



Sample ground truth images from dataloader:
Loss plot:
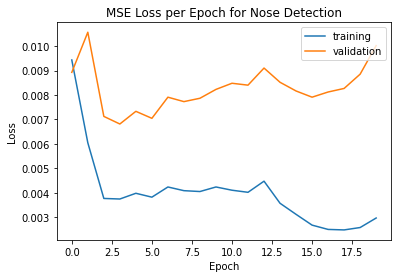
The validation loss is significantly larger than the training loss, but given that they move similarly and the dataset is small in the first place, I don't think there is too much overfitting going on.
Predictions vs ground truth:




Of the sample prediction vs ground truth outputs shown above, the first two are predicted poorly, but the next two do well. This is likely because the last two have a more common face orientation and expression, whereas the first two have an open mouth and a look to the side, respectively.
This works basically the same as Part 1, but with more points in the output and a slighty more complex architecture to support it.
Some ground truth examples:
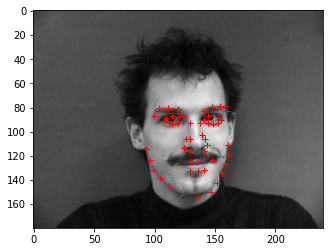



Architecture:
Predictions vs ground truth:




The first two images above are annotated poorly by the network. In the first image, we can see that the left jaw (left side of the image) annotation does not rest on the jawline. This may be due to the strong shadows on that side of the face. In the second image, we can see that there are many predicted points spread seemingly at random across the left side of the face. This may be due to the large angle at which the subject's head is turned; we can see that many of the ground truth annotations on the right side are very clustered together, moreso than in other "turned face" images such as the first and third. The second two images are annotated pretty well. Interestingly, they are original, non-augmented images.
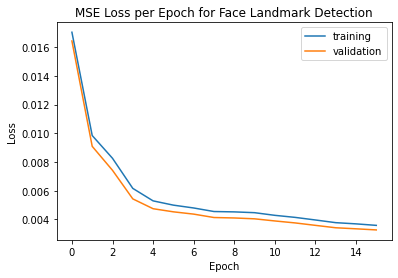
Loss plot:
Visualizations of filters from the convolutional layers of the network:





Most of the filters don't look like much of anything, but some look like edge detectors or similar.
I only loaded 6666 total images, each a perturbed version of an original image, due to memory constraints (I chose to load them all at once here rather than on-demand in the DataLoader because I found it was faster for me overall). Annotations were adjusted based on the perturbations (rotation/shifting), but the bounding box was just enlarged to encompass all the (perturbed) landmarks. This means that it likely includes some extra area, e.g. if the face was perturbed downwards, the upper edge of the bounding box would stay where it started. I also widened the boundaries by 0.9 (top/left) and 1.1 (bot/right) to give some buffer zone around the landmarks.
The test results look pretty good, with a Kaggle score of 12.06207 under leonxu1. For the model, I used non-pretrained ResNet18 with the first and last layers input/output size adjusted accordingly, trained for 20 epochs on the 6666 perturbed images with a learning rate of 5e-3 and a batch size of 4. The results could probably be improved by using a properly augmented dataset of more than 6666 images, which may slow down training as it would require on-demand loading instead of preloading. The bounding boxes could also be fixed to better move with the perturbations of the training dataset, and the 1.1/0.9 multipliers probably don't scale evenly on the two sides of the image.
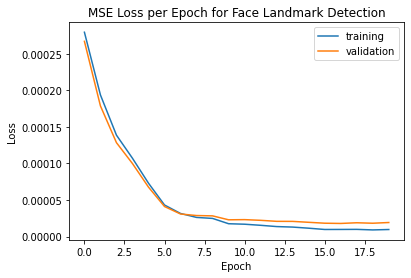
Loss plot:
Example predictions on test data:




These look pretty good. Test data bounding boxes were scaled by 0.85 (top/left) and 1.15 (bot/right) to make sure the face was fully included with some buffer area, similar to the training data.
Example predictions on my own images:


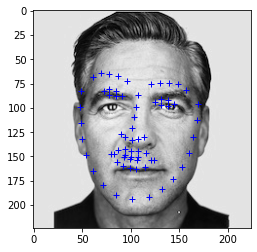

These also look pretty good, even the one on my dog.