 A
A
 A'
A'
Given an image A, a related image A', and a new image B, our goal in this project is to be able to compute an image B' that is related to B in the same way that A' is related to A. This concept will be referred to as an image analogy.
The process of generating image analogies consists of two stages. The first is a learning phase, in which our algorithm takes in two images; one of these images is a "filtered" or somehow adjusted version of the other. We compute a relationship between these two images in this step. The next stage is the application phase, in which the learned relationship is applied to the target image to generate a correspondingly modified version of it. This change is be analogous to the change demonstrated between the two original inputs.
The image analogies algorithm works via a computational photography analog of the grade-school A:A'::B:B' paradigm. In words, it is of the form "A is to A' as B is to B'."
Input images A, A' and B are provided as inputs, and the algorithm learns the relationship between A and A' according to a specified feature space, attempting to apply this same relationship to B and a newly generated B'. More exactingly, image pyramids (with subsampling rate 1/2) are generated for the three inputs as well as a corresponding pyramid for B' (initialized with all 0s). Then, we fill in each pixel in B' via a BestMatch procedure, which matches the best feature from A' and uses the relevant feature components from this match to synthesize the new B' pixel. Each feature is specified as the concatenation of some component(s) (e.g. RGB, luminance, etc.) from the pixel in question and the 5x5 window of pixels around it and the 3x3 window of pixels from the lower-level pyramid, as well as the windows from the corresponding related image (A and A', B and B'). Naturally, we omit unfilled pixels in B' from this representation.
In this manner, feature vectors are constructed for B/B' and compared to the feature vector for each pixel in A/A'; the elements of the best match are selected for transcription. BestMatch selects this match via a synthesis of approximate matching and coherence matching - approximate matching has the goal of selecting the pixel in A' that has the closest feature vector to the corresponding pixel in B' (done via ANN), whereas coherence matching tries to maximize the "flow" of the image as something human-interpretable and in correspondence with B. The selection between the two pixels matched by these subroutines is done via a weighted comparison, whereby the weight is a tunable hyperparameter whose value is specified depending on the type of filter / other image technique we are trying to apply. Once the BestMatch procedure determines a match for all pixels in the top level image pyramid for B', the synthesis is complete.
There were many different challenges that arose when attempting to perform this task. Given A, A', and B, we want to generate a B' that presents a balance between 1) the features present in B, and 2) the relationship that maps A to A'. This proved do be difficult when A and B were very dissimilar images, as was often the case; we encountered a wide array of color and composition differences between pairs of A and B images. In order to address this, we ended up testing different values of k, our coherence parameter, for each of our outputs. k dictates how much our algorithm favors coherence (correspondence with neighboring pixels in the output) over accuracy (the closest matching pixel found while iterating through the image). If the parameter is skewed too far in the direction of coherence, then our output image would look too different from the input to be considered a proper analogy. However, if the parameter is skewed too far in the direction of accuracy, then the output image would have many disjointed patches. For each B', we went through extensive tests with different k-values to determine a proper balance.
Next, we realized that feature matching using pixels' RGB values wasn't always the best idea. Especially for A/B image pairs that contained very dissimilar colors, our algorithm had issues finding "correct" matches. To address this issue, we remapped our images for some of our inputs from RGB to the YIQ color space, in which the Y channel represents luminance. Then, we utilized just luminance as our distance metric for BestMatch, which had two benefits. The first was our best matches seemed perceptually closer than those returned using RGB, due to how our eyes are more sensitive to changes in luminance than to color. The second was that we experienced a non-trivial speedup in our matching algorithm, since our features were now one third of the original size. Once the matching was complete, we mapped the outputs back to RGB to display the results in color. This approach resulted in more ideal outputs for the blur filter, oil painting texture transfer, and the watercolor painting texture transfer images.
Another challenge that we anticipated was figuring out what sorts of relationships would be picked up by our algorithm and could be successfully translated. For instance, since pixel relationships were mapped out on a small local scale, we weren't certain whether that would prevent prominent, high-level features from being picked up and translated. However, with the use of image pyramids, we were able to map out relationships starting at smaller scales and increasing in resolution from that point on. In this manner, by using smaller versions of our input images to start, we were able to extract strong relationships at lower resolutions, which translated to larger features when extended to larger pyramid levels.
One more challenge was making sure that our algorithm was able to run in a reasonable amount of time. The procedure we envisioned involved first going through all of the pixels in A and A' to learn the correspondences between them. Then, we would go through all of the pixels in B and search for the best match for each of them. This procedure could clearly become computationally expensive quickly, which would be an issue when testing and generating results. Ensuring that we used NumPy's vectorized computation where possible resulted in some speedups. Additionally, the YIQ luminance remapping described earlier was helpful as well.
Our first tests involved using traditional image filters that we tend to see in picture editing software. The first of these is a blur filter. We applied this blur filter to a photo of a banana to get A and A'.
Then, we applied this to a new image B to get B'.
This was the very first image that we tested our code on, and it was apparent from this point on that adjusting our hyperparameters would have a large impact on our outputs.
The following is an example of the synthesized output with a k-value that is slightly too low. You can see that there are some artifacts around the horizon, where the algorithm prioritized accurate pixel matching from the original image B instead of matching the surrounding blurred pixels in B'.
This was the other traditional filter that we applied to our image. We used a photo of pizza for our A, then applied the emboss filter in Photoshop to generate A'.
Then, we applied this analogy to a new image B to get B'.
This output is pretty solid. We can see the outline of the dog's features represented. However, one difference between A' and B' is that A' has higher contrast levels, which results in stronger black and white edges in A'. B' is more gray overall, which makes some edges harder to discern. This could be a result of coherence matching, which would attempt to keep neighboring pixels in B' similar to each other, thereby reducing overall contrast in the image.
In this example, we first applied an oil painting texture to an image A to generate A'. This made the details in the image swirl into each other.
Then, we applied this analogy to a new image B to get B'.
This was one of the more challenging outputs to create. We had to play with a wide range of k values to reach this point. The issue was that outside of a very narrow range of values, we would end up with a pretty incomprehensible B' that didn't match B. One of the reasons for this may have been that there is a pretty cluttered background in this image, with varying levels of luminance and focus, that could have thrown off our matching algorithms.
In this example, we applied a watercolor painting texture to an image A to generate A'. This had the effect of separating gradients of color into segmented, homogenous blocks. It also hid some of the minute details in the image and seemed to accentuate shadows.
Then, we applied this analogy to a new image B to get B'. Our first few naive attempts were not that successful, which was due to the fact that watercolors tend to contain large, broad brush strokes. These high-level image features did not seem to be picked up by our algorithm particularly well, since the matching process only considers pixels in the immediate vicinity and not those further away. However, as explained earlier, the implementation of image pyramids gave our algorithm the abilitiy to properly observe and transcribe these smaller features.
We were very pleased by this output. It matched the features of A' very well while maintaining a very close similarity to B.
In this example, we took a real-world image and made that our A', then made a simple blockish painted version of it that distinguished between the main textures of the image. This simple version became our A.
Then, we constructed a differently painted version of A to generate some B. The goal was to take B, which contained the locations of different textures, and apply the corresponding textures to it to create a realistic and coherent output.
This output is pretty satisfactory. Each of the four regions contains its corresponding texture. We see that some textures "leak" into other ones (such as the red flowers on the dark green hills); this arises because we want to keep our output as coherent as possible, which allows for some inaccurate matches to take place.
We also applied our texture-by-numbers algorithm to one of the sample sets of images provided in the paper. The following A, A', and B are from the paper, and we generated B'.
We found that this was a better result than our first attempt at texture-by-numbers. This is partially because there are a larger variety of textures that are more intricately mapped out, which helps hide incoherent imperfections. Furthermore, the use of gradients to adjust the lighting throughout B' makes the output look more realistic.
Overall, we had great fun working on this project. The intuitively simple high-level idea behind the algorithm is natural enough to explain to a small child, and works about as well as some more complex models for a wide variety of problems including filtering, style transfer, texture synthesis and more. We certainly encountered roadblocks along the way, but the results were well worth it!
 B
B B'
B' B' with artifacts
B' with artifacts A
A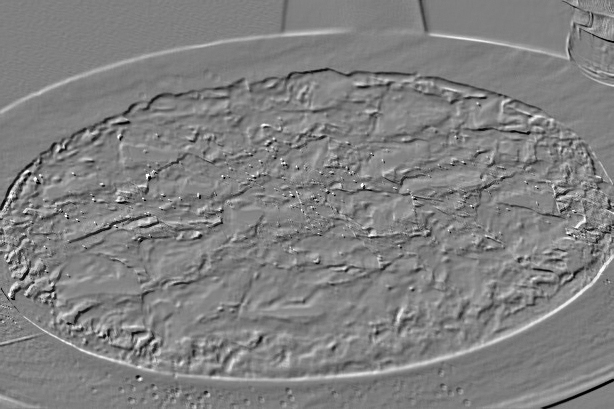 A'
A' B
B B'
B' A
A A'
A' B
B B'
B' A
A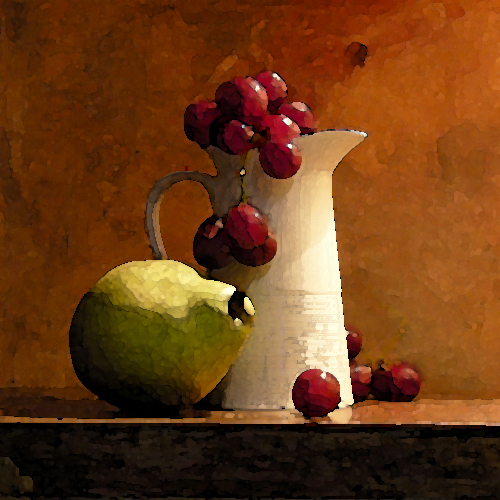 A'
A' B
B B'
B' A
A A'
A' B
B B'
B' A
A A'
A' B
B B'
B'