
Original Image 1
By: Alex Pan
In the previous part of this project, we explored how homographies can be used to warp images to a certain perspective. We applied this technique to a set of pictures of the same scene with different perspectives, allowing us to stich together and create panoramas. However, this involved manually selecting correspondence points between the images. In this part of the project, we will explore how we can automatically match features between images to stich mosiacs together automatically. Our approach is based on this paper.
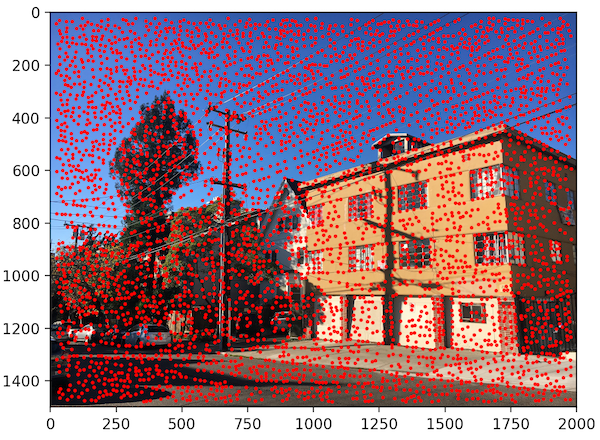
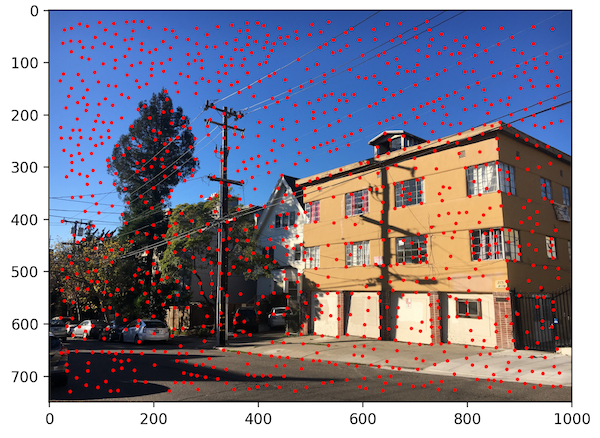
We choose to define interest points as Harris corners, which are based off of corner strength (differences in pixel intensity within a neighborhood). Just returning all of the Harris corners gives us way too many points, however, so we filter it down. The process we use to filter Harris points is called Adaptive Non-Maximal Suppression (ANMS), which not only narrows down the points but also makes sure they are distributed evenly throughout the image.
ANMS works by assigning a radius to each corner, which limits the feature points that exist in each area of the picture. To find the radius, we comparing every interest point to every other interest point in the image. The radius is determined by the minimum distance where that one point's corner strength is significantly more than every other point.
Detecting all Harris points on our images gives us thousands and thousands of points. By using ANMS, we can narrow this down to 500 points, which we will use to actually match features between images. Below, we show these results for a sample set of images.
Original Image 1

Original Image 2
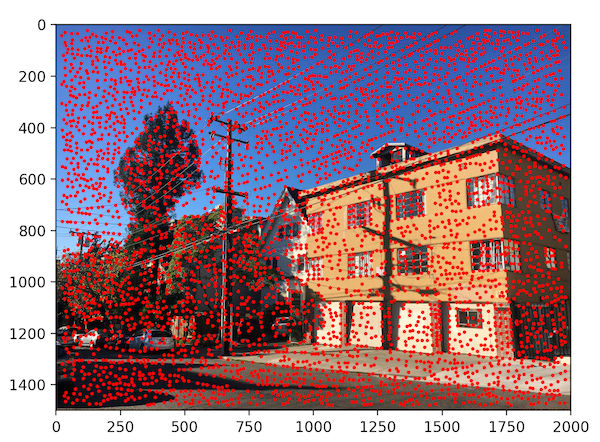
Image 1 (Harris Corners)
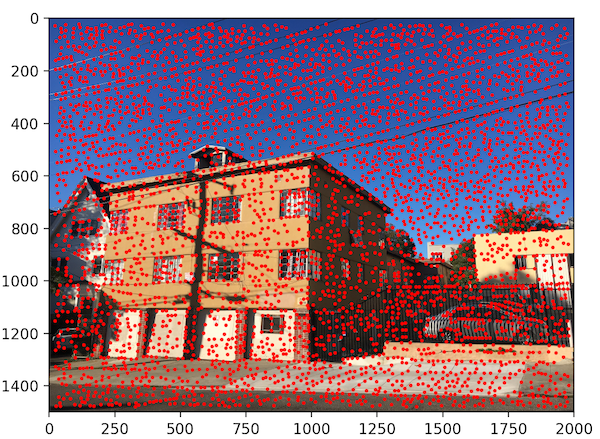
Image 2 (Harris Corners)
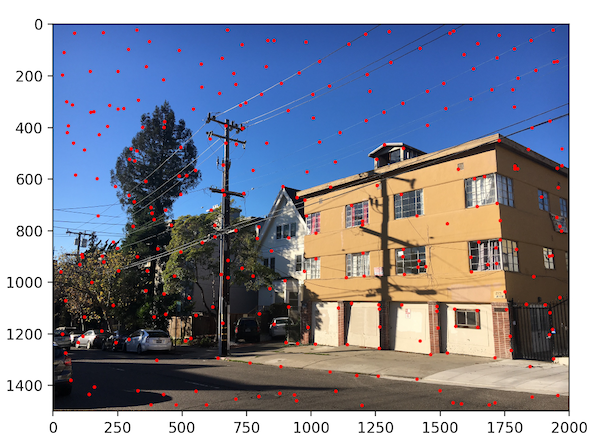
Image 1 (ANMS filtering)
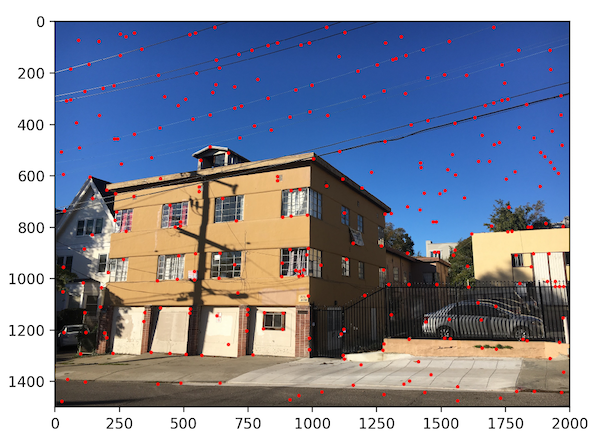
Image 2 (ANMS filtering)
Now that we have located where the most prevalent features are on each image. we have to extract that actual feature that each point corresponds to. To do this, we take the 40 x 40 patch around each feature point. Because the same feature in different images won't exactly match up due to different perspectives and noise, we want to allow for some variation around the feature itself. To make the patches less sensitive to the exact feature location, we sample the pixels at a lower frequency than what the interest points are originally at. Given a 40 x 40 patch, we apply a Gaussian filter to it and then sample every 5th row and column to create a, 8 x 8 patch. This is what we will use when we actually look to match features between images.
Below, we show what an arbitrary feature patch looks like, taken from the images above.
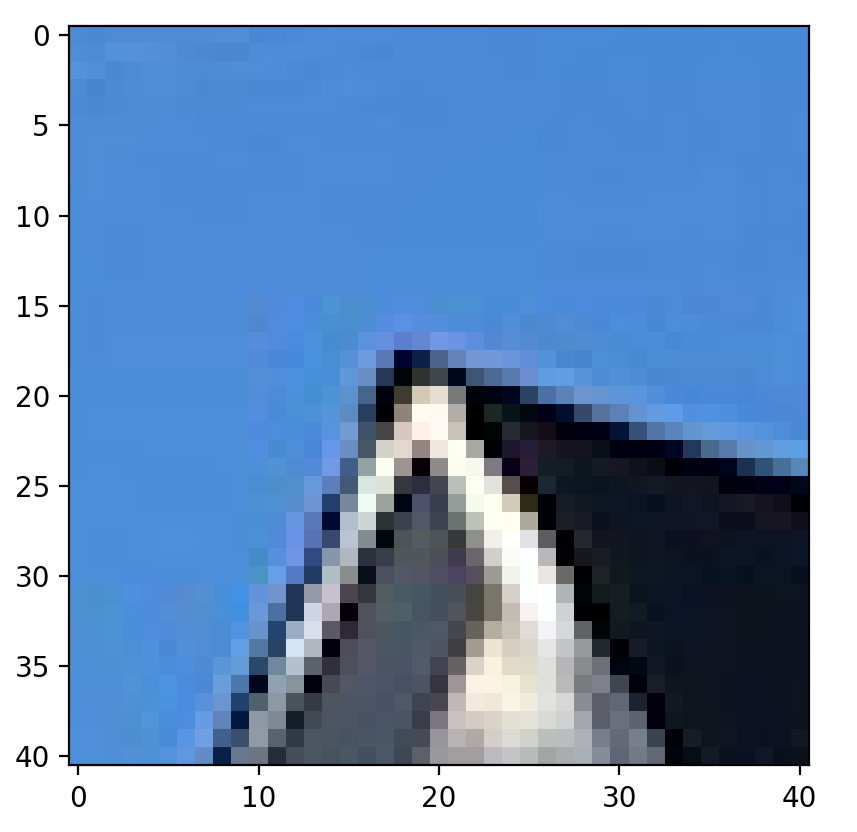
40 x 40 feature patch
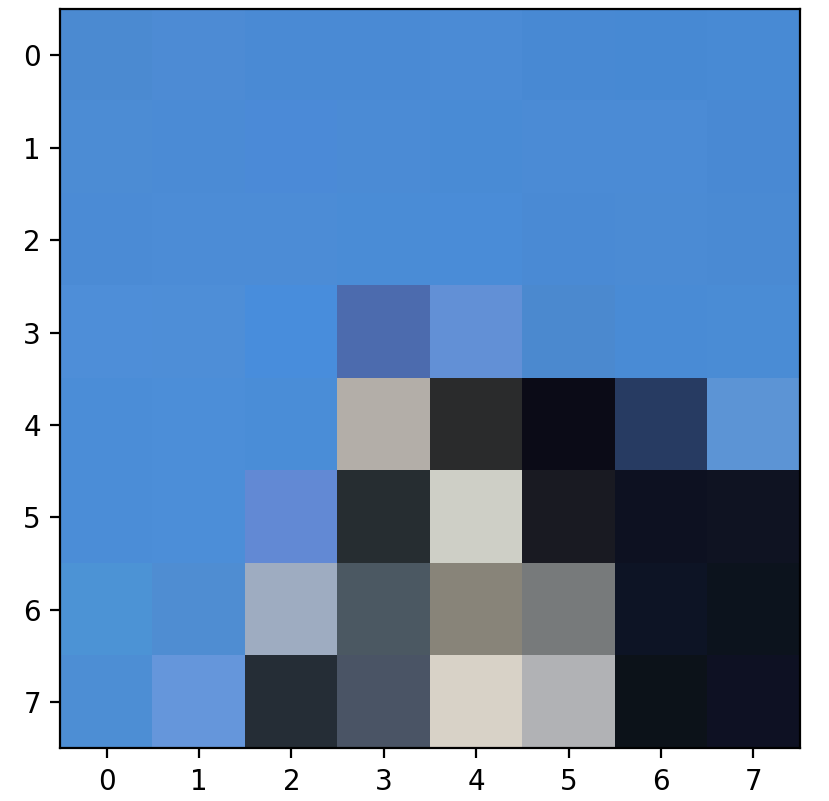
8 x 8 feature patch
Given feature patches for each image, we need to find which features corresponding to which between images. To do this, we compare every feature in one image to every feature in the other image. For each feature pair, we calculate the difference between the 8 x 8 features by finding the sum of the Euclidian distances between every corresponding pixel. For a given feature, we sort these results by smallest distance first, and call the first two results nn1 and nn2 (nn = nearest neighbor). If the ratio nn1/nn2 is smaller than a certain threshold, we consider nn1 'good enough' and use it as the feature corresponding to the given feature we are examining. This works by assuming that if the next closest match is very different from the closest match, the closest match is probably correct.
After performing these computations on our street images above, we are left with the matching features between both images.

Image 1 feature matches

Image 2 feature matches
Not all of the matches computed above are correct right off the bat; in some cases, there are random points that clearly don't correspond with anything in the other image. To throw away the incorrect matches, we use a technique called RANSAC (random sample consensus).
RANSAC involves randomly selecting 4 random points and computing a homography from them. We then apply this homography to all of the feature points in one image. For each computed point, we calculate the distance between it and the actual corresponding point it was matched to before. If this distance is small enough, it is classified as an inlier. We repeat this process thousands of times, keeping track of the inlier set for each 4 random points used in the homography. The largest inlier set is used to compute the final, actual homography.
Below, we show the inlier sets that were used to create the final homography. Because we did so many iterations of RANSAC, you can see that every feature between the images is correctly matched.

Image 1 inliers

Image 2 feature inliers
We've automated the process of picking correspondence points, so all that's left to do is to warp each image based on the homography, and blend them together. All of this is already done in the first part of this project, so check it out for more details on how we do this.
Here are a few panoramas we autostiched together! As you can see, they look even better than the handmade ones from the previous part of the project! Beacuse the features were matched exactly to the piel, there is no ghosting in the overlapping regions. It's unsurprising that computers prove to be more precise than humans.
Original Image 1
Original Image 2

Full Mosaic

Mosaic (Cropped)

Original Image 1

Original Image 2

Full Mosaic

Mosaic (Cropped)

Original Image 1

Original Image 2

Full Mosaic

Mosaic (Cropped)
The coolest part about this project was seeing how we could automatically correct mistakes that were made when features were being matched. I was a bit skeptical early on about the matching, when I saw a few random points in the middle of nowhere being labeled as corresponding features. It was very interesting to see how setting thresholds and running RANSAC many times could rule out all of these points.
Here's an interesting point to consider regarding this project. The automatic feature detection and matching that we did involved many complex mathematical concepts, not to mention a large amount of difficult coding. The runtime of the code is also a significant concern. Improvements such as vectorization and more processing power can ease some of these issues, but we are trying to automate what is essentially a 15 second task for a real human. If we consider all of the factors that go into automation, at what point do the costs outweight the benefits? Automation is obviously worth it in many situations (especially this case, since we were able to get rid of ghosting artifacts), but it's important to keep perspective.
One of the aspects in the paper that we didn't implement was using multi-scale Harris corners for feature points. Our version just found Harris corners in the original scale image, but doing this at multiple levels increases robustness. To add this to our algorithm, we create a 5-level Gaussian pyramid for each image. We then run the Harris corner detector at each level to find features that may have been obscured at the original scale.
Unfortunately, for the images we used, multi-scale processing didn't pick up any new features and was basically equivalent to single-scale processing. The features and matching features at each level ended up being th same as the ones in the single-scale version. Nevertheless, here are the multi-scale points at each level for one of our images. We also show the result panorama from using multi-scale on the set of images.
Harris corners (Level 1)
Harris corners (Level 2)
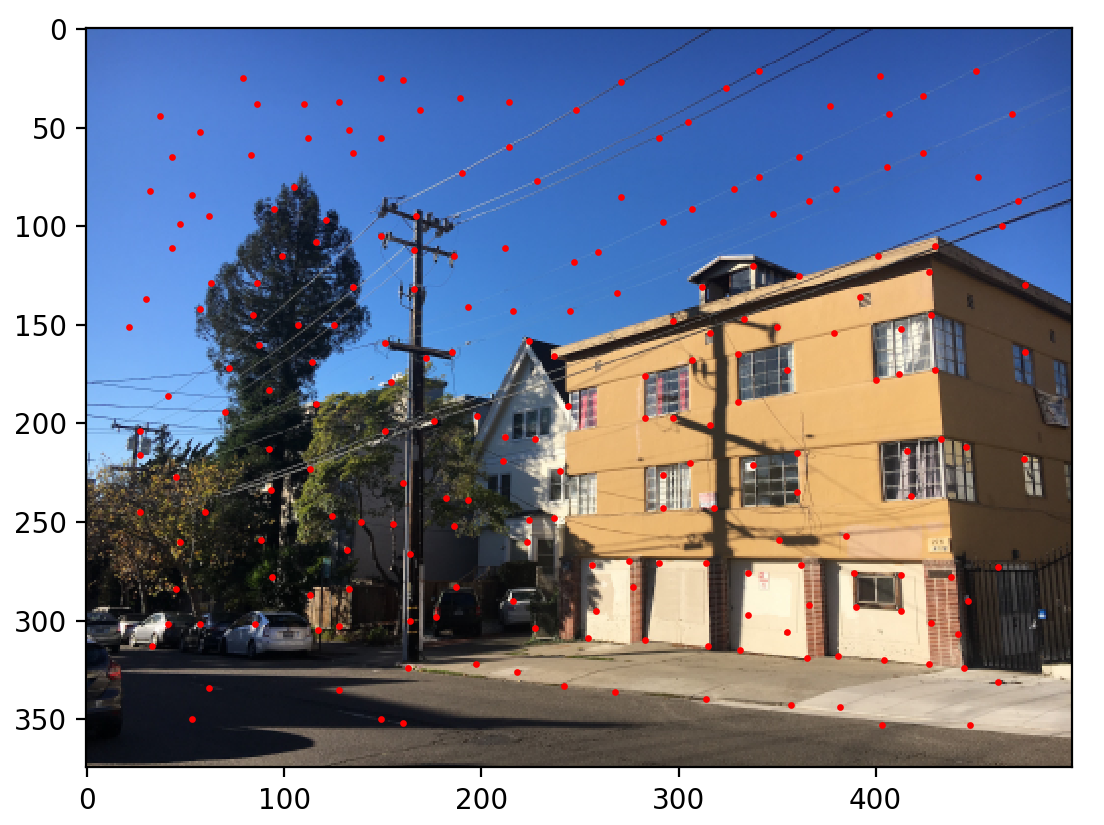
Harris corners (Level 3)
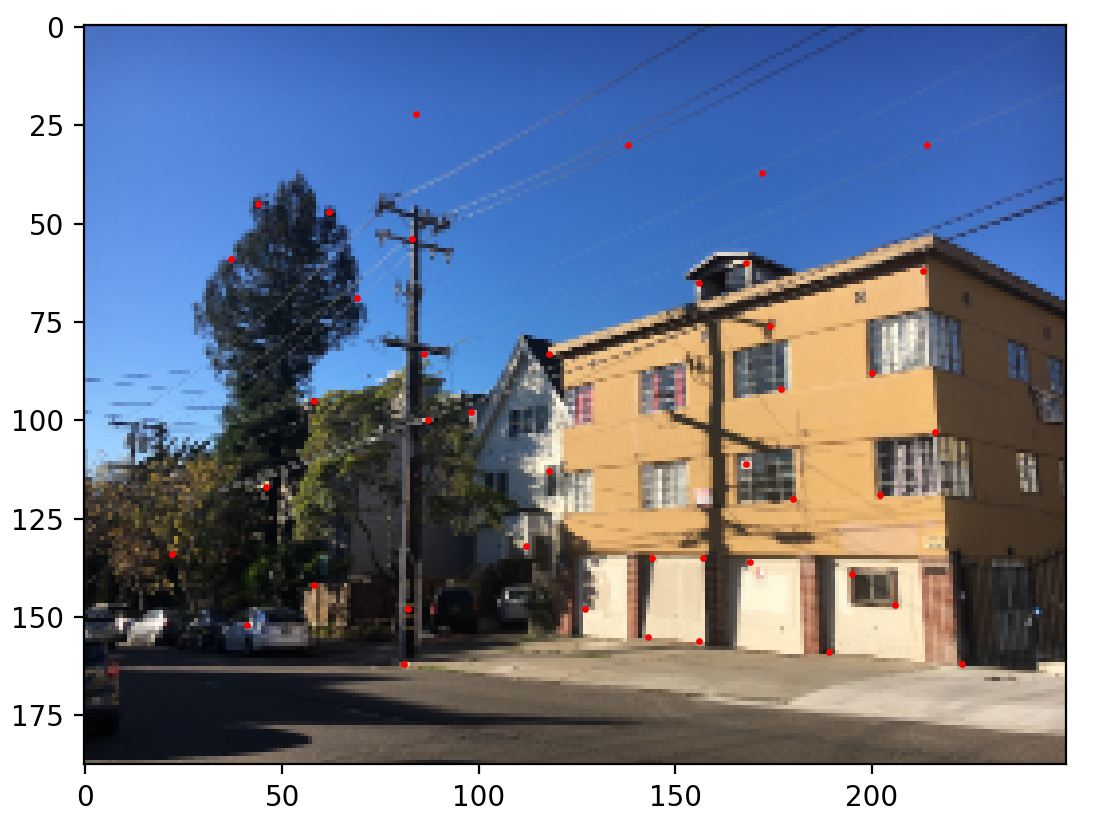
Harris corners (Level 4)
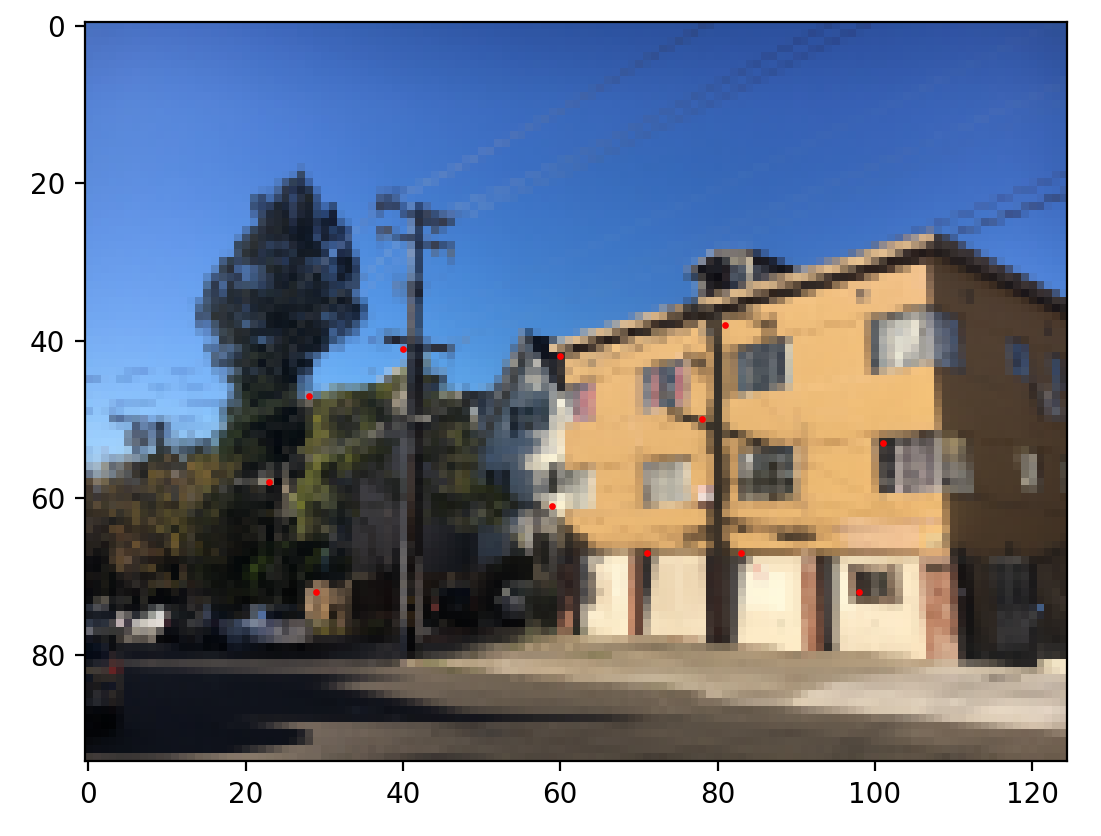
Harris corners (Level 5)
Mosaic with multi-level processing (Cropped)
As another extra, we implement panorama recognition. Given an unordered set of images, some of which might form panoramas, we are automatically discovering and stitching these panoramas together. To do this, we iterate through every possible pair of images given the set of images. For each pair, we go through the processes that we did earlier in the project: we find Harris corners, use AMNS to filter, detect features, and find matching features. In order to determine whether or not this pair of images actually form a panorama, we check to see how many features actually match between them. If the number of matching feature is higher than a certain threshold, we determine that they can be stitched together into a panorama and add the tuple to a list.
Here are the input images we fed the recognition algorithm, in the order we passed them in:
flowers_1.jpg
street_2.jpg

smiley.jpg
street_1.jpg
flowers_2.jpg
Here is the list of recognized panorama tuples that were returned:
[('flowers_1.jpg', 'flowers_2.jpg'), ('street_2.jpg', 'street_1.jpg'), ('street_1.jpg', 'street_2.jpg'), ('flowers_2.jpg', 'flowers_1.jpg')]
And finally, here are the panoramas generated from each of the recognized panorama tuples:

('flowers_1.jpg', 'flowers_2.jpg')

('street_2.jpg', 'street_1.jpg')

('street_1.jpg', 'street_2.jpg')

('flowers_2.jpg', 'flowers_1.jpg')
Analyzing these results, we can see that we were actually able to recognize the panoramic images. One interesting thing to note was that we were able to recognize both orderings of a pair of images. In our original panoramas, we arbitrarily chose to align the left image to the right image. However, with our recognition algorithm, we create a panorama with the right aligned to the left as well as the left aligned to the right.
As far as limitations go, one obvious one is that this only works for 2-image panoramas; it can't pick out three or more images that are part of the same panorama. Also, we have to use the same thresholds for feature detection and matching for all of the images. If some of the images were very different contrast-wise, we might run into trouble picking thresholds that would work correctly for every image. But, for our purposes, this version is good enough to work!