Part 1: Nose Tip Detection
Below are a few samples of images from the dataloader (i.e. after transformation) and their respective ground truth nose keypoints.
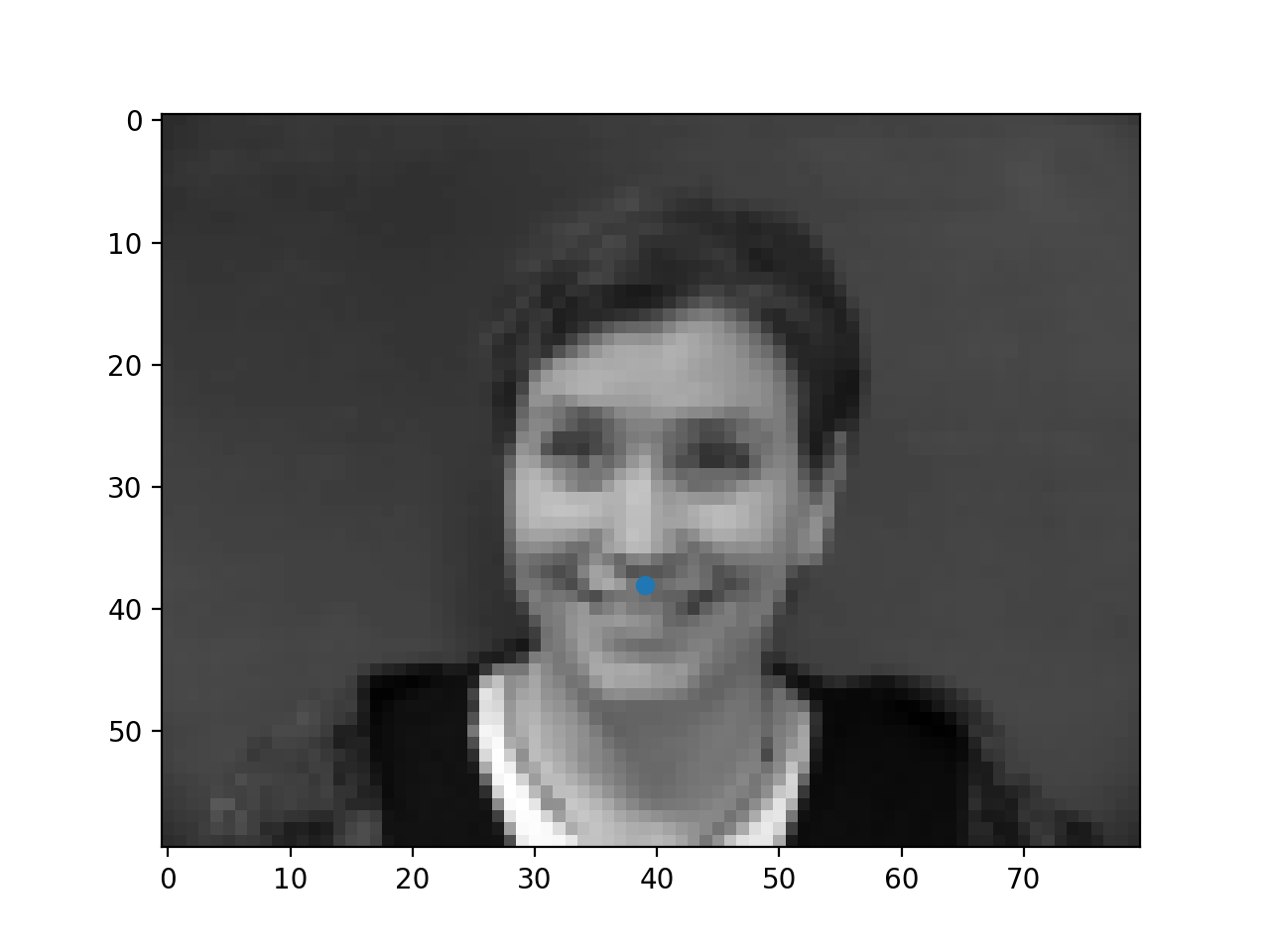
|
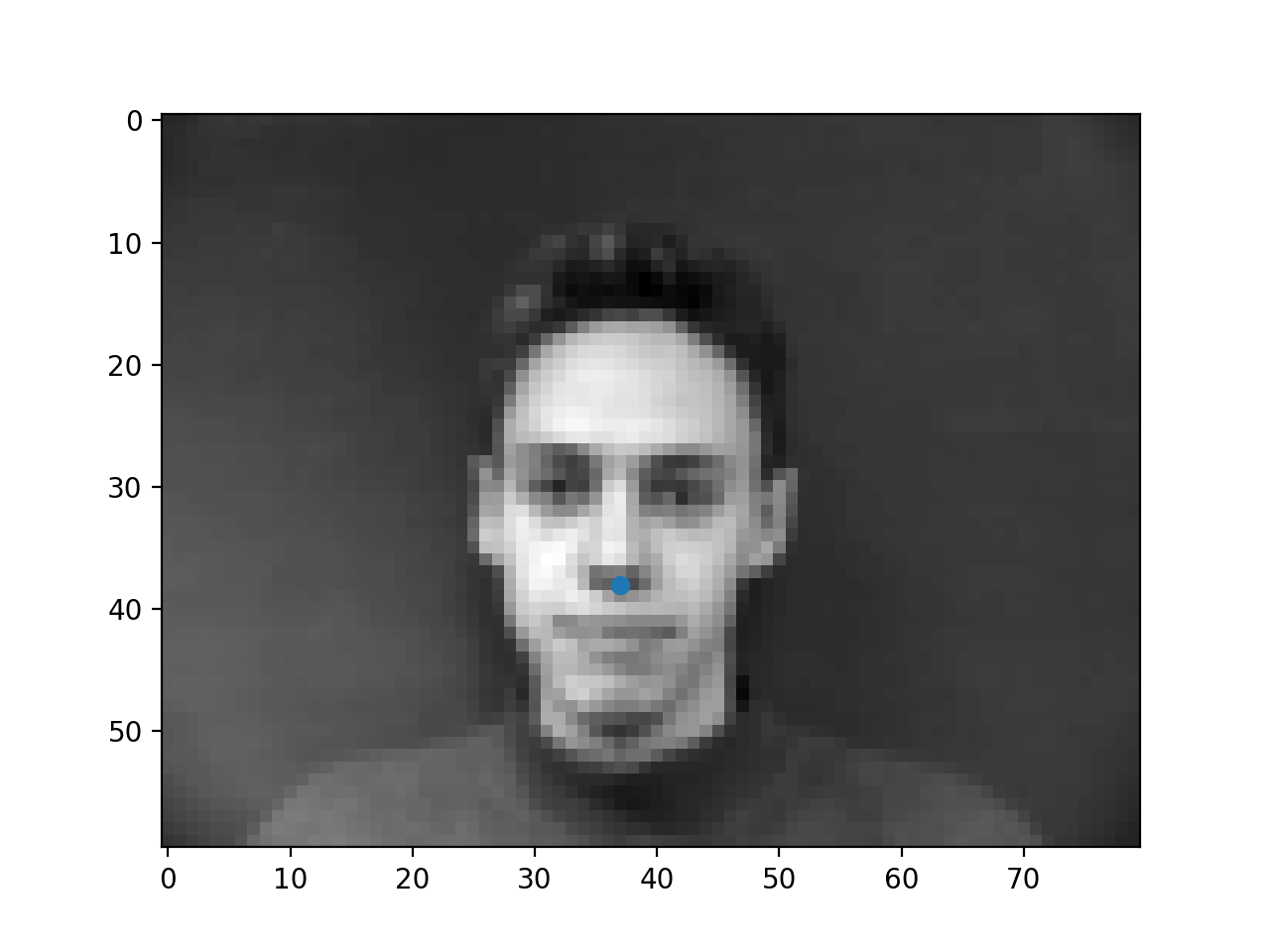
|
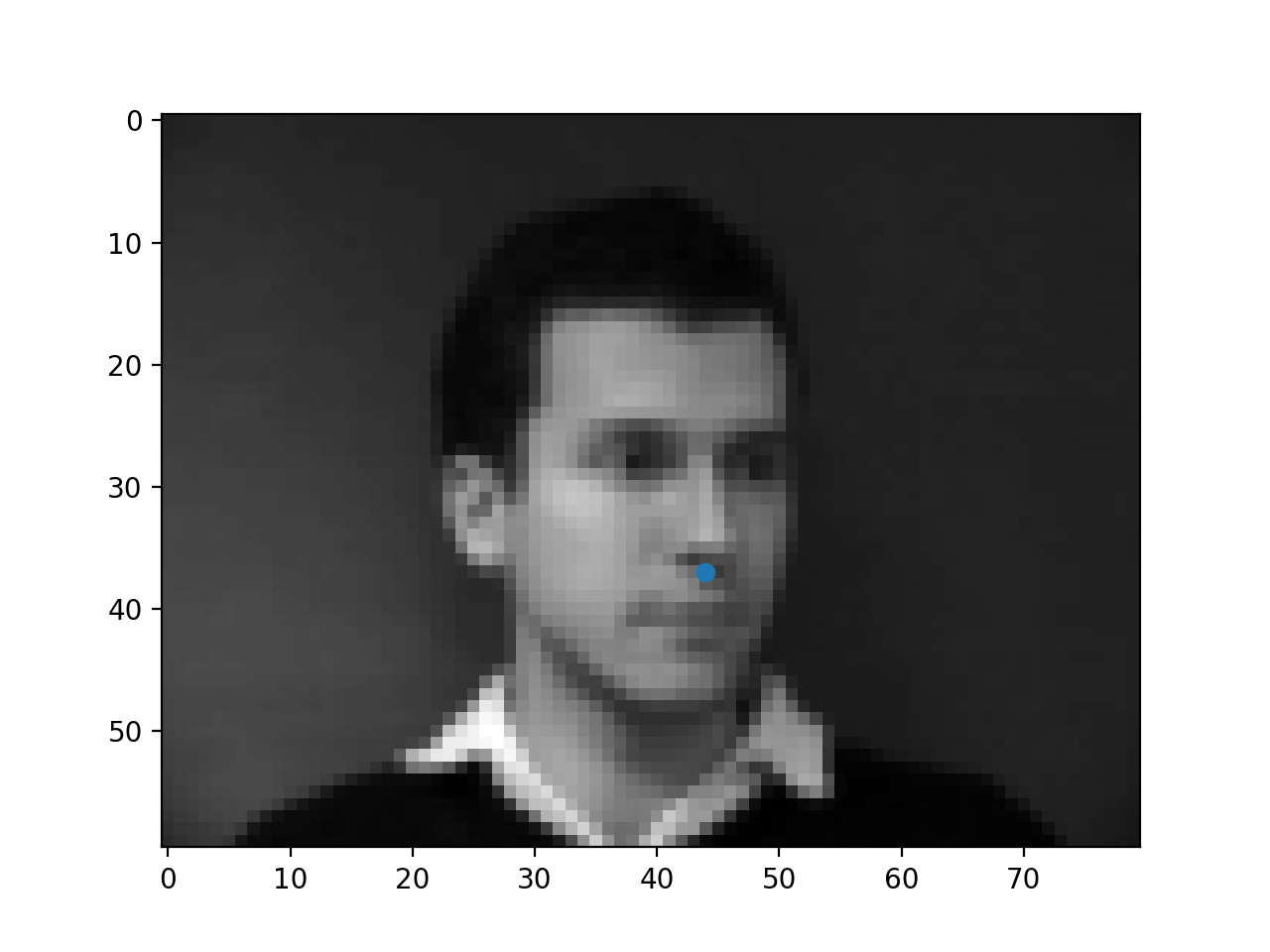
|
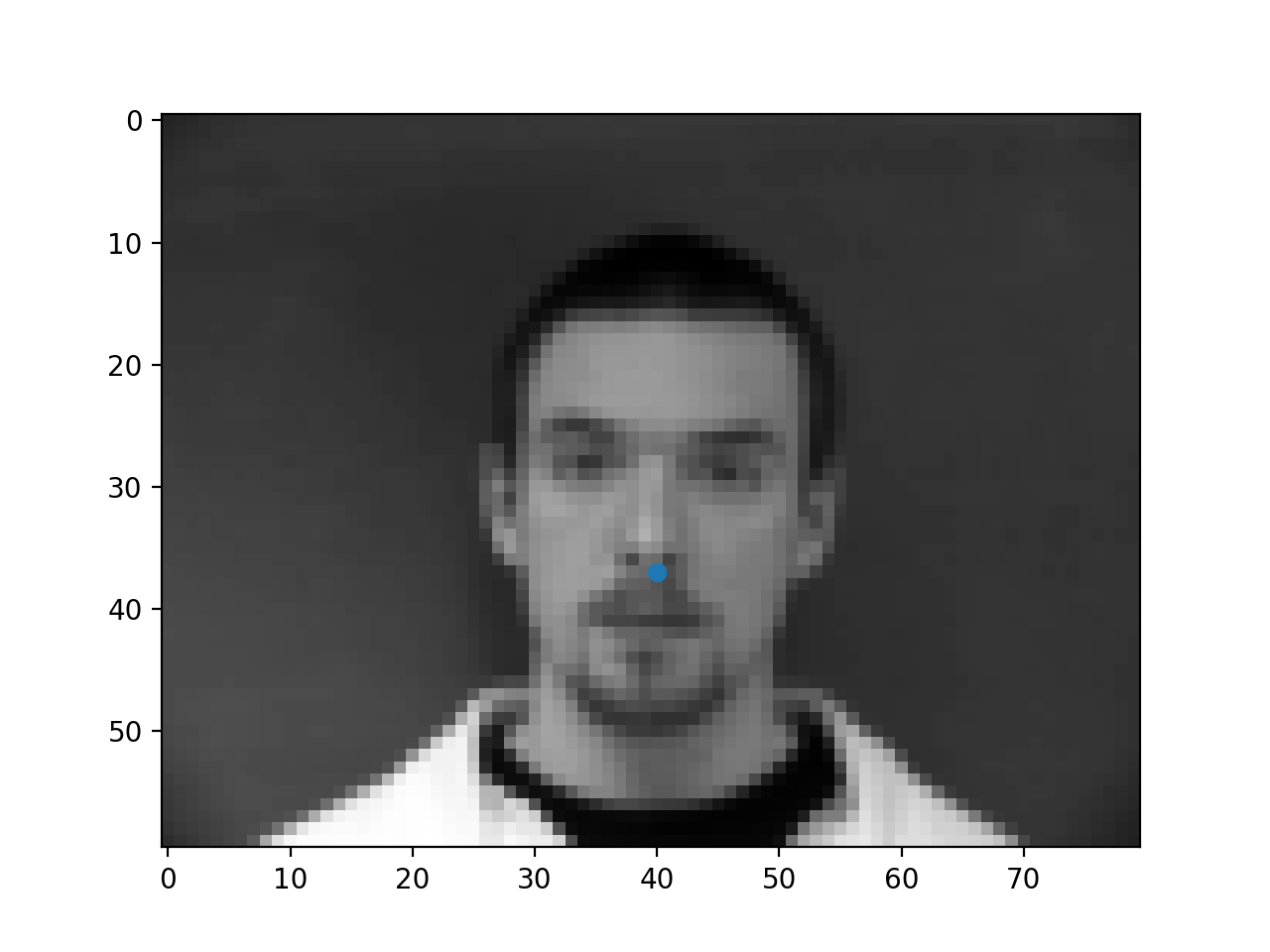
|
The plots of train and validate accuracy are below
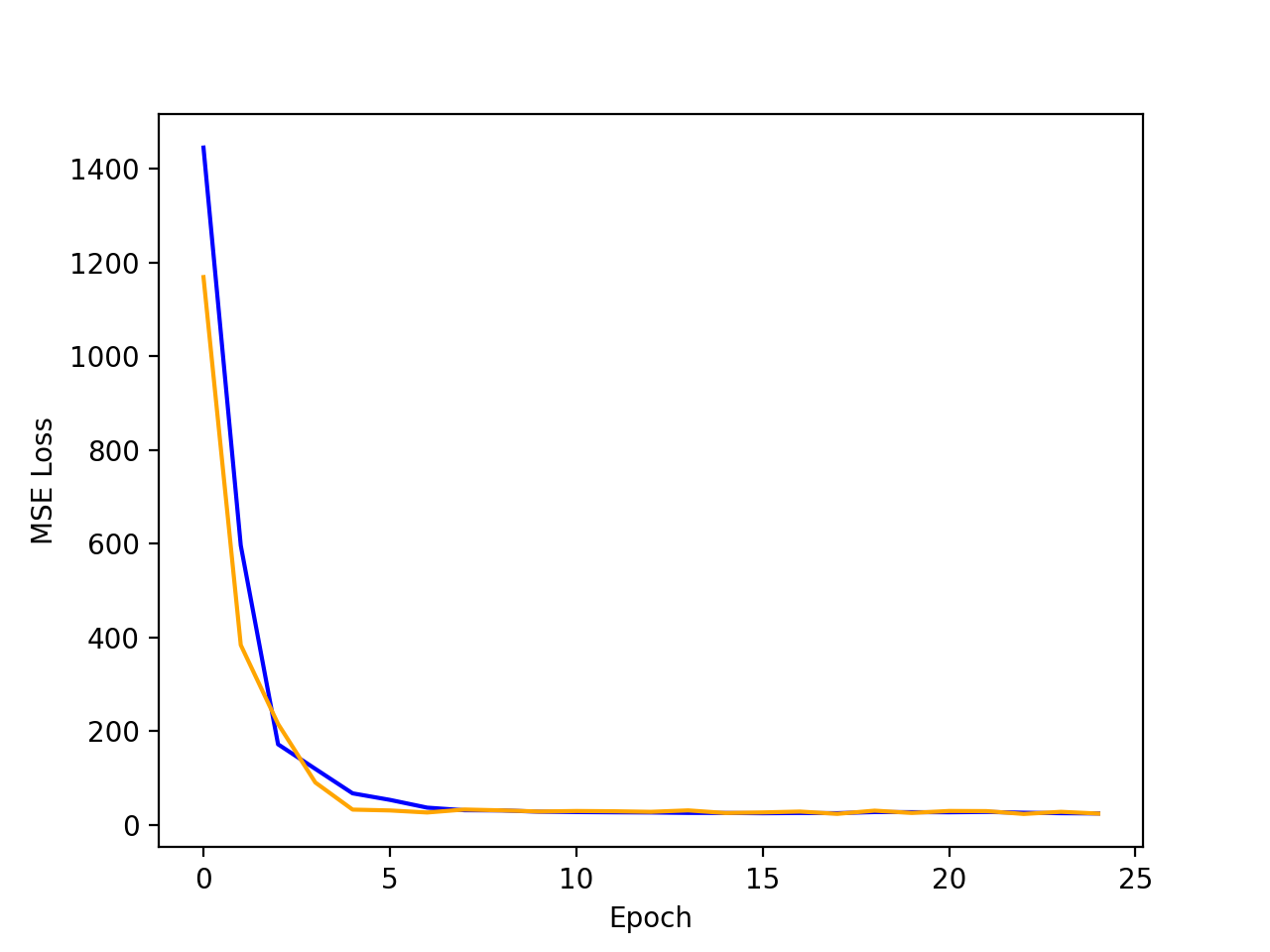
Orange: Validation Loss
Finally, some success and failure cases are below. The failure cases likely occur because the nose is turned or not in the center of the image. Intuitively the model can get good loss by always predicting near the center because this dataset has mostly centered faces; so the model may simply be biased towards the center of the image.

|

|
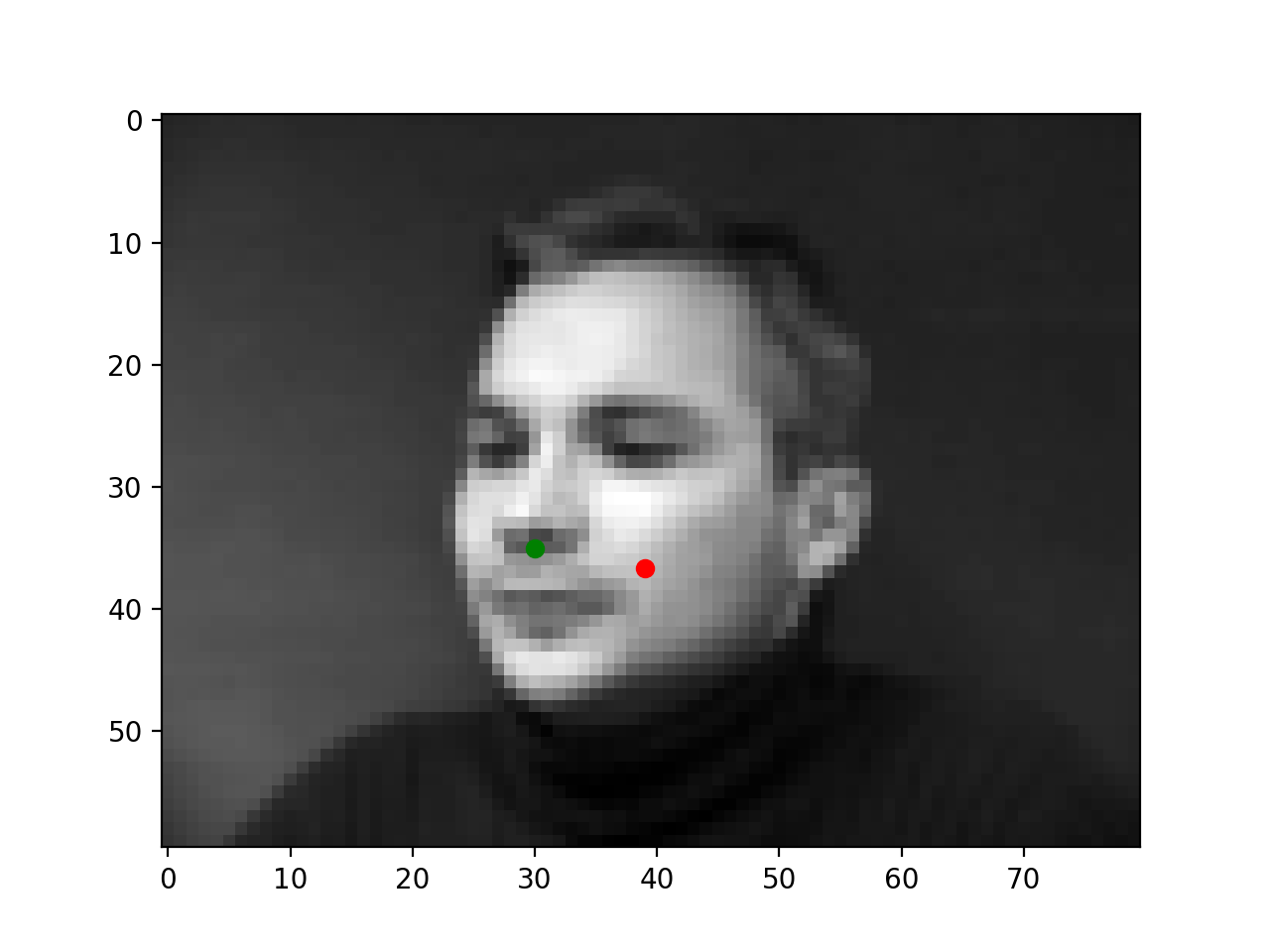
|
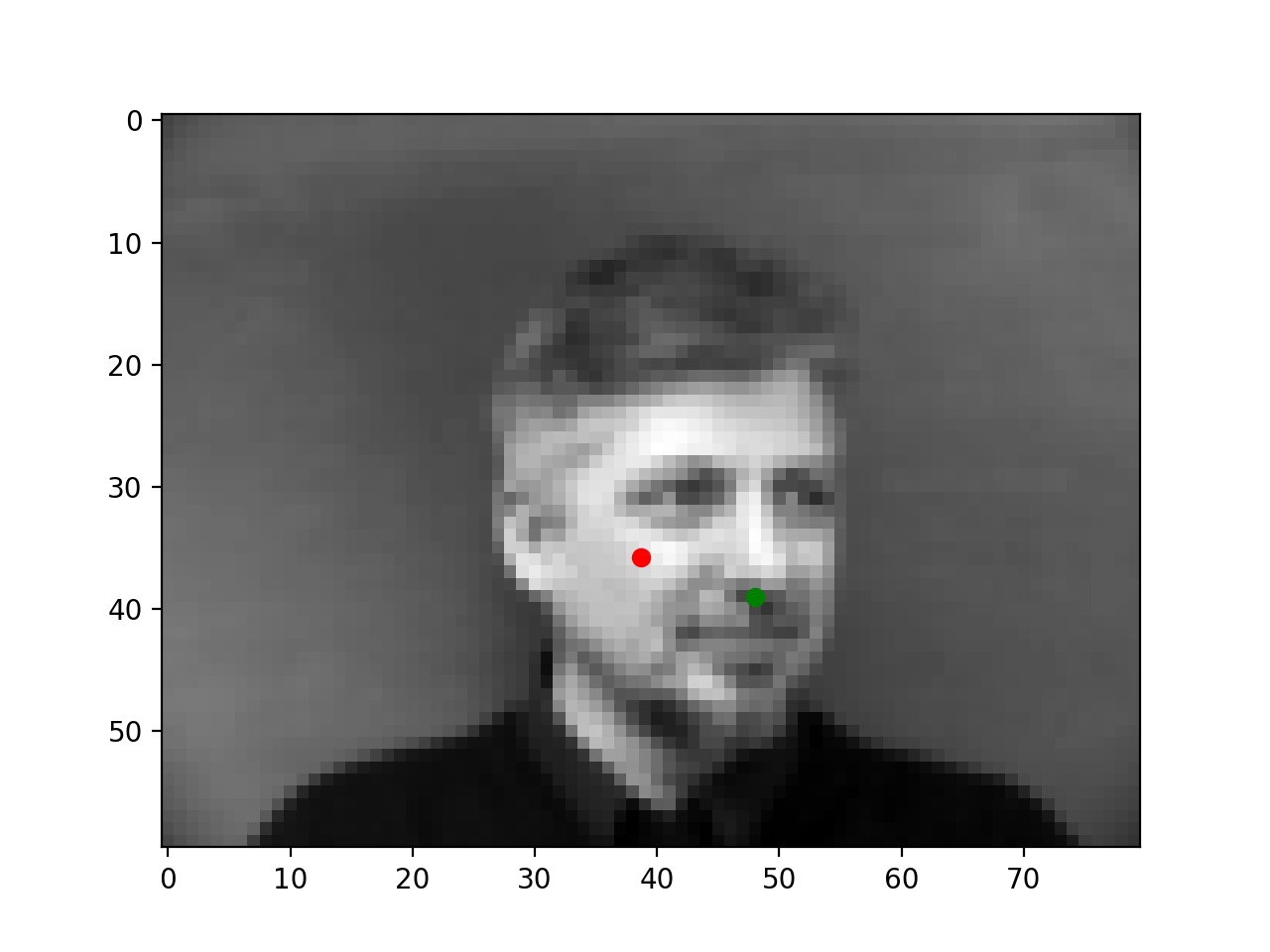
|
Part 2: Full Facial Keypoints Detection
Dataset
Below are a few sampled points from the dataloader

|

|

|

|
As you can see from sample 2, one data augmentation technique I used was to randomly shift the images. In addition to this, I augmented the dataset by applying random color jitter and random flips across the vertical axis.
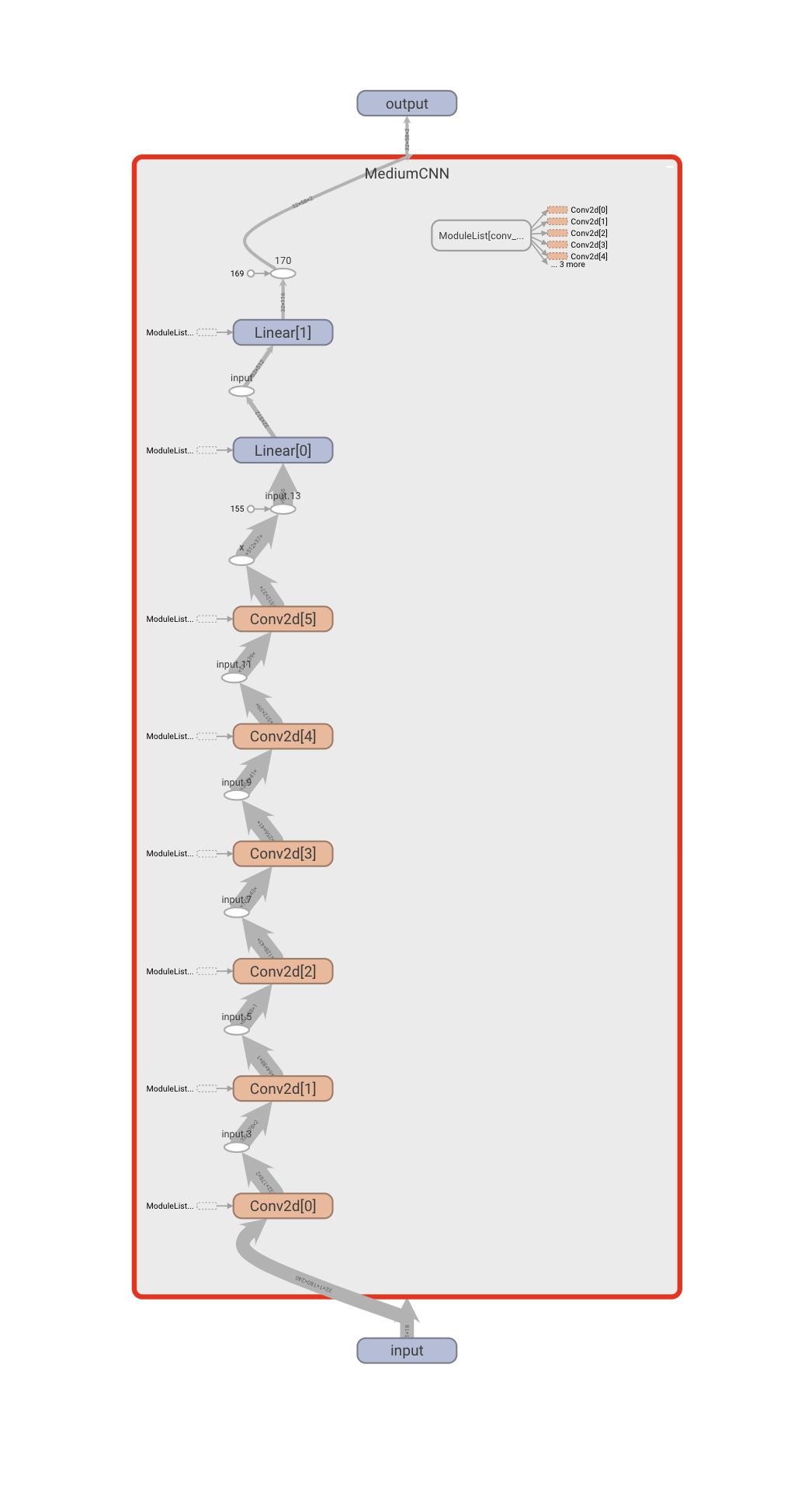
Architecture
The architecture that worked best for the larger problem is visualized below. In specific, I used 6 convolutional layers with $[32, 64, 128, 256, 512, 512]$ output layers respectively. The kernel size of each convolutional layer is $3$. Each convolutional layer is followed by a ReLU, but importantly not a max pool. In order to "learn" the downsampling, I experimented with replacing max pooling layers with convolutional layers of stride 2, which have the same downsampling effect. This lead to a serious jump in performance over the max pooling approach. Finally, the convolutional stack is followed by two linear layers $\in \mathbb{R}^{985088 \times 512}, \mathbb{R}^{512 \times 2}$ respectively.
Finally, the training and validation losses over time are visualized in the plot below.
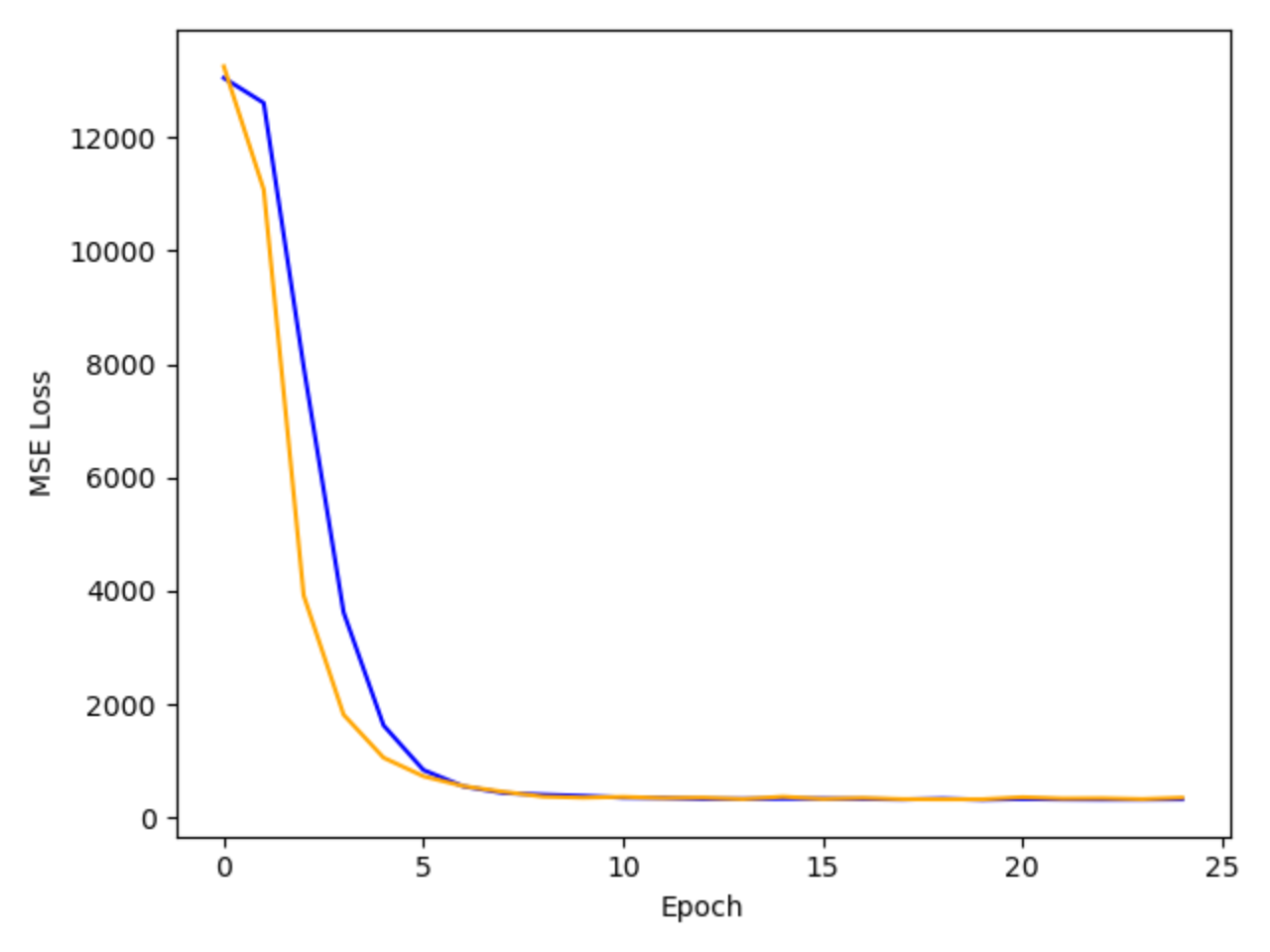
Orange: Validation Loss
Results
Below are two failures and two successes. The failures appear to mostly come from poses that aren't straight on which may just be harder to learn. However, my training loss was not significantly below my validation loss, and even on the training images some of the errors we see below were appearing. This suggests that the model is perhaps lacking in capacity as the training loss is not low enough to handle all cases and the model isn't overfitting.
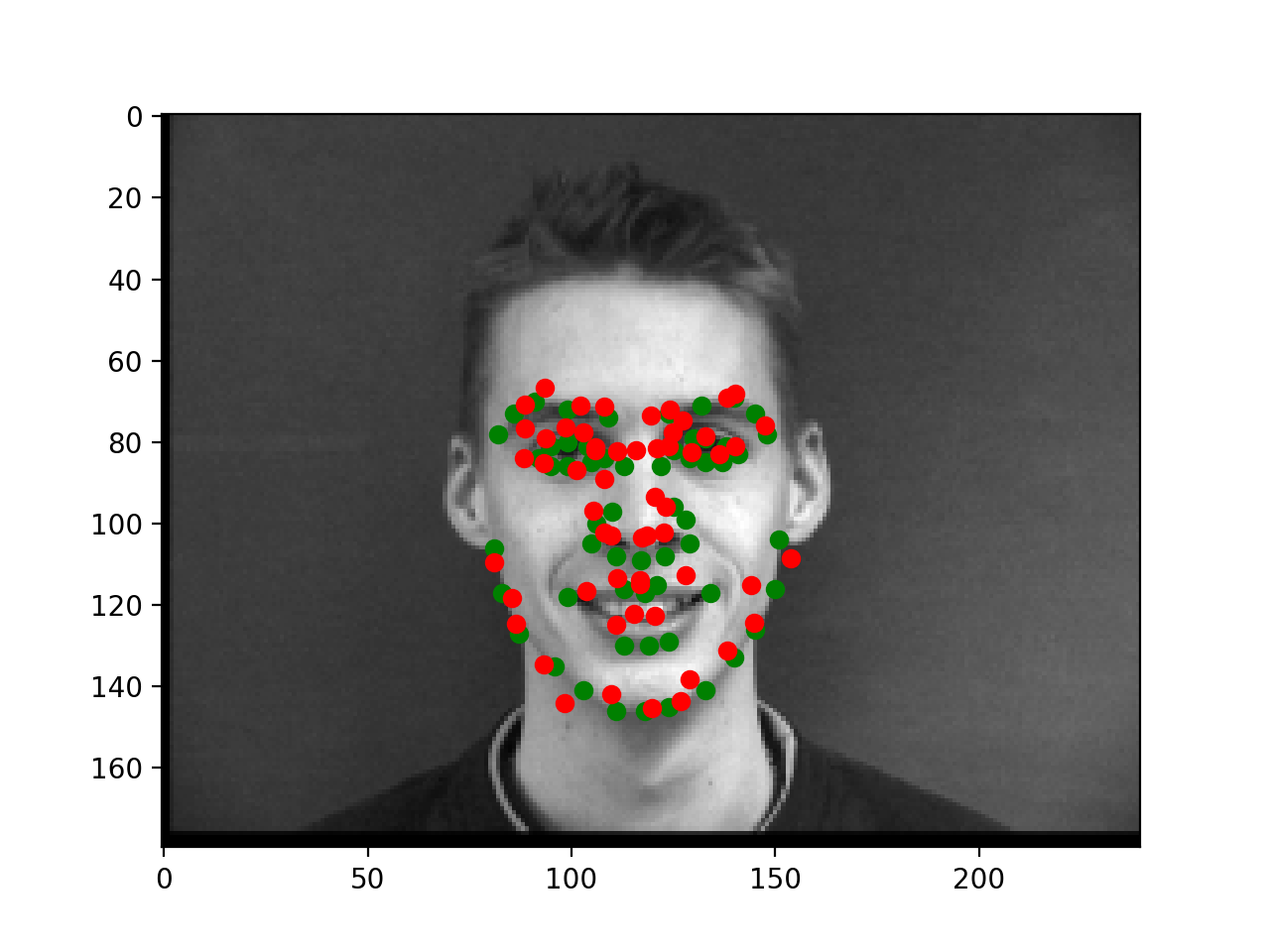
|
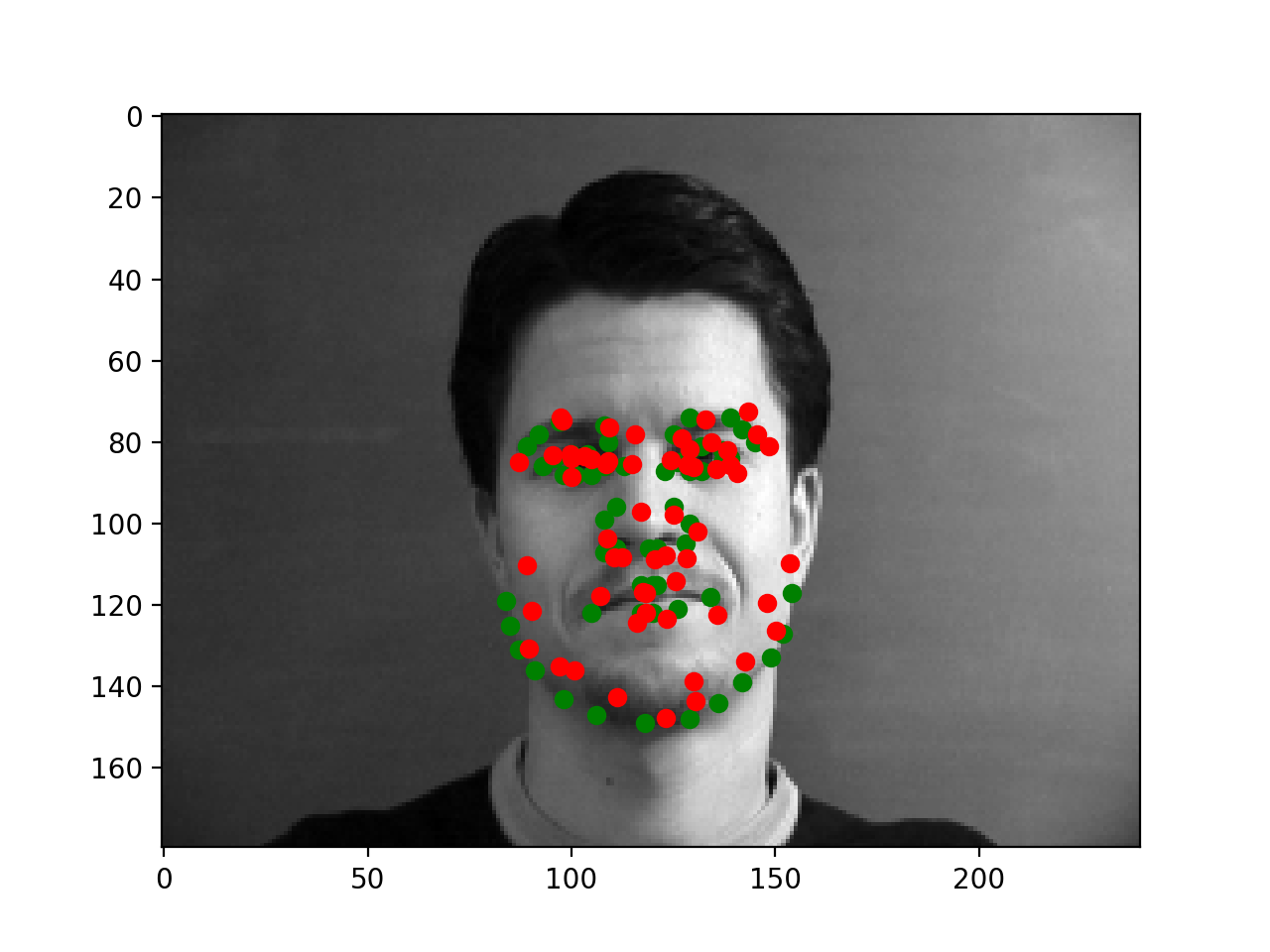
|
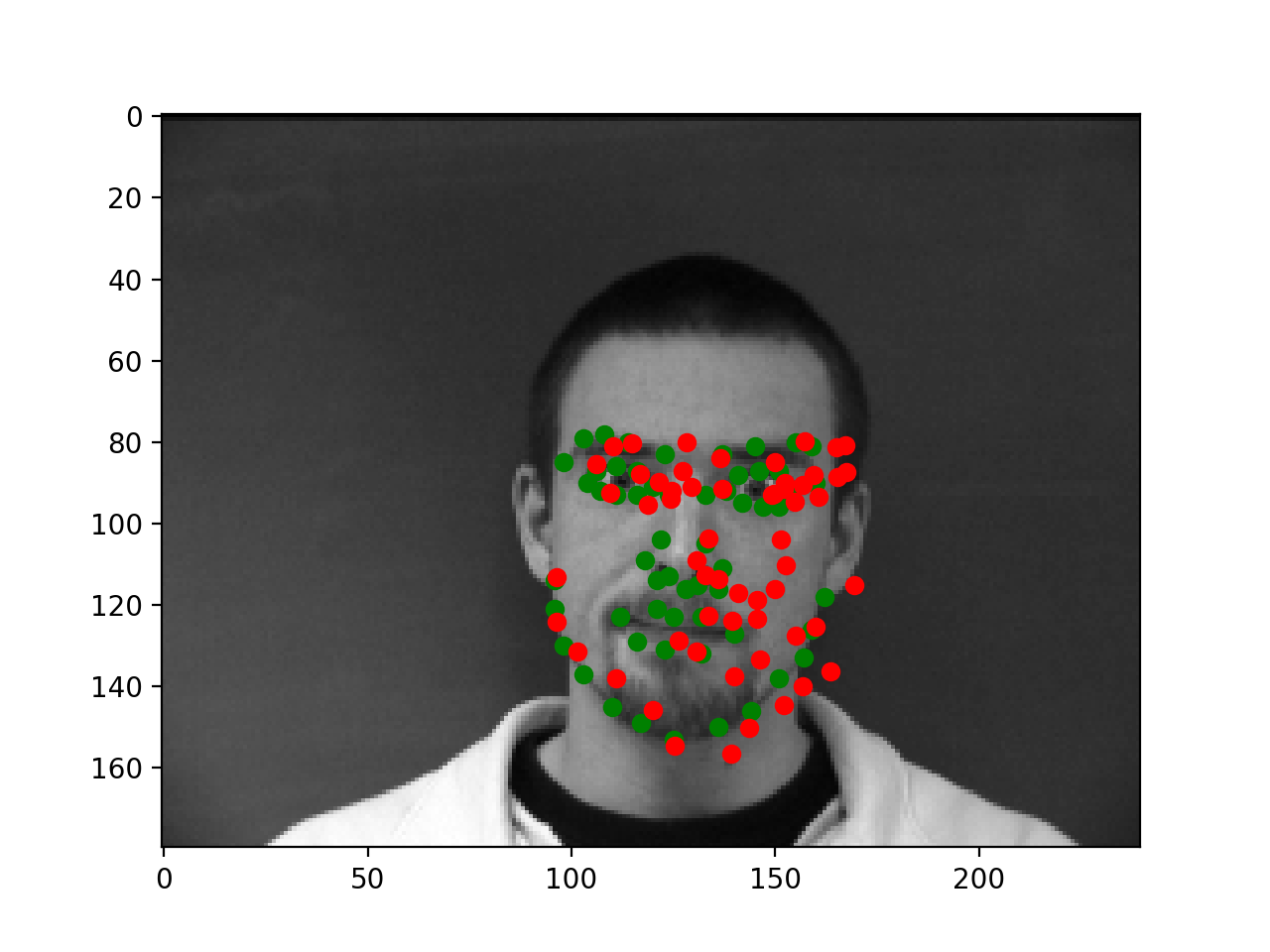
|
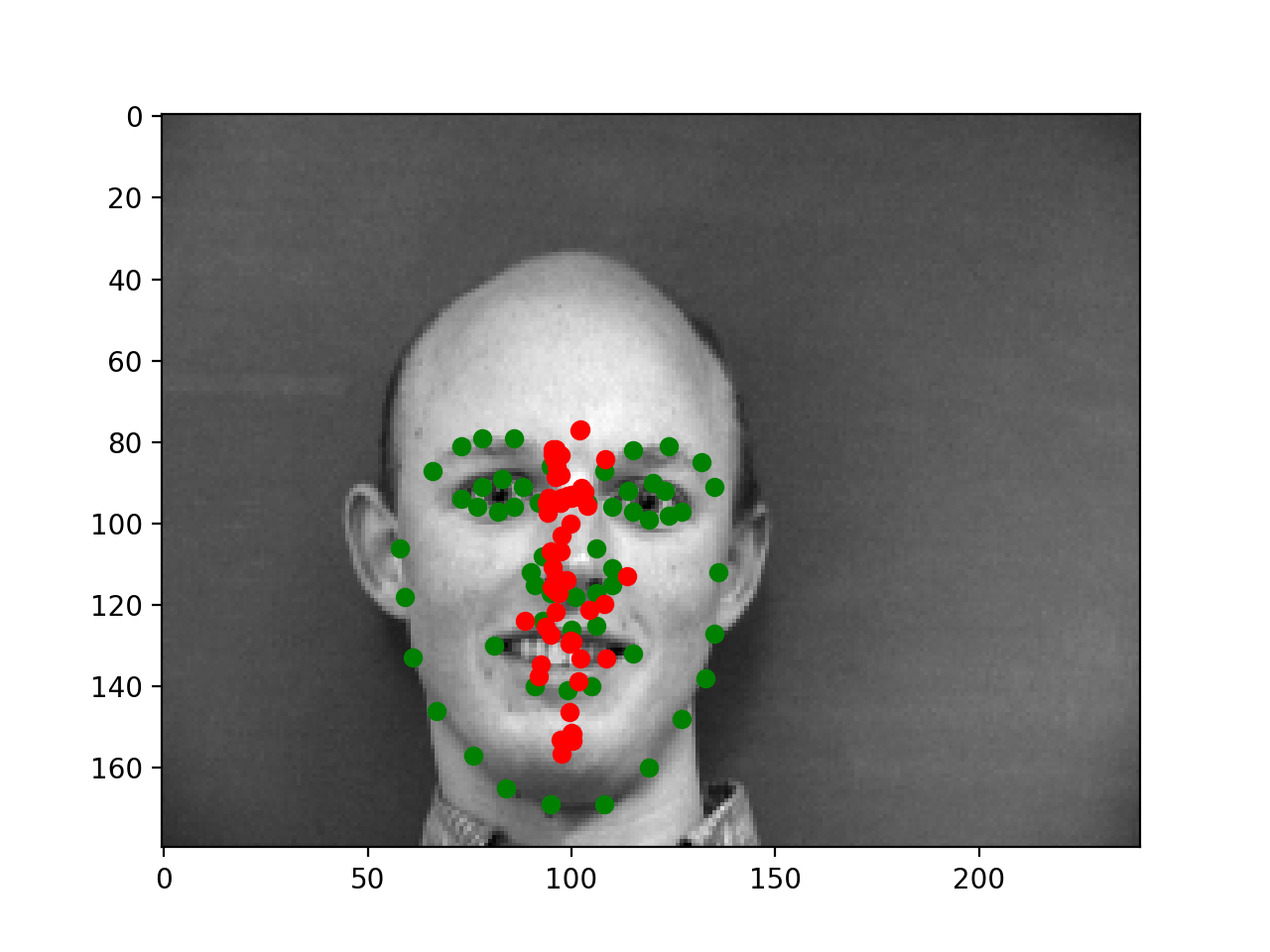
|
Visualized Filters
The visualized filters for the first convolutional layer are below
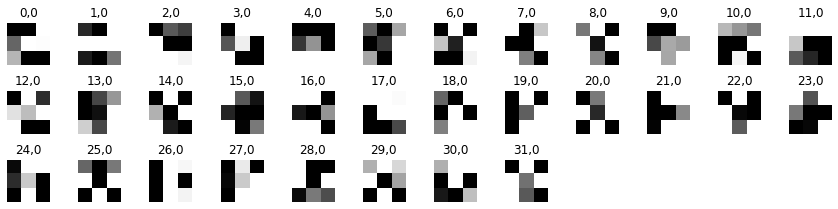
Part 3: Train with a Larger Dataset
After training with a larger dataset and submitting to the Kaggle competition, my final MAE was: 31.31099.
Architecture
The architecture used in this part is exactly PyTorch's pre-trained ResNet-18 with two modifications. Namely
- The first convolutional layer was changed to have one input channel (for grayscale), with all other hyperparameters left the same. That is, a $7 \times 7$ kernel and a stride of $3$.
- The last fully connected layer was changed to have a dimension of $512 \times 136$ to output the 68 keypoints instead of 1000 predictions for Imagenet.
For training, I chose a batch size of 32, and a learning rate of $0.0001$. I trained for 10 epochs. The training and validation loss plots are below.
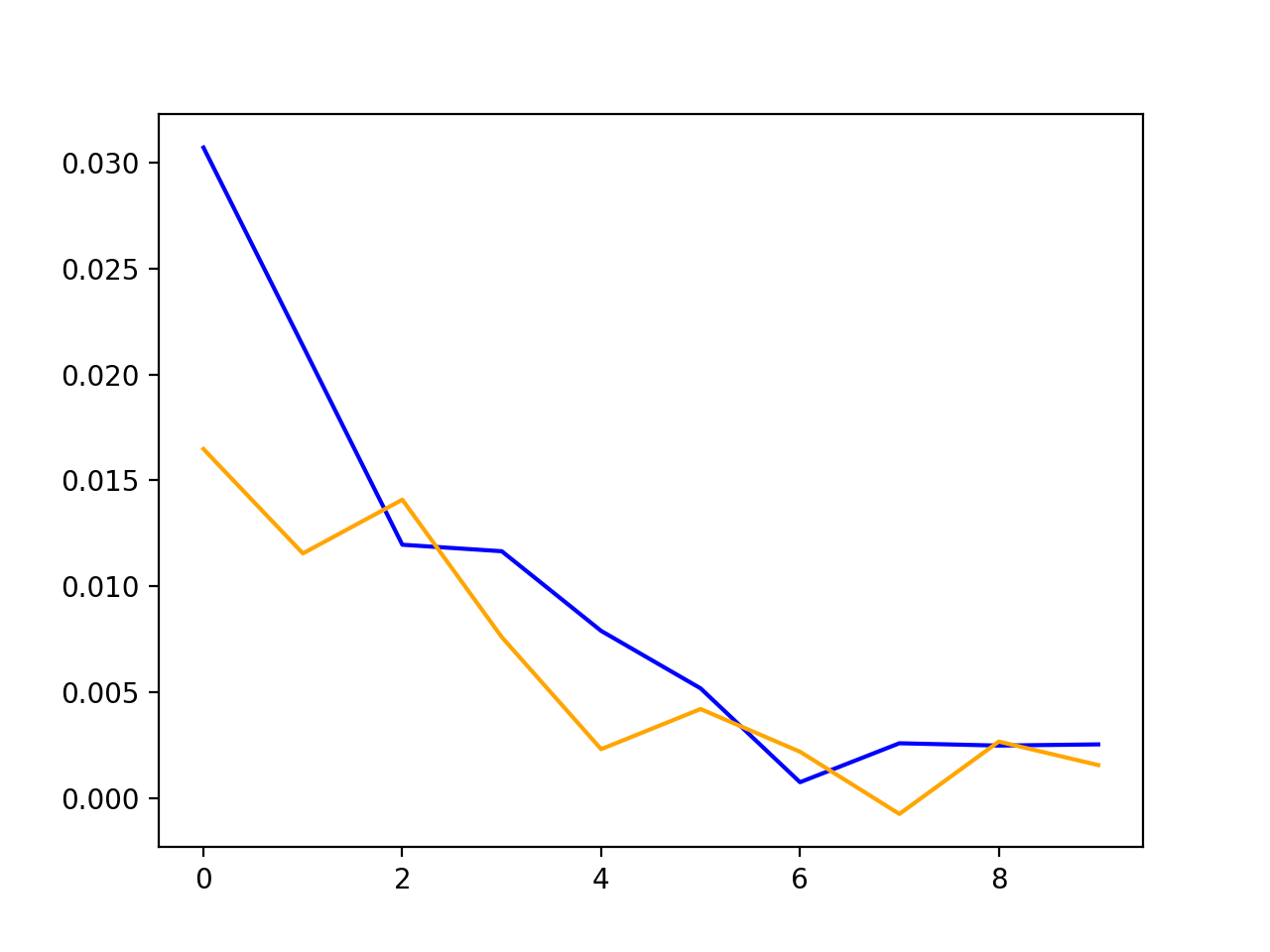
Orange: Validation Loss
This architecture is visualized below
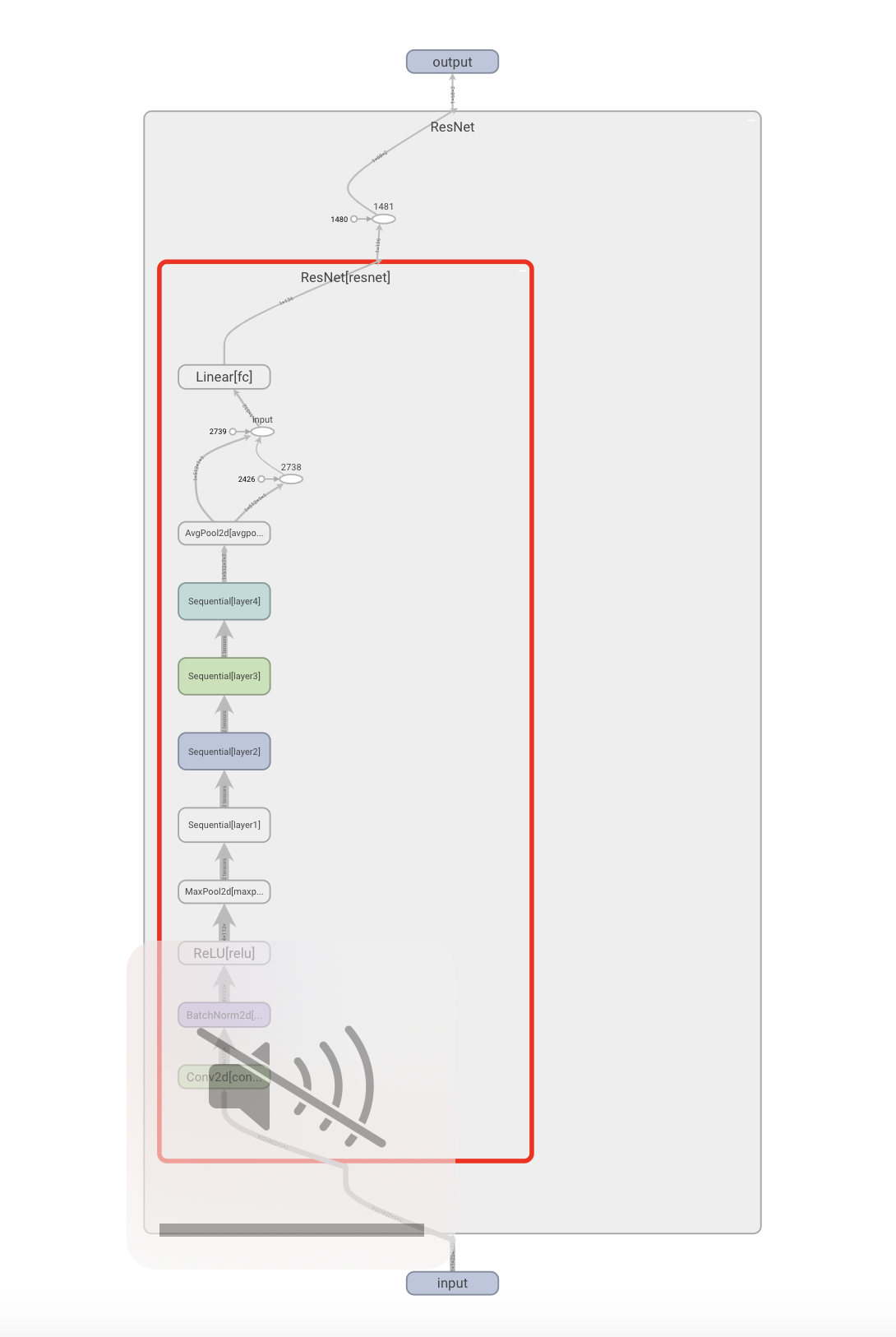
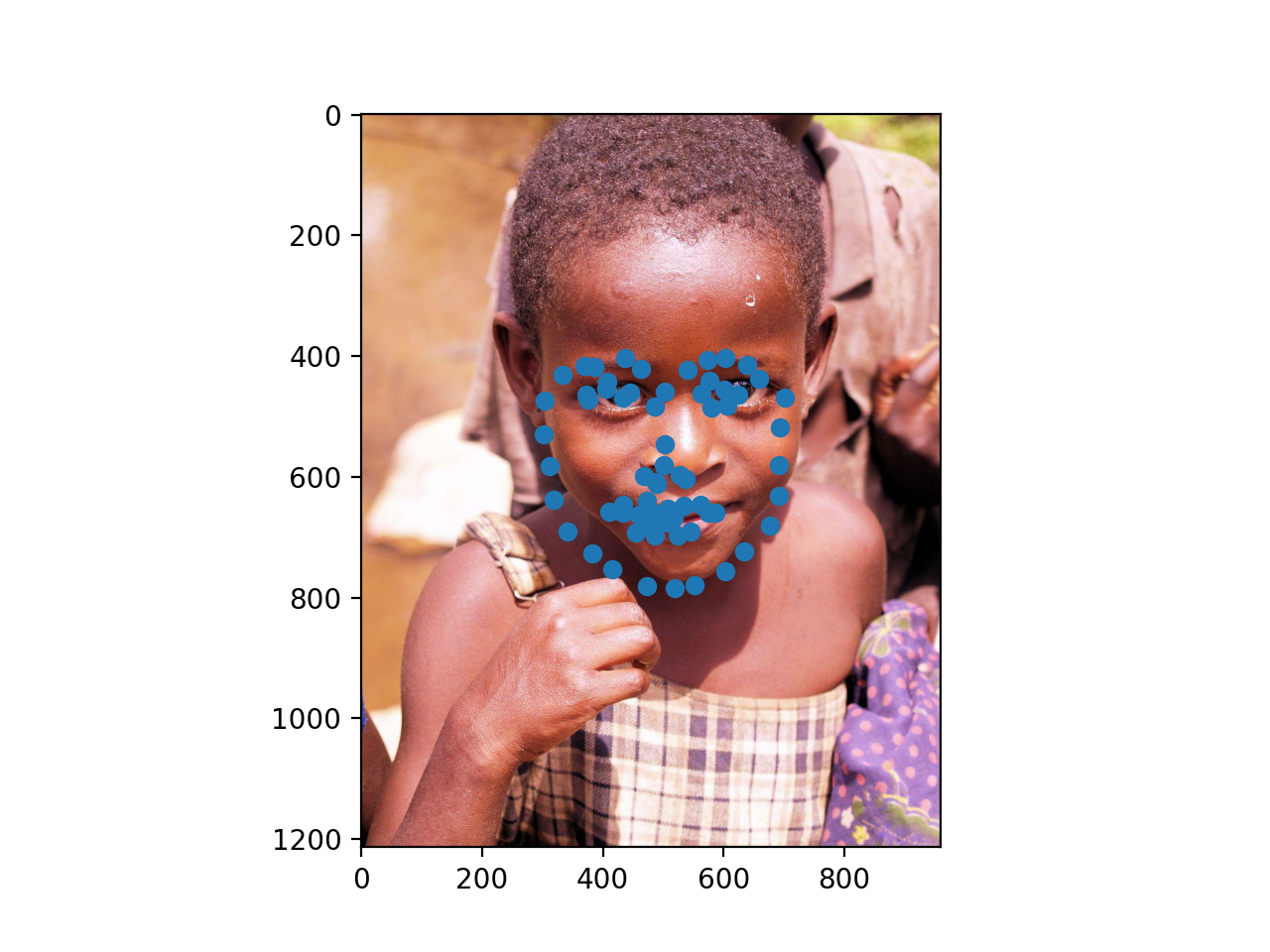
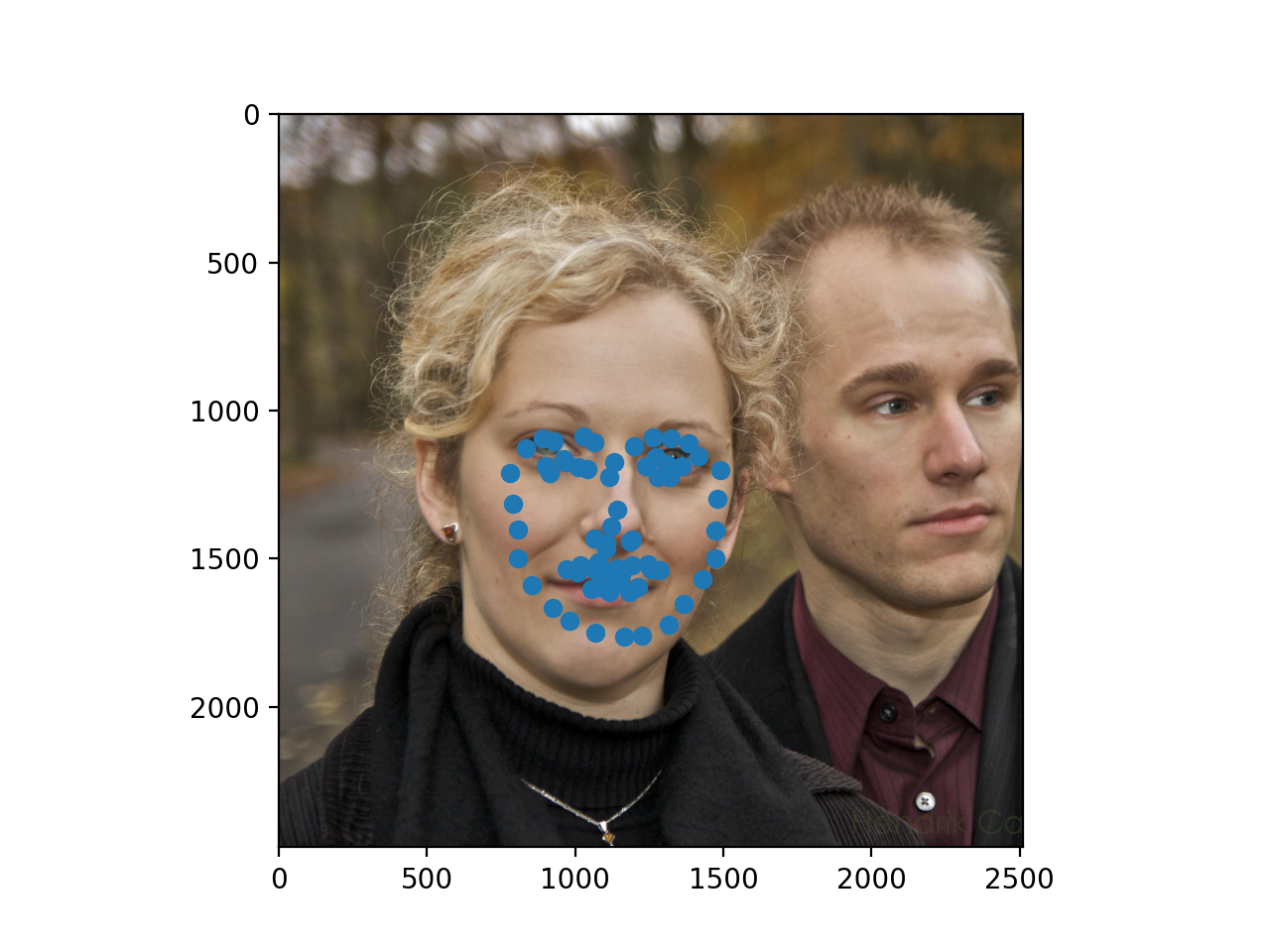
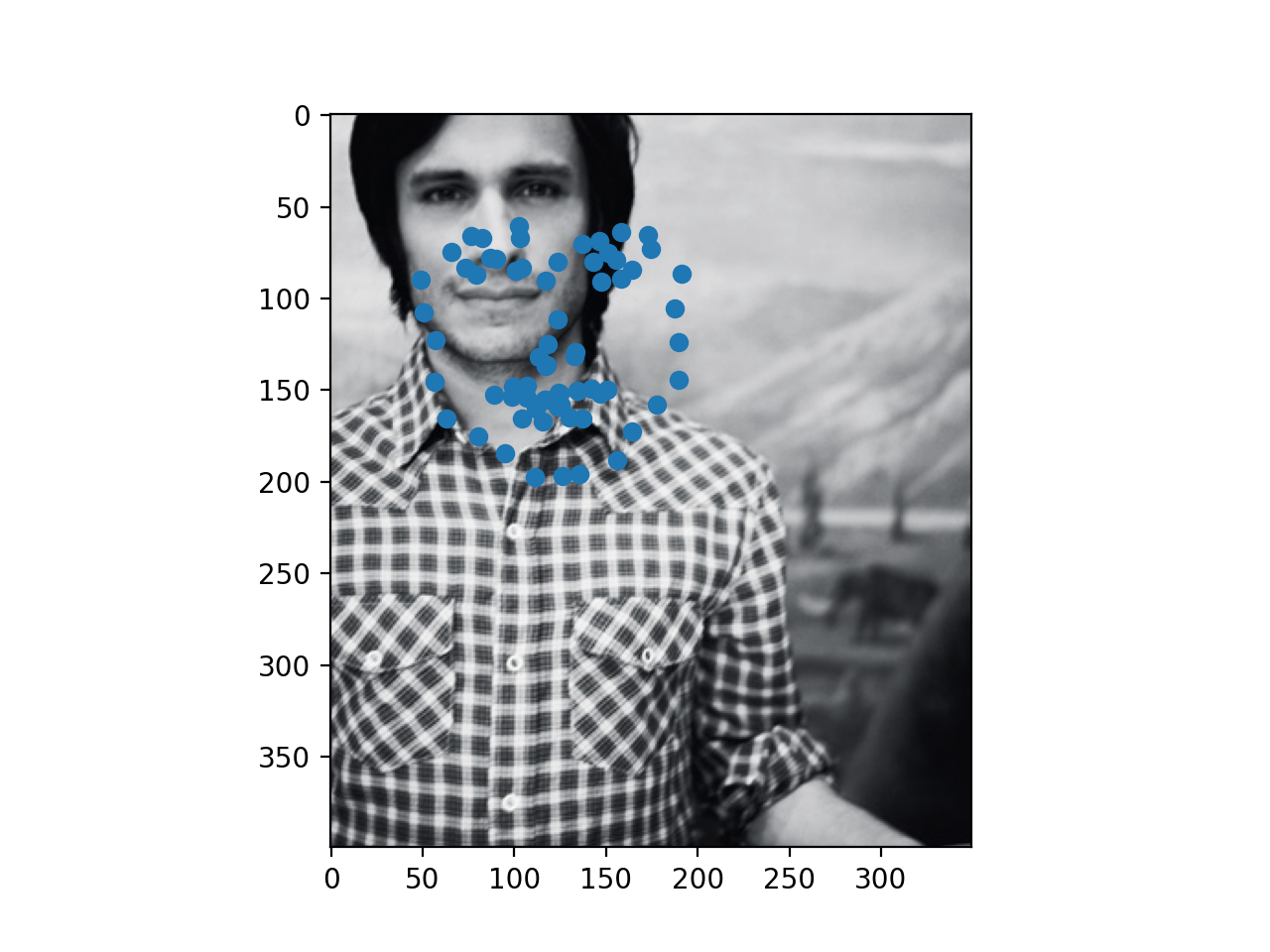
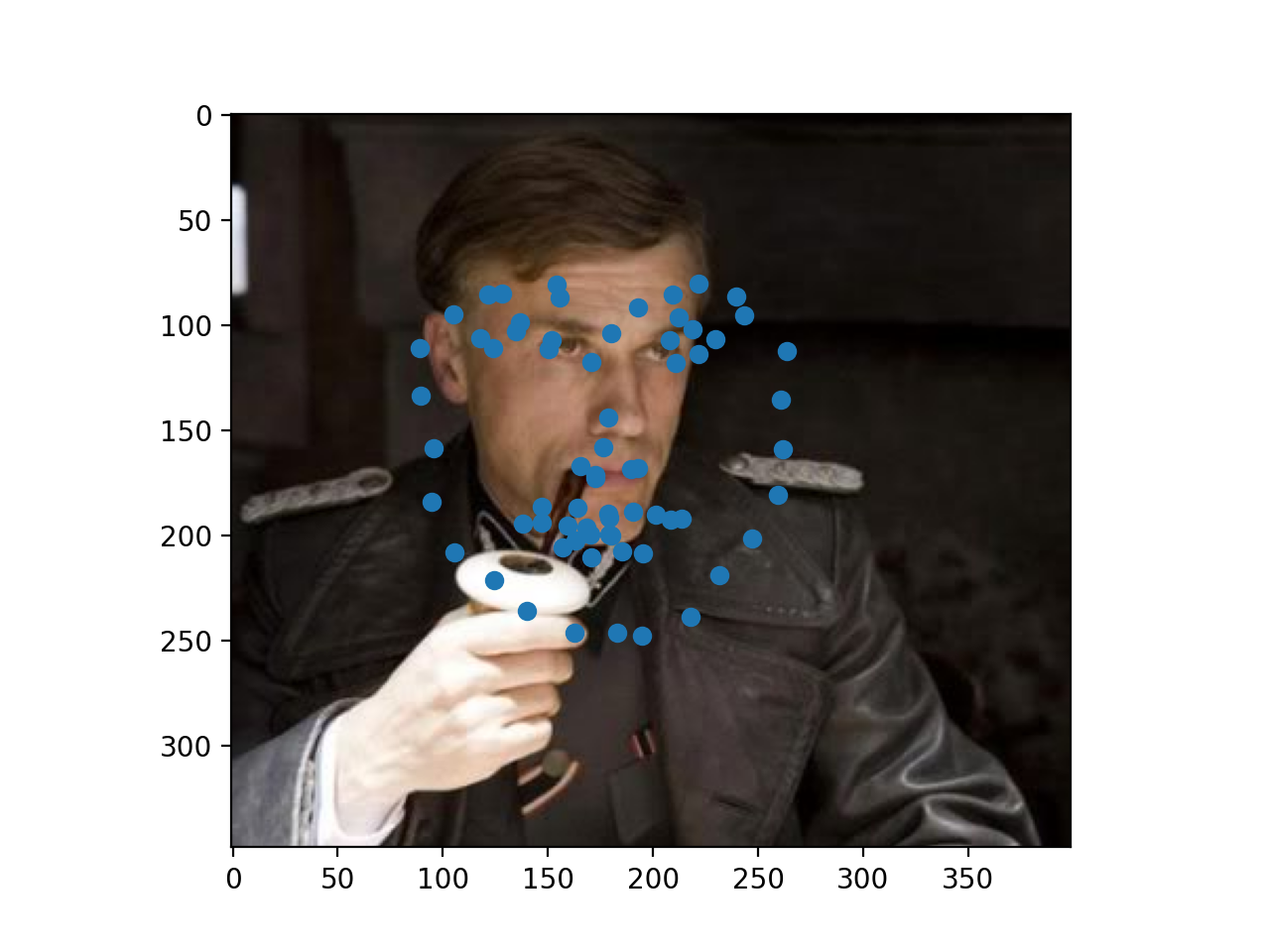
Below are three success and three failure cases for the
|

|
|
|
|
|
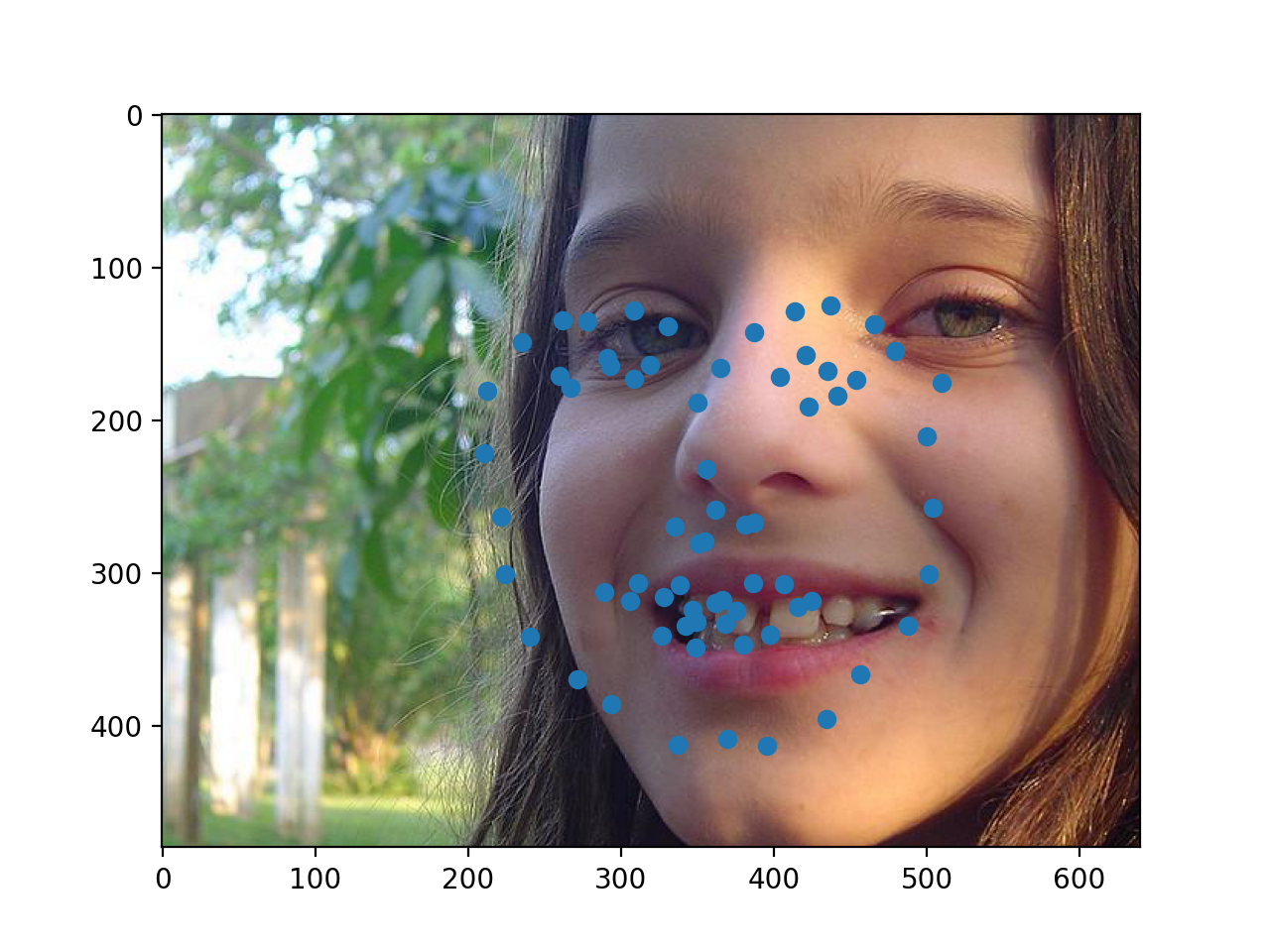
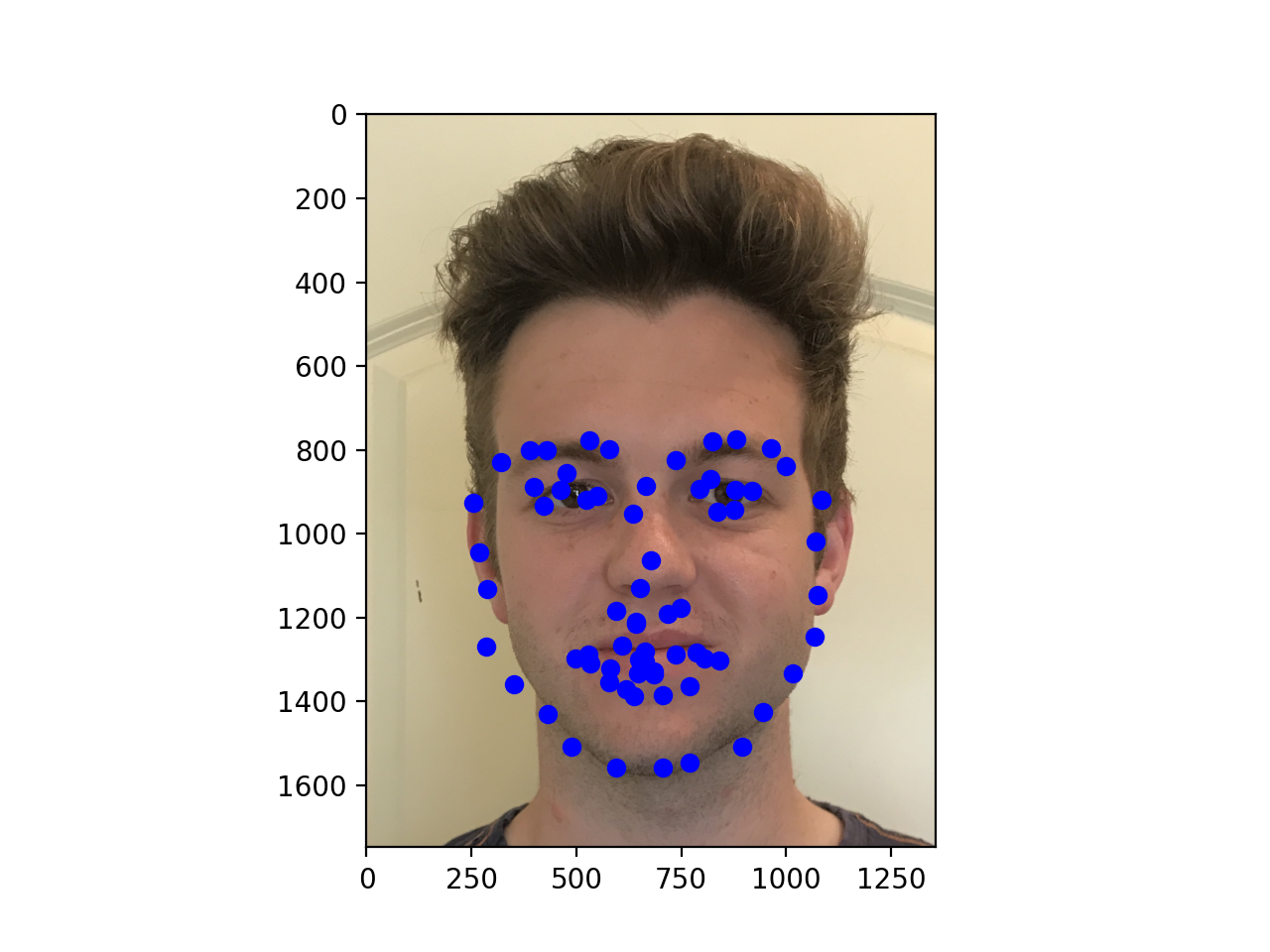
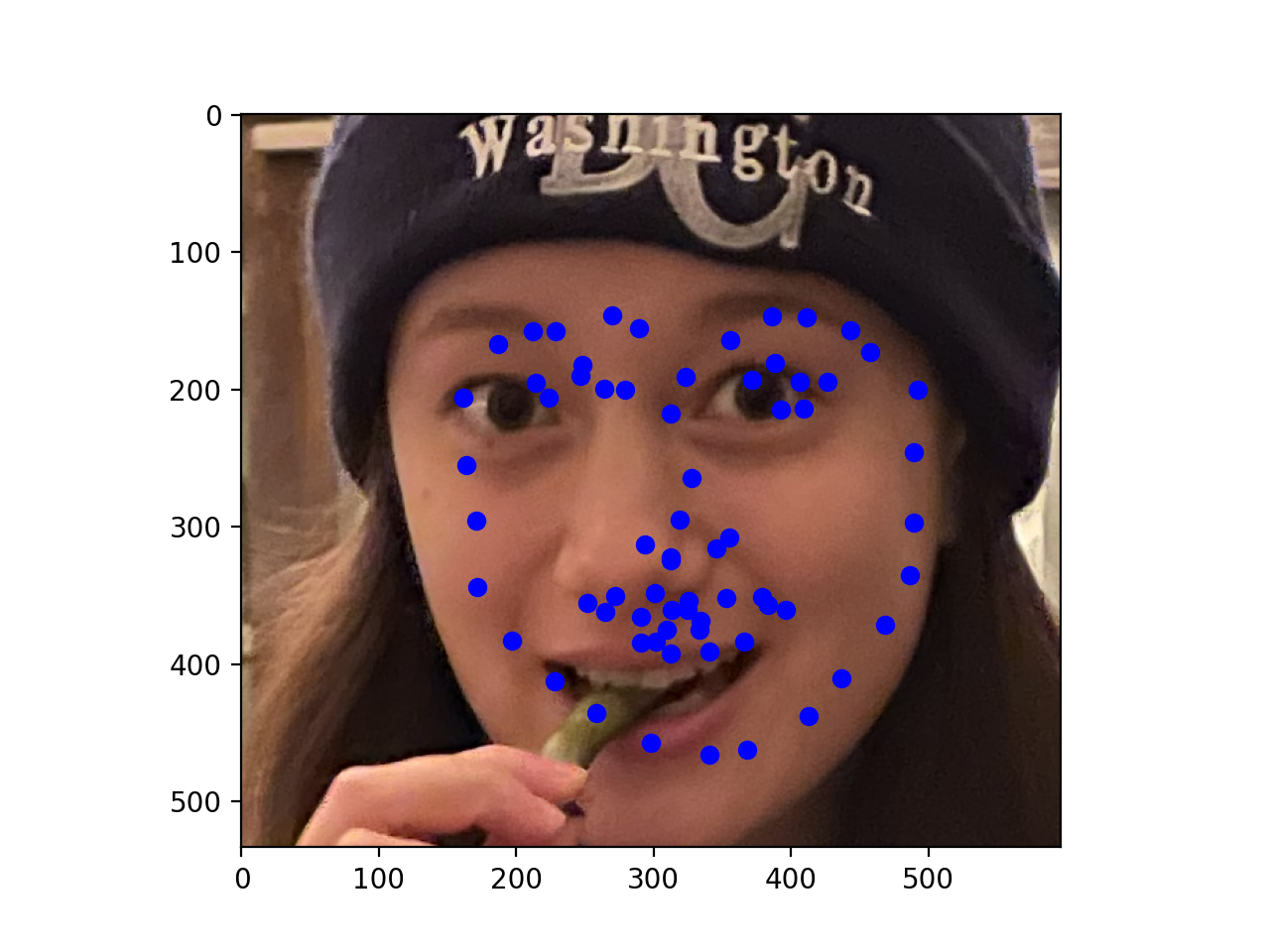
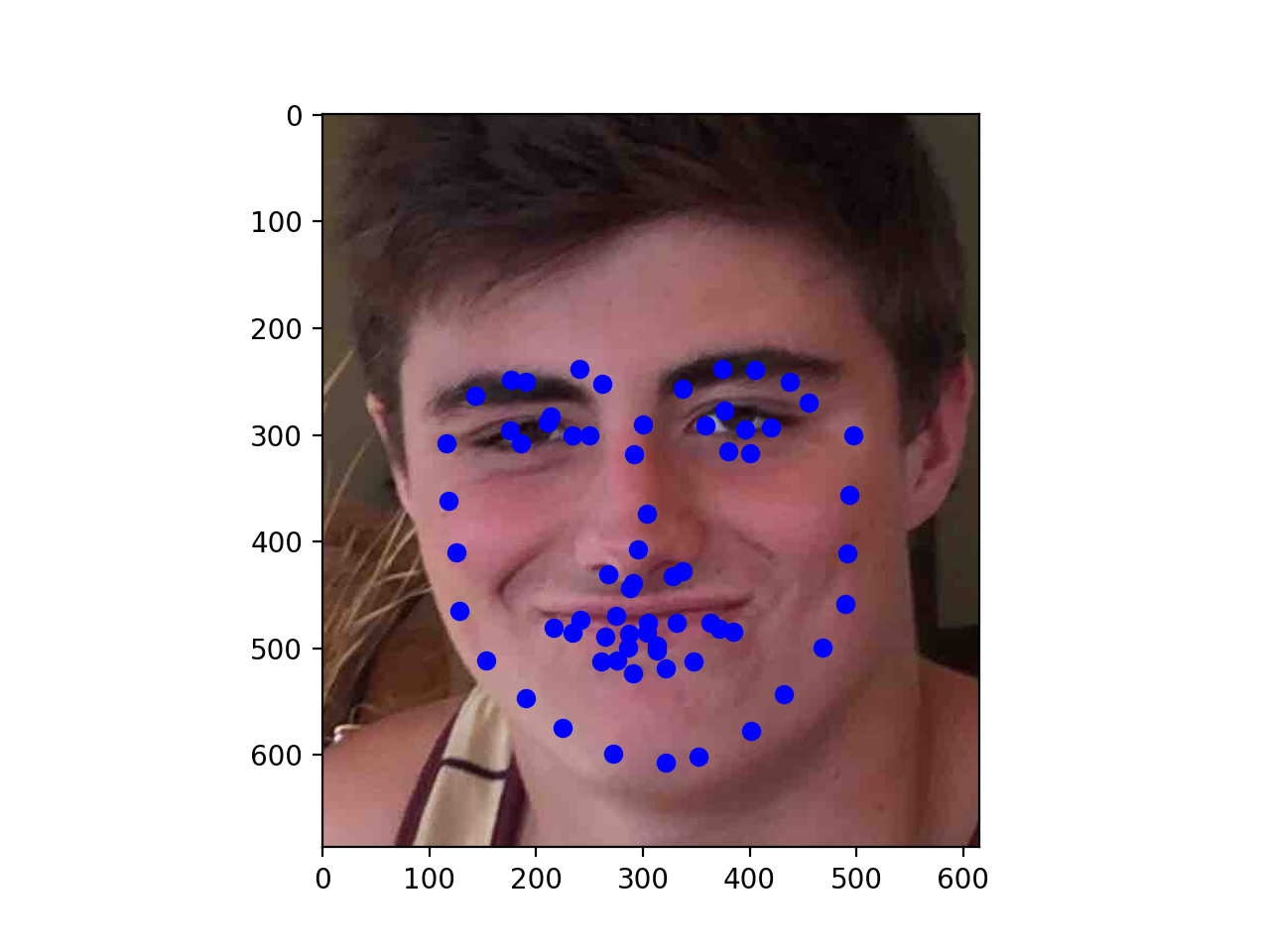
Finally, here are three of my own images which I ran my trained model on. As you can see, the second photo has an occlusion (edamame) which may be why the facial keypoints are more off for that one.
|
|
|