CS 194-26: Project 4
Akshit Annadi
Nose Tip
In this part of the project, I worked on training a neural network that would take in an image and output the location of the tip of the nose. Before training the actual model, I first had
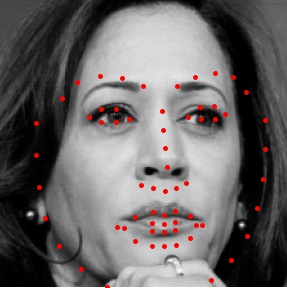
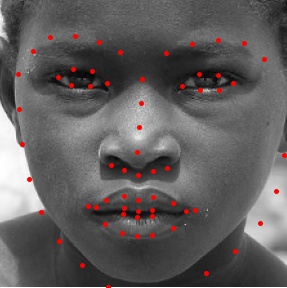
to load the data and ground truth nose tips into the program. Here are some images from the training set along with the true nose tip keypoints(in red).
Once the data was loaded and processed, I had to train my model. The model I used was a 5 layer neural net, with 3 convolutional layers and 2 fully connected layers all using the RelU non-linearity. The model was trained over 25 epochs using an Adam optimizer with a learning rate of .001, and the training loss/validation loss across the epochs is shown below.
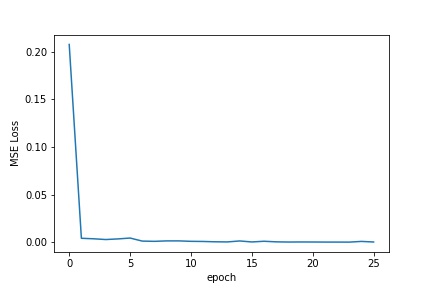
Training Loss across training Epoch
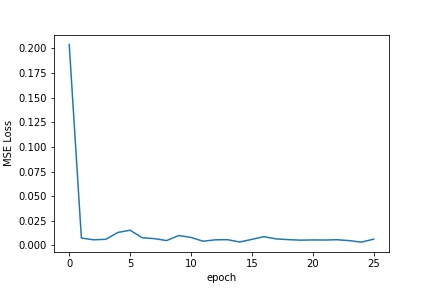
Validation Loss across training Epoch
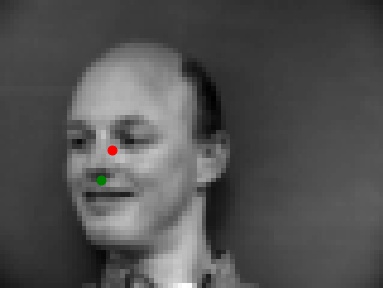
Once the model was trained, I ran it on a few of the images. Here are a couple examples of where the net worked. The original ground truth point is in green and the neural net estimate is in red. The points are nearly overlapping(at the tip of the noses), showing that it worked.
Here are two examples of where the neural net didn't work that well. I believe both of them didn't work because the heads are slightly tilted so that part of the nose isn't visible in the image. Therefore, as the net
probably learned to identify nose tips based on the black space created by both nostrils, it couldn't find the pattern it was looking for.
All keypoints
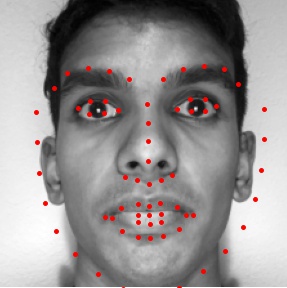
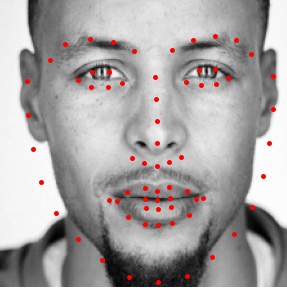
This part was very similar to the previous one. This time, however, I worked on training a neural network that would take in an image and output all the facial keypoints(a total of 58 points). Before training the actual model, I first had
to load the data and ground truth nose tips into the program. Here are some images from the training set along with the true keypoints. Because there was only a small amount of data for a large amount of parameters, I used data augmentation to artificially expand the training
set. The data was augmented by translating and rotating the images randomly, the results of which can also be seen below.
The model that I trained was a 7 layer neural net. The architecture is as follows:
- A convolution Layer with 7x7 filters and 16 output channels, followed by a relu
- A convolution Layer with 5x5 filters and 32 output channels, followed by a relu and a 2x2 maxpool
- A convolution Layer with 3x3 filters and 18 output channels, followed by a relu
- A convolution Layer with 7x7 filters and 12 output channels, followed by a relu and a 2x2 maxpool
- A convolution Layer with 5x5 filters and 16 output channels, followed by a relu
- A fully connected layer that had an output size of 321, followed by a relu
- A fully connected layer that had an output size of 116, which correspond to the 58 keypoints
The model was trained using an Adam optimizer with a learning rate of .001. The training and validation loss over 20 epochs of training are shown below
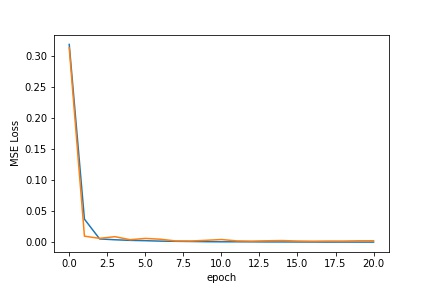
MSE Loss across training Epoch
Validation Loss in orange, Training loss in blue
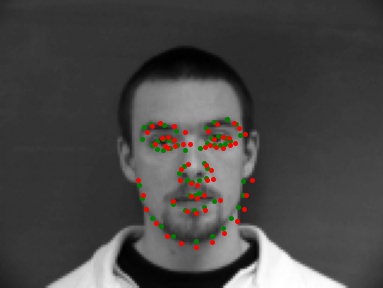
Once the model was trained, I ran it on a few of the images. Here are a couple examples of where the net worked pretty well. The original ground truth point is in green and the neural net estimate is in red. Although it isn't perfect,
many of the points overlap, which shows a high degree of similarity.
Here are two examples of where the neural net didn't work. I believe that they didn't work well because their heads are not looking straight or their heads are tilted. Because of this, some of their facial features are missing(e.g. ears) or skewed. Since most of the
training data was with people looking straight, this probably led to the neural net not finding the features in the faces it was looking for to correctly identify the keypoints.
Here are some of filters from the first and second layer of the trained model visualized:
Large Dataset
This part was very similar to the previous one. This time, however, I worked on a much larger data set(while using the same data augmentation techniques). For this part I used the resnet18 model,
with some minor tweaks(changing the input to take in only one channel and changing the output size to be 68 2D points). I trained this model using an Adam optimizer with a learning rate of .001. The validation and training Loss
during the training process can be seen below.
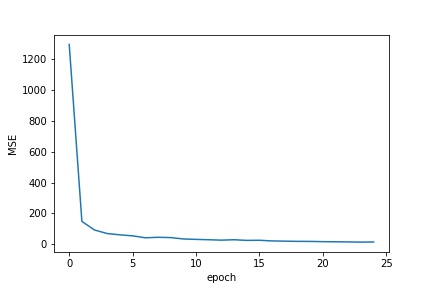
Training Loss across training Epoch
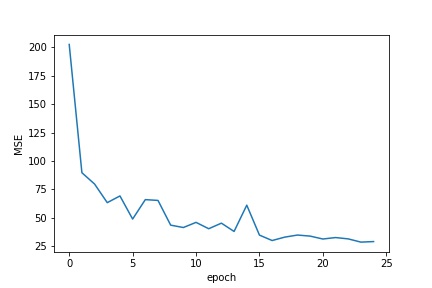
Validation Loss across training Epoch
The MAE of my net on the testing set(as reported on Kaggle) is 11.19812. Below are the visualized results of running the trained net on some of the images from the testing set.
Below are the results of running the trained net on some more images from "my collection". The net worked fairly well on some images but not on others. It seems to work particlarly well on images where the face is looking straight at the camera. It doesn't work
well on images where the face is tilted a lot or turned away from the camera such that facial features are not visible. This is because the net can't identify the patterns that it uses to
guess where the keypoints are.