In this project, we attempt to detect the positions of a set of facial keypoints with neural networks in PyTorch.
After writing the data loading logic, I want to quickly check that it's working. Below is a sample of the dataset with the ground-truth nose keypoint.

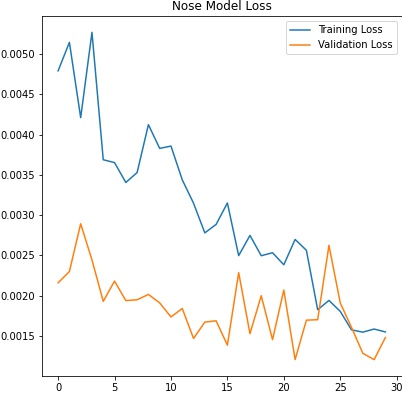
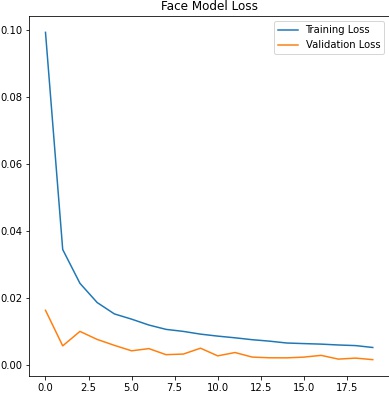
Many iterations of training later, I observe that my training and validation loss are both to my satisfaction. I could have probably trained for more epochs to achieve more stability.
Below is a visualization of a few samples from the validation set. As you can see, the model result is quite close in most cases, especially when the subject's face is front-facing. One extreme example of an inaccurate label can be found in the third row, left image. I suspect the error here is at least partially due to the subject's lack of a hairline, as well as the angled position of their head.

Like before, I want to quickly check that data loading is working. Below is a sample of the dataset with the ground-truth nose keypoint. Note that this dataset is augmented, with 5 differently angled versions of an image for each original.

After 20 epochs, I observe that my training and validation loss are both relatively stable. The model architecture is as follows:
Each of the conv layers is followed by a relu layer and a max pool layer of size 2x2. The exception is the 5th conv layer, which is not followed by a max pool layer. Additionally, the first dense layer is followed by a relu layer and a dropout layer with p=0.4. The latter is to help prevent overfitting, and I saw that it worked quite well.
Also, I used a batch size of 8 while training and a learning rate of 0.0001.
Below is a visualization of a few samples from the validation set. Similar to part 1, the model result is most accurate visually when the subject's face is front-facing. Interestingly, the same bald subject (row 4, right image) also has the worst results in this part. As before, I suspect the error could be due to the hairline, as the data does not represent his baldness very well. Another failure case is the second-to-last row, left image. This person's mouth was open, which I suspect is partially why the predictions for the jawline are completely off.

Now, let's see how the filters look in the first conv layer.
Quickly check that data loading is working. This dataset is augmented less than the dataset in part 2. For each original image, we create 3 different rotations.

After 9 epochs, my training and validation both seem to flatten out. The model architecture is essentially resnet18, with small modifications to fit my input data and output size. Resnet18 consists of a series of conv layers with filters of depth ranging from 64 to 512, width and height dimensions ranging from 1x1 to 3x3, and strides of 1x1 or 2x2. Conv layers are followed by batch norm layers and occasionally relu layers. Right before the dense (last) layer, there is an average pool layer. The changes I made are the following:
I used a batch size of 16 and a learning rate of 0.0001 during training.
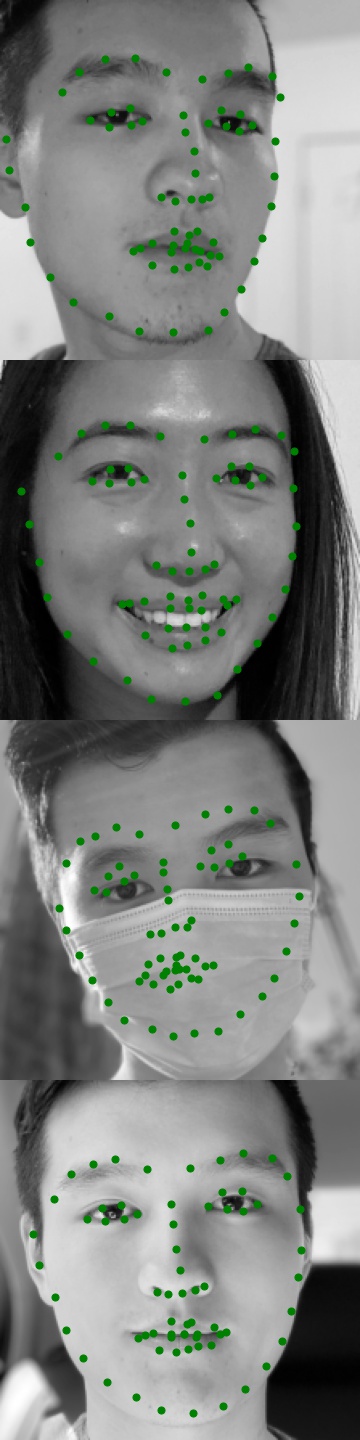
Some visualizations from the validation set, with both ground-truth and predicted keypoints.

Some visualizations from the test set, with predicted keypoints.

Some visualizations from my own photo album. It seems that the model is fairly accurate in these photos, with the exception being the photo where I am wearing a mask. This is to be expected, as the model was likely not trained on any photos of faces with masks. I also tried it on an image of my friend, which also worked well.