In our previous project, we did facial morphing based on a number of facial correspondence points that we pre-defined manually. In this project, we will be working on using Machine Learning to automate this process. Specifically, we will be using PyTorch to create Convolutional Neural Networks to
Nose Keypoint Detection
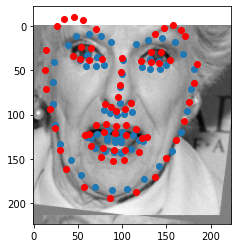
In the first part of the project, we are tasked to predict the position of the nose, the -6th keypoint. Our dataset contains approximately 192 training images and 48 test images. These pictures are in black and white. The architecture of the CNN is a model with 4 hidden layers with (2,2) max pooling, RELUs and a CNN that goes from 10, 20, 30, 40 channels repsectively, convolving with a 3 x 3 kernel. They end up in a 2 layer fully connected network, where the first FC is followed by a ReLu. The reason for the small Kernels is because I thought the pictures were already resized to be extremely small. Below here, we see three examples of sampled images from my dataloader with the ground-truth keypoint.





This yielded the following results for bad predictions. The reason is probably that the photo includes more unusual postures in the second picture since they have their mouth open. Additionally, on the left picture, the person's head is tilted a little downward. This makes that the shadow/pointy object closest to the center is his cheekbone hence it being classified as the nose.


Facial Keypoints Detection
The second part of the project involved creating a facial keypoint detection algorithm. Here we were tasked to create a detection algorithm for all of the keypoints on the smaller set. One of the differences with the previous part is that data augmentation has been performed to increase accuracy. The following augmentations have been added:- Randomized Rotations between -10 and 10 degrees
- Uniform odds of mirrored image
- Translations from -10 to 10 both in the x and y dimensions
- Brightness noise (Normally distributed with mean 0 and sd 1/256), also known as Jitter


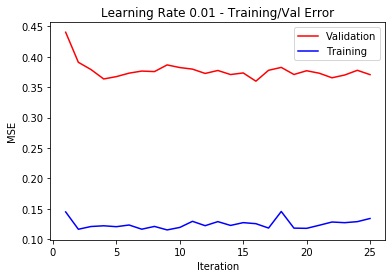
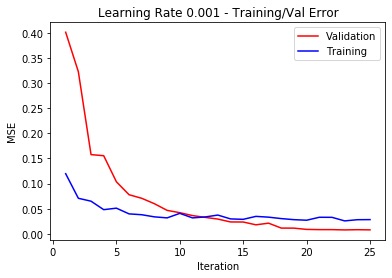
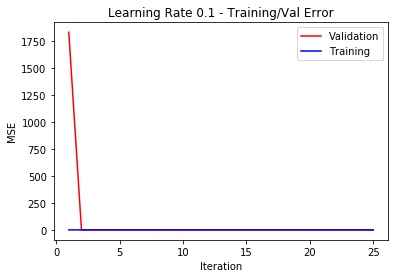
The architecture of the CNN has been established through trial and error. First, I created a six hidden-layer Neural Network followed by two fully connected layers. Each hidden layer used to have a maxpool (2,2) and a ReLu. The convulution themselves had a kernel size of (7,7), (5,5) initially and the rest being (3,3). This however, did not turn out great since the output values for the last FC layers had a small dimensionality. I removed the sampling from the last three layers. The output sizes of each layer being 40 to 60, 100, 120, 140, 140 respectively with kernel sizes of (7,7) for the first layer and (3,3) for the rest. This finally yielded best results with train MSE of ===Train MSE=== 0.000177. The learning rates have been swept through a range of [0.00001, 0.0001, 0.001, 0.01, 0.1], and I manually determined that an alpha of 0.001 yielded the lowest MSE. The final used hyperparameters are 0.01 learning rate, a 2 batch size (since the dataset is small anyway and have turned out to give best results) and Adam as optimizer.
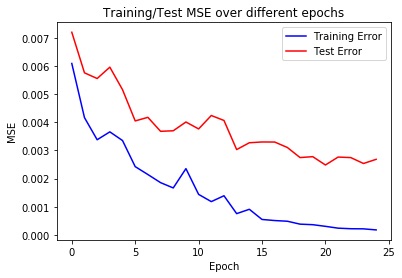





Full Training Data: Facial Keypoints Detection
Please note that from this point onward, I decided to use the MAE (L1-loss) since we are optimizing for that in the Kaggle competition. Additionally, since I jumped from part (i) to this part, I had not normalized the points and therefore the loss values are in a significantly higher order. For the last part, I used a ResNet18. Residual Nets are basically Neural Networks that make hops from layers to layers and skip certain hidden layers. The specific, kind that I implemented is the standard ResNet18. The benefits from ResNets is that they essentially simplify the network and use the few layers in the initial training stages.MAE Reported (Kaggle): 26.869 (alpha = 0.1)
The following plot shows the sweep: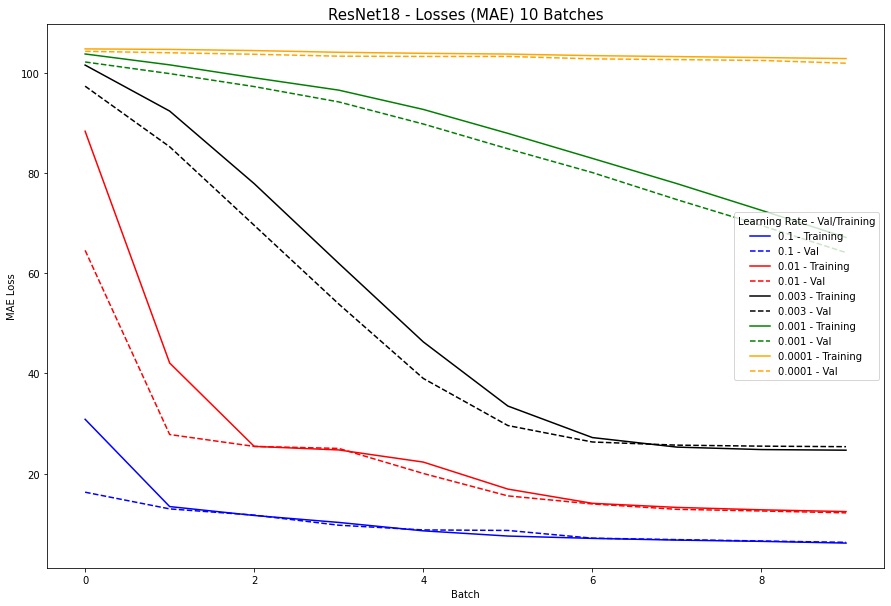
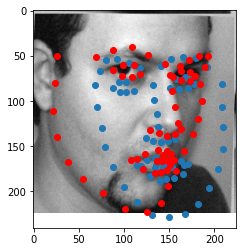
The following sample yielded the following results: It seems like that it generally is good at detecting faces and where the eyes are at. However, with the 10 epochs, it is still not perfectly able to distinguish the shape of the outsides of the face. Additionally, it is significantly having difficulties with many sideways pictures where heads are asymmetrical due to non direct perspectives. Additionally, the beard might have influenced the ResNet as well.


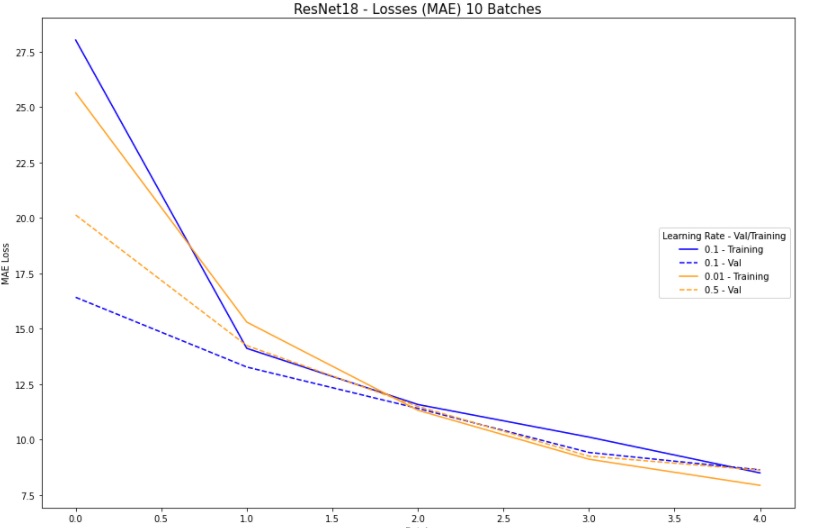
Bells and Whistles: Blurpool
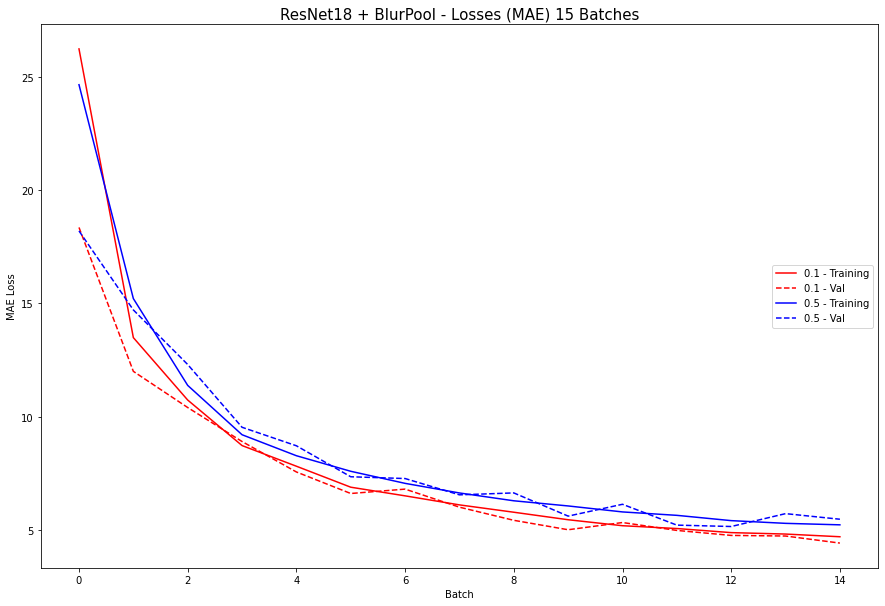
Instead of using maxpool that is being used in the ResNet18, I have decided to substitute the layer that uses MaxPool with BlurPool. BlurPool basically creates some kind of blurring before it samples which prevents aliasing. The results were significantly better. I used the hyperparameters from the neural net before this (0.1) and also 0.5 (since they showed same stabilizing behavior) and it yielded the following results"This provided the following training/validation error plot:
Let's sample and plot the results: