deliverables
As in previous projects, you will have to submit initial and final
design documents as well as the code itself.
- Initial Design Document (Due: Nov 26th,
2012)
- Code (Due: Dec 6th, 2012)
- Final Design Document (Due: Dec 7th, 2012)
Additionally, you will have to submit JUnit test
cases for each of the classes you will implement. Following is an
outline of the expected progress in terms of test cases in each of the
project checkpoints.
- Initial Design Document: One sentence on the test
cases you plan on implementing for each class and why.
- Code: Submit the final set of test cases.
- Final Design Document: One sentence on the test
cases you have implemented for each class and why.
Consistent Hashing
As mentioned earlier,
key-value servers will have unique 64-bit IDs. The coordinator will
hash the keys to 64-bit address space. Then each key-value server will
store the first copies of keys with hash values greater than the ID of
its immediate predecessor up to its own ID. Note that, each key-value
server will also store the keys whose first copies are stored in its
predecessor.
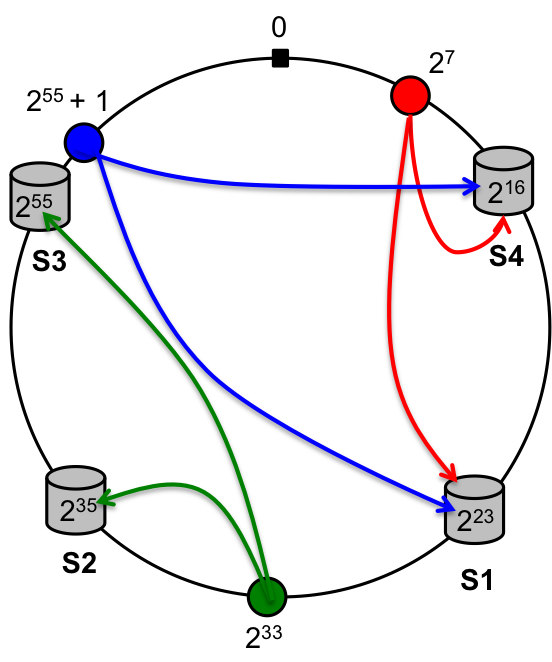
Figure: Consistent Hashing. Four key-value servers and three
hashed keys along with where they are placed in the 64-bit address
space. In this figure for example, the different servers split the key
space into S1:; [216 + 1, 223], S2:
[223 + 1, 235], S3: [235 + 1,
255] and finally note that the last server owns the key
space S4: [255 + 1, 264 - 1] and [0,
216]. Now when a key is hash to say a value 255
+ 1, it will be stored in the server that owns the key space, i.e, S4
as well as the immediately next server in the ring S1.
Sequence of Operations During Concurrent GET and
PUT/DEL Requests
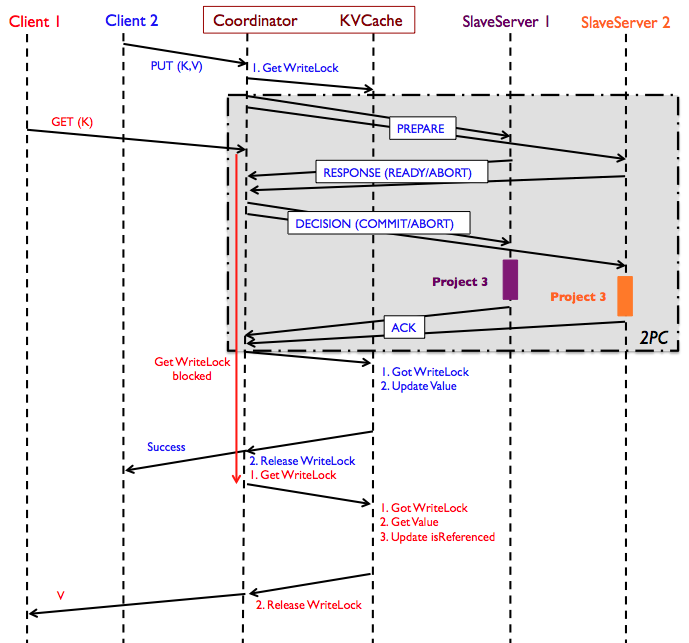
Figure: Sequence diagram of concurrent read/write operations
using the 2PC protocol in Project 4. "Project 3" blocks in the diagram
refer to the activities when clients write to a single-node key-value
server, where the coordinator is the client to individual key-value
servers. GET request from Client 1 is hitting the cache in the above
diagram; if it had not, the GET request would have been forwarded to
each of the SlaveServers until it is found.
Extended KVMessage format (TPCMessage piggybacked on KVMessage) for the Coordinator and SlaveServer communication
- 2PC Put Value Request:
<?xml version="1.0" encoding="UTF-8"?>
<KVMessage type="putreq">
<Key>key</Key>
<Value>value</Value>
<TPCOpId>2PC Operation ID</TPCOpId>
</KVMessage>
- 2PC Delete Value Request:
<?xml version="1.0" encoding="UTF-8"?>
<KVMessage type="delreq">
<Key>key</Key>
<TPCOpId>2PC Operation ID</TPCOpId>
</KVMessage>
- 2PC Ready:
<?xml version="1.0" encoding="UTF-8"?>
<KVMessage type="ready">
<TPCOpId>2PC Operation ID</TPCOpId>
</KVMessage>
- 2PC Abort:
<?xml version="1.0" encoding="UTF-8"?>
<KVMessage type="abort">
<Message>Error Message</Message>
<TPCOpId>2PC Operation ID</TPCOpId>
</KVMessage>
- 2PC Decisions:
<?xml version="1.0" encoding="UTF-8"?>
<KVMessage type="commit/abort">
<TPCOpId>2PC Operation ID</TPCOpId>
</KVMessage>
- 2PC Acknowledgement:
<?xml version="1.0" encoding="UTF-8"?>
<KVMessage type="ack">
<TPCOpId>2PC Operation ID</TPCOpId>
</KVMessage>
Registration Messages
- Register:
<?xml version="1.0" encoding="UTF-8"?>
<KVMessage type="register">
<Message>SlaveServerID@HostName:Port</Message>
</KVMessage>
- Registration ACK:
<?xml version="1.0" encoding="UTF-8"?>
<KVMessage type="resp">
<Message>Successfully registered SlaveServerID@HostName:Port</Message>
</KVMessage>
KVMessage with Multiple Error Messages
- Multiple error messages in case of an abort should be placed in the same Message field of a "resp" message prefixed by "@SlaveServerID:=" and separated by the newline character ('\n'). Example:
<?xml version="1.0" encoding="UTF-8"?>
<KVMessage type="resp">
<Message>@SlaveServerID1:=ErrorMessage1\n@SlaveServerID2:=ErrorMessage2</Message>
</KVMessage>
The ignoreNext Message
Testing distributed systems is hard, more so in presence of
failures. To make it slightly easier, we are introducing
the ignoreNext message that will be issued directly to the
slave server by the autograder. Upon reception of this message, the
slave server will ignore the next 2PC operation (either a PUT or a
DEL) and respond back with a failure message during the first phase of
2PC. This will cause the 2PC operation to fail and the failure code
path will be triggered.
- ignoreNext KVMessage/TPCMessage:
<?xml version="1.0" encoding="UTF-8"?>
<KVMessage type="ignoreNext"/>
- ignoreNext ACK:
<?xml version="1.0" encoding="UTF-8"?>
<KVMessage type="resp">
<Message>Success</Message>
</KVMessage>
Error messages in Addition to Project 3
- "Registration Error: Received unparseable slave information" -- Registration information was not in "slaveID@hostName:port" format.
- "IgnoreNext Error: SlaveServer SlaveServerID has ignored this 2PC request during the first phase" -- Error message from the first phase corresponding to an ignoreNext message
Concepts You are Expected to Learn
- Two-Phase Commit
- Logging and Recovery using Logs
- Consistent Hashing
- Failure Detection using Timeouts