Parsing intro
Today we’re going to take a step back and talk about this parsing thing that keeps coming up. We’ve been using a parser this whole time, but what does it actually do? And why do we prefer using the output of a parser, rather than just using the program text as a string?
Today we’re going to be pretty concrete. We’ll just work on parsing a particular langauge, the language of S-expressions we’ve been using for our Scheme variant. S-expressions are known to be especially easy to parse—in fact, that’s one of the reasons languages might pick S-expressions as their input of choice. So we’ll be able to write a whole S-expression parser from scratch today, and this will help us think about what a parser is actually doing and some of the design guidelines we should keep in mind. Going forward we’ll talk about how to parse more complicated languages.

First let’s step back a moment. There are actually two
transformation steps on the route from the program text to the
tree-structured s_exp inputs we’ve been using in the
interpreter and compiler. The two transformation steps are (i)
tokenization and (ii) parsing. Tokenization transforms a flat string
into a flat list of tokens. Parsing transforms a flat list of tokens
into a tree that represents the structure of the program. A token might
be a paren, a function name, a number. (See some token examples in the
image above. The tokens are in all caps by convention.) We’ll
circle back around to tokenization, but for now let’s focus on
parsing.
The first thing we need when we parse a language is a description of what the language looks like:

This is the grammar of S-expressions. We might think to ourselves, hey,
we already have this s_exp type in our compiler and
interpreter—maybe that’s a description of how programs
look. But it doesn’t have quite all the information we need. If we
take a look at s_exp, you’ll notice some elements are
missing that appear in the written programs. For instance, where are all
the parens we’re always piling into our Scheme programs?
type s_exp = Exp.t = Num of int | Sym of string | Lst of s_exp list
So our s_exp type isn’t a complete description of
what programmers are allowed to write in our language. Instead
we’ll need that grammar. This is a context-free grammar. If you
take a theory class, you’ll learn much more about what
context-free means, and you’ll see some examples of grammars that
aren’t context-free. You’ll also learn a lot about the class
of languages that context-free grammers can express. We won’t be
diving deep on that here. We’ll be looking just at context-free
grammars as a way to describe how programming languages look in their
textual form. Grammars a convenient, concise, formal way of writing down
what strings the programmers is allowed to feed to a given compiler or
interpreter.
The symbols in angle brackets are nonterminals. They don’t get to appear in the program string, but they’re helpful along the way. The other symbols, the ones that aren’t nonterminals, are terminals. Each rule is called a production rule. Finally, we have to select one of our non-terminal symbols as a special start symbol. Once we’ve decided on the set of nonterminals, the set of terminals, the set of production rules, and the start symbol, we’ve completed the definition of a grammar.
(Note that terminals can be associated with data–e.g., the
n in NUM (n). We’ll get these from
tokenization.)
We can read each production rule as saying the string of symbols on the
left “is” or “is a” string of symbols on the
right. So from our S-expression grammar, we can say an S-expression is a
number or is a symbol or is a left paren followed by an
<lst> followed by a right paren.
We call these production rules because when we read them forward like
this, we can use them to produce all the programs allowed in the
language. Say we select our start symbol <s_exp>;
Using our first production rule, we can produce a very simple program,
NUM (2), which we’d write in our language as the
program 2.
Here’s an example of how we can apply the production rules to create a more interesting program:
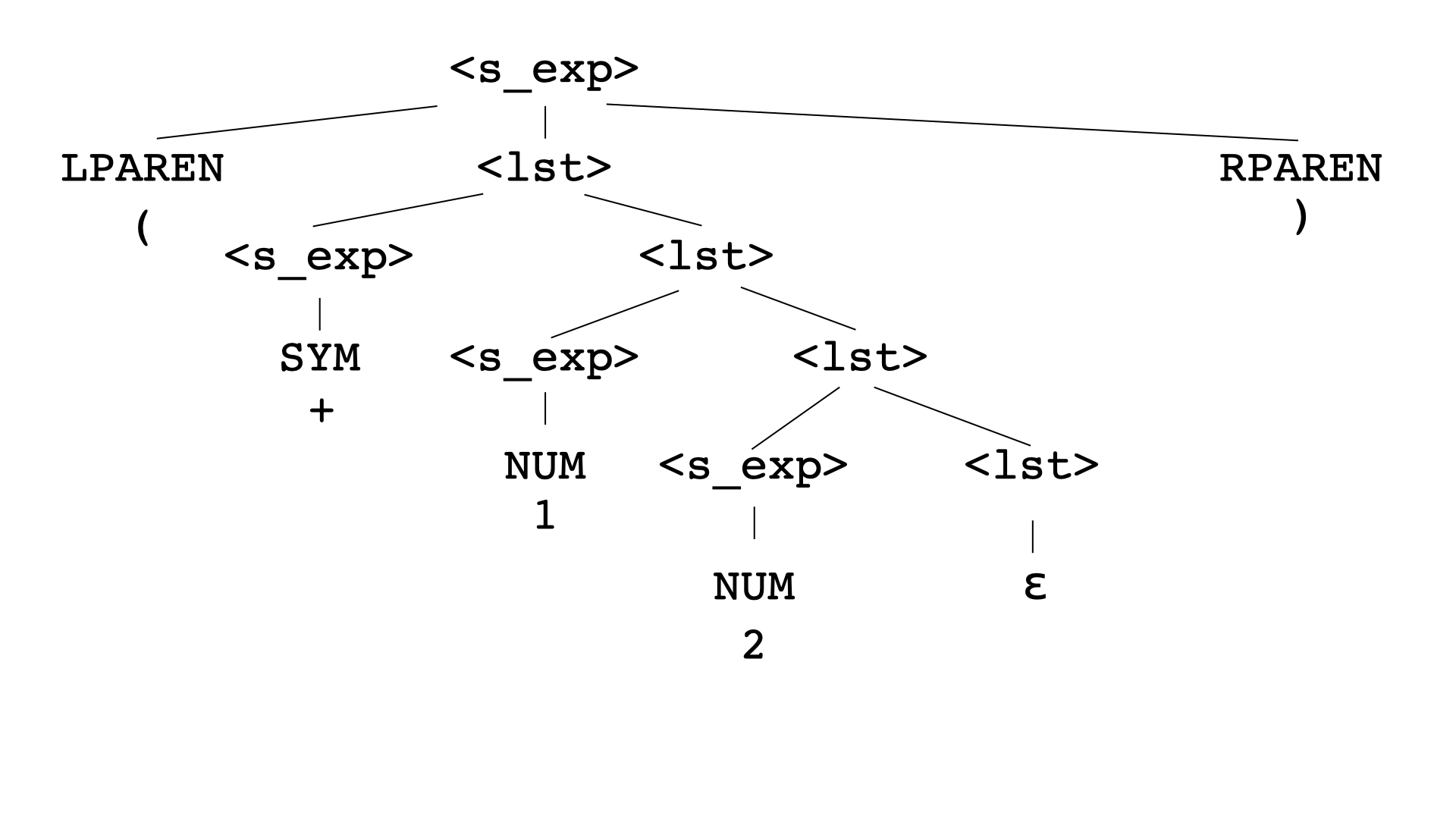
Notice that the leaves of the tree are all terminals. In contrast, the internal nodes are nonterminals. Take a moment to look at the tree. What program does it produce? (Scroll for answer.)
(+ 1 2)
Another way to think of this tree is as a parse tree. We’ve
just walked through how to run rules forward in order to go from the
start symbol to a program in our language. What if instead we want to
start with a string and then figure out if it can be interpreted as a
program in our language? Say we have the string (+ 1 2).
What would it take to persuade us that it’s an S-expression? It
would take one of these parse trees! What it means to be part of our
language is that there’s a way of walking the production rules
that produces the target string. In this case, we can see there’s
a way of walking the production rules that does produce the target
string (+ 1 2), so we know (+ 1 2) is an
S-expression.
This is why we need a grammar in order to write a parser. Coming up with a grammar that correctly describes our target language can be hard. We’ll talk more about that process in upcoming class sessions.
One last thing to notice. We already took a look at our
s_exp type and noticed that there are some similarities,
even though our s_exp type doesn’t have all the
details we need for parsing. Even though the type doesn’t include
all the details, there’s definitely an interesting
correspondence here:

We’ll use this correspondence to guide the structure of our parser.
Let’s start with our very bad, no good tokenizer. Don’t worry about this too much. We’re just using it for today so we can jump straight to parsing:
type s_exp = Num of int | Sym of string | Lst of s_exp list
type token = NUM of int | SYM of string | LPAREN | RPAREN
exception ParseError
let token_of_string (s : string) =
match s with
| "(" ->
LPAREN
| ")" ->
RPAREN
| _ -> (
try NUM (int_of_string s) with _ -> SYM s )
let tokenize (s : string) =
s |> String.split_on_char ' ' |> List.map token_of_string
To start on our parser, we’re going to want to construct a couple
helper functions. We’re going to construct them in a very
particular way. For each nonterminal that appears on the left side of
our production rules, we’ll make one helper. So we’ll have
one for parse_s_exp and one for parse_lst.
They’ll both take in a list of tokens. They’ll also both
output a list of tokens, the tokens that remain to be processed. But
they’ll have one additional output each. For
parse_s_exp, that’ll be an S-expression, because
that’s what it’s trying to parse from the input tokens. For
parse_lst, it’ll be a list of S-expressions, because
that’s what it’s trying to parse from the input tokens.
Here’s how they look:
let rec parse_s_exp (toks : token list) =
match toks with
| NUM n :: toks2 ->
(Num n, toks2)
| SYM s :: toks2 ->
(Sym s, toks2)
| LPAREN :: toks2 ->
let exps3, toks3 = parse_lst toks2 in
(Lst exps3, toks3)
| _ ->
raise ParseError
and parse_lst (toks : token list) =
match toks with
| RPAREN :: toks2 ->
([], toks2)
| _ ->
let exp2, toks2 = parse_s_exp toks in
let exps3, toks3 = parse_lst toks2 in
(exp2 :: exps3, toks3)
How have we filled in the bodies of the helper functions? Notice that we’re adding a match case for each of the production rules. One of the ways that our grammar is structured really nicely is that all we have to do to figure out which case is relevant is look at the first token in our list of input tokens.
One interesting thing to notice is the first case in
parse_lst. We wanted to look for the empty string, but how
would we look for the empty string, since it’s just
""? Our tokenizer isn’t going to produce that for us.
Instead we had to think about what would actually appear next if we had
an empty list—which is to say, a right paren! We were able to
figure that out by looking at where <lst> is used on
the right side of any prouction rules. In this case,
<lst> is used exactly once, in the last production
rule that has <s_exp> on the left side:
<s_exp> ::= LPAREN <lst> RPAREN. In future
class sessions, we’ll see how we can use this same approach with
other grammars.
For our second <lst> case, things are a bit simpler.
We know from the grammar that we expect to see an
<s_exp> and then another <lst>. We
already have helper functions for parsing those, so we’ll go ahead
and call them.
Now that we have our helper functions, based on our production rules, we
can make the parse function itself. That will take care of
tokenization, then starting our parsing process based on our start
symbol, <s_exp>.
let parse (s : string) = let toks = tokenize s in let exp, l = parse_s_exp toks in if List.length l = 0 then exp else raise ParseError
Finally, what should we do in the case where we parsed an S-expression
from the start of our token list, but we had some tokens left over? This
would happen if we input a program like ( + 1 2 ) 3.
That’s not the kind of input our compiler and interpreter accept,
so we’ll make this case raise a ParseError.
So that’s our whirlwind tour of how to write a parser, and in particular how to generate the structure of a parser from a grammar. This worked so cleanly becuase S-expressions have such a nicely structured grammar. For other grammars, we’ll have to do more work. We’ll be talking more about this soon.