Overview
This project is based on the work in Texture Synthesis Using Convolutional Neural Networks [Gatys et. al. 2015] and Image Style Transfer Using Convolutional Neural Networks [Gatys et. al. 2016].
In this project, we take a painting or a pattern image, and map its style onto another photo. To do this, we used a pre-trained convolutional neural network (CNN), to extract low level features from the images. We start with a random noise image, and use gradient descent to get a desirable output image, by comparing its network outputs at specific layers to the outputs of the input style and content images. You can see examples of this in the last section.
Getting VGG Network Output
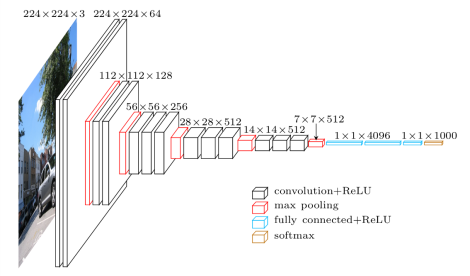
We downloaded a pre-trained VGG-19 network. The network architecture is displayed below. Empirically, we found that using conv1_1, conv2_1, conv3_1, conv4_1, and conv5_1, for style comparison, and conv4_2 for content comparison works best, however, more desirable results can be obtained by tweaking these layers slightly. The images in the results section were generated using these layers.
If we were using the VGG network for image classification, we would need to scale our images to be the scale [224x224x3]. However, since we are just taking the outputs of just the convolution and max-pooling layers, we can pass in any arbitrarily large input image. Only the fully connected layers require a specific input size.
Loss Function
We define the loss to be some weighted combination of the style of one photo and the content of the other. By using the Deep Neural Network, we can extract low level features of the style and content images in order to define the similarity of our current input image and the style/content images. In the following equations, F_l represents the output of the network at layer l.
Typically, we chose the values: alpha=0.5, beta=7000, gamma=10.

The content loss is defined as the Squared Difference between the output values at different layers. By tweaking which layers the content loss used, we could change how prominent the original content image was.

The style loss is defined similarly as the content loss. However, we want the style to not incorporate regional information. We therefore take the Gram matrices of the N_l feature maps at each layer.

The Gram matrices in essence capture how correlated one feature is with another, without enforcing they appear in the same location. We then define our style loss to be the Squared Difference between the Gram matrix of the noisy image and the style image.

The Total Variation loss simply reduces noise by penalizing variations from neighboring pixels.

Initialization
Random Normal Initialization
Our initial attempt was to take initalize the input to train on as random noise. In essence this would allow for both new content and style to develop by themselves. At first this worked well for simply generating new styles without any content(alpha set to 0), but this quickly broke down when we added in content. We increased number of iterations for our images however the gradient descent optimizer got stuck in local optima leaving noise in our images. Here are some results for what Random Normal Initalization looks like.
Content Image Initialization
To combat the issue of a lot noise entering our images when adding in the content, we thought it might be cool to initialize our starting image as the content image itself, this way the optimizer had a decent start point for it to just start adding the style into the content image. This resulted in much less noise as it was very easy to put style into the image than to have both the style and the content approach the appropriate image. View some of the results of changing the initialization.
Initialization Comparison

|

|
Training
In the following gifs, we save the output after every 100 iterations. As you can see there's a big jump after the first 100 iterations, and slowly it decreases the rest of the noise.

|
|
Results
 |
 |
 |
 |
 |
 |
 |

|

|

|

|

|
|

|
|

|

|

|

|

|

|
|
|

|

|

|