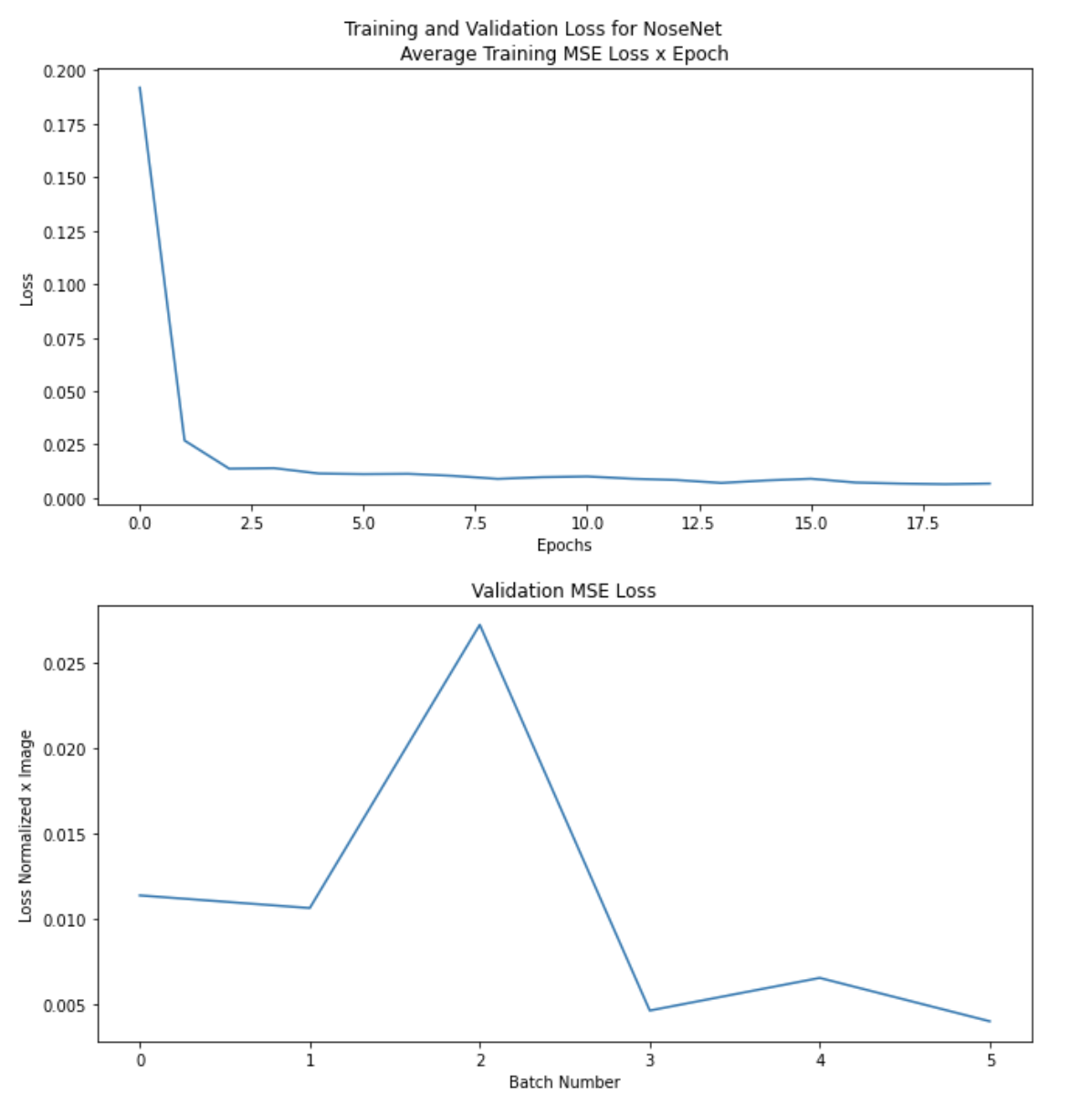
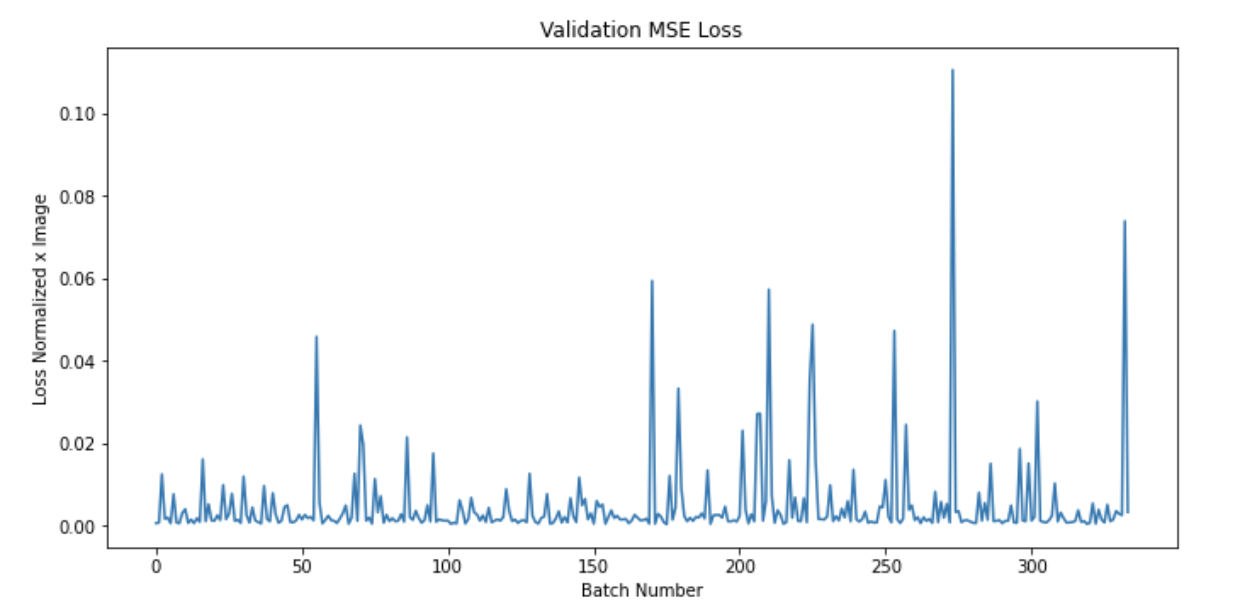
I trained the network for 20 epochs using MSELoss and adam optimizer with a learning rate of 0.008, additionally I used a batch size of 8. Here are plots of my average error x epoch, and the average batch error on the validation set.
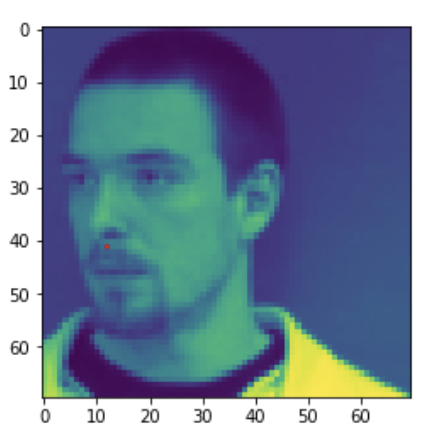
Here are two examples of images that correctly classified the tip of nose:

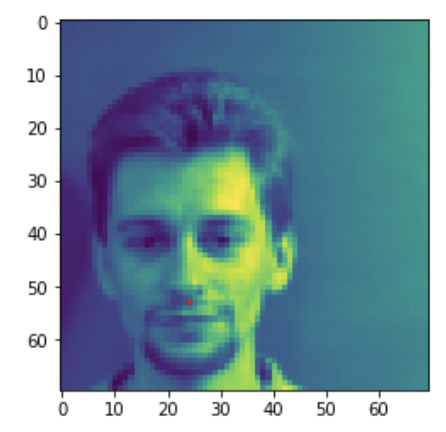
Here are two examples of images that did not correctly classify the tip of nose. I believe that this happened because shades in the images are very different from most of the images. It is reasonable to assume that the shadows of the nose play a big role in the filters learned by the network. Additionally, for the images in which the face is rotated to the sides it may be harder for the network to correctly predict the tip because of the absence of the two circular shadows and lack of symmetry in the face. Although, none of the face are perfectly symmetrical there is some symmetry in the face that may be helping the net identify the tip of the nose.

In part 2 we basically extend what we did in part 1 to predict all 58 facial keypoints. Here is the architecture for this part, it is very similar to part 1 except I added more convolutional layers. I had actually experimented with two different networks, one with smaller kernel sizes trending to larger kernel sizes as we go deeper and one with largerkernele sizes trending to smaller kernel sizes as we go deeper. I have found the former to perform better, one idea for this is that most of the keypoints are near areas of high freuency, example the outline of the face goes from very bright to very dark (background) quite fast. Therefore a smaller kernel size in the first layer will maintain some of these high frequency features of the image. Although, I have not tested convoluting the learned filters with the images. Here is my final architecture, as you can see the kernel sizes start out small and gradually grow larger as we go deeper into the network.
(conv1): Conv2d(1, 12, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(12, 18, kernel_size=(3, 3), stride=(1, 1))
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): Conv2d(18, 24, kernel_size=(5, 5), stride=(1, 1))
(conv4): Conv2d(24, 28, kernel_size=(5, 5), stride=(1, 1))
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv5): Conv2d(28, 32, kernel_size=(7, 7), stride=(1, 1))
(conv6): Conv2d(32, 36, kernel_size=(7, 7), stride=(1, 1))
(pool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=7056, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=256, bias=True)
(fc3): Linear(in_features=256, out_features=116, bias=True)
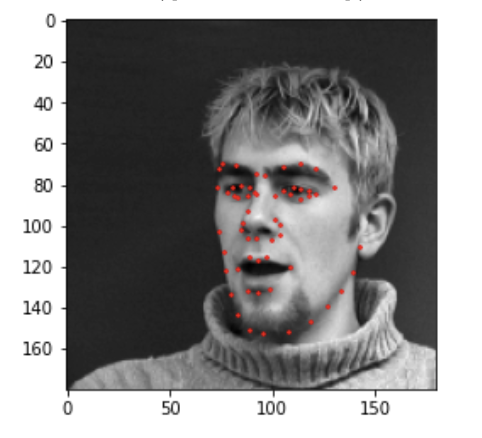
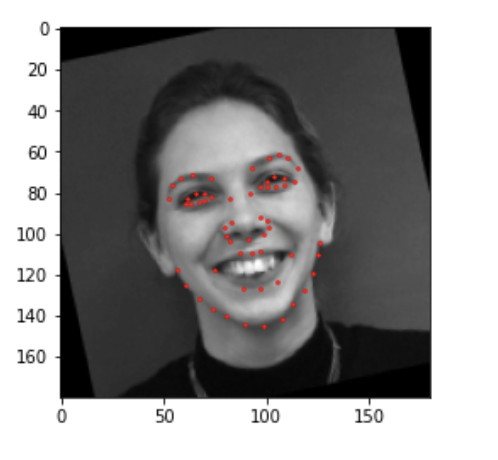
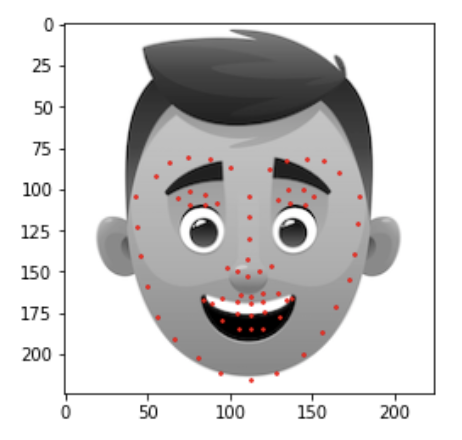
I used the same data augmentation techniques mentioned in part 1, with the major difference being that for this part and subsequent parts instead of normalizing using statistics of the keypoints I simply normalized by making sure each keypoint is between (-1, 1). I did this by subatracting and then dividing by the width of the image dividied by two, since the image shape is a square it doesn't matter if you use width or height. I also applied this normalization technique in the following parts since I have found this to work better than the nromalization technique using the statistics of the keypoints. Here are two sample images with the true keypoints:
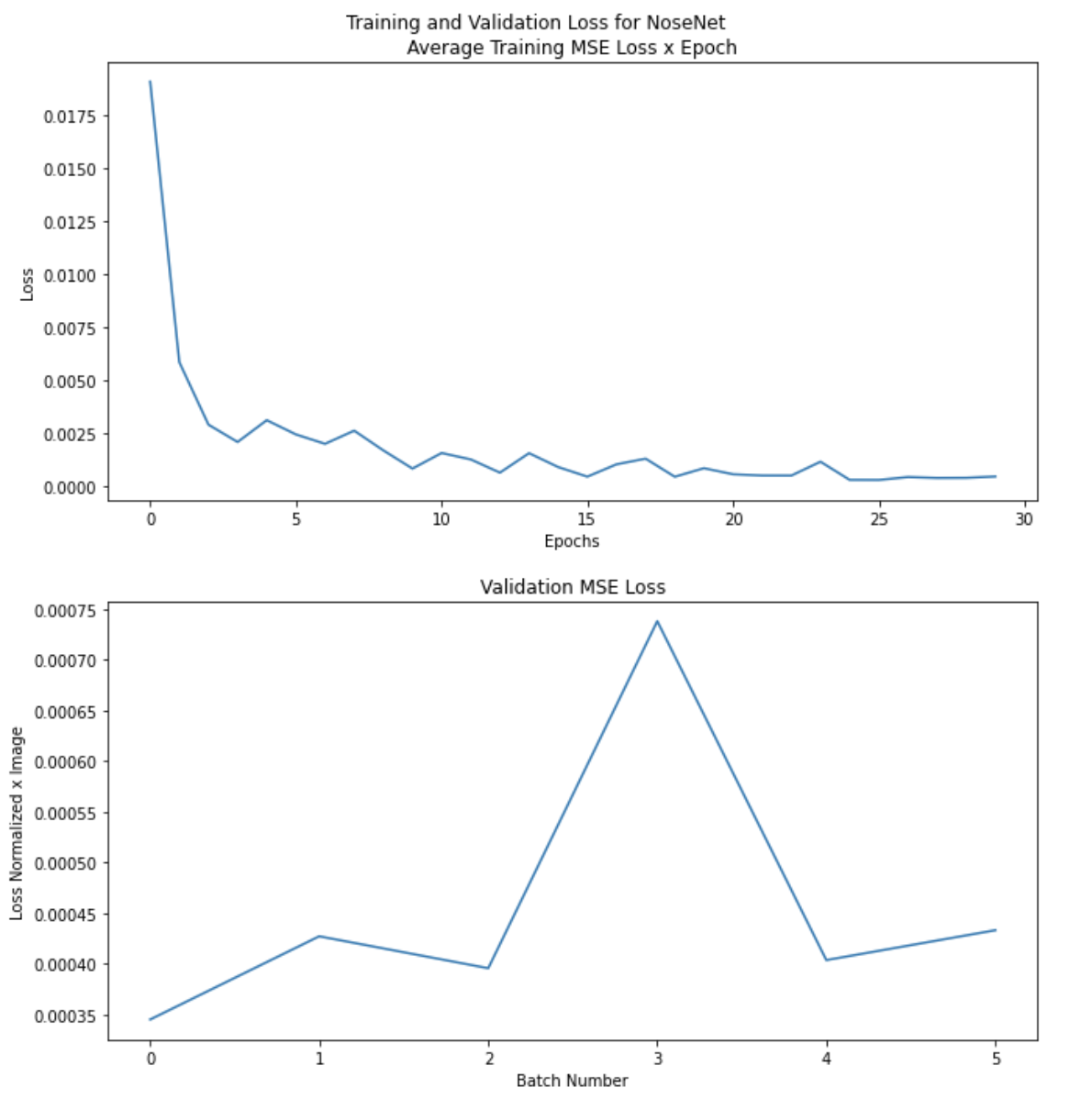
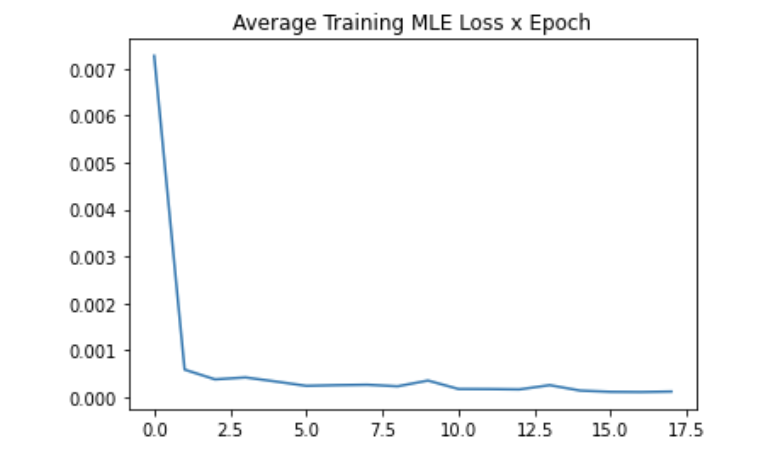
I trained my network for 20 epochs with the same loss function and otpimizer as in the previous part. Here are plots of my average error x epoch, and the average batch error on the validation set.
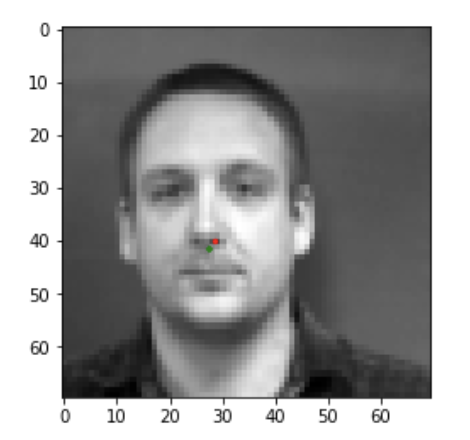
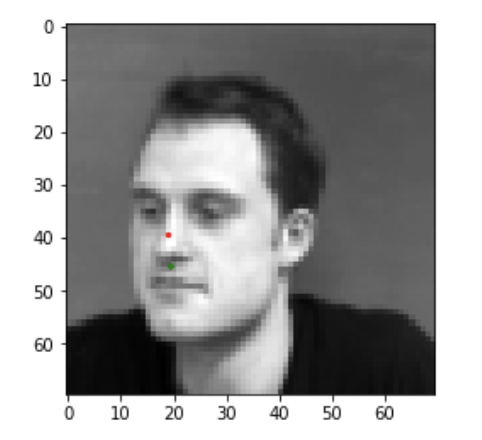
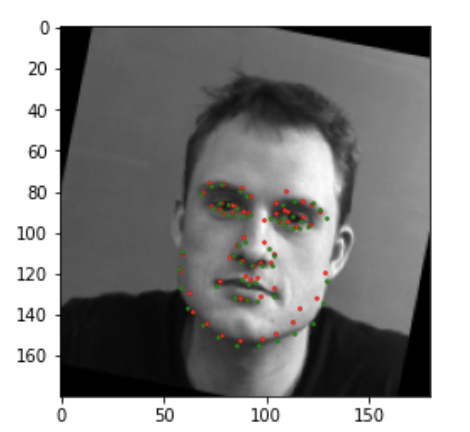
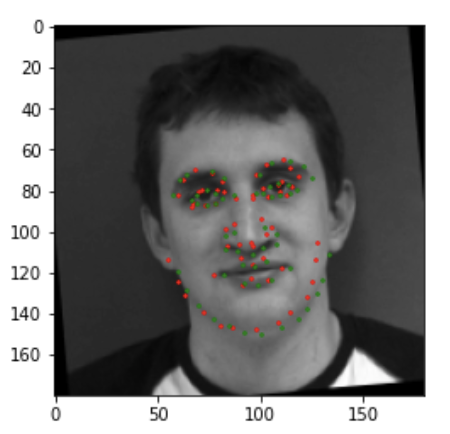
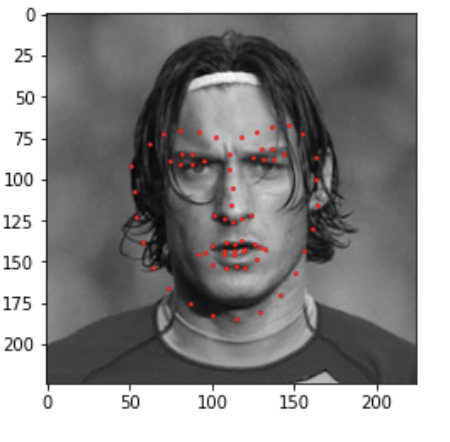
Here are two images I thought my network did well on, in these figured the red are predicted points and green are the ground truth points.
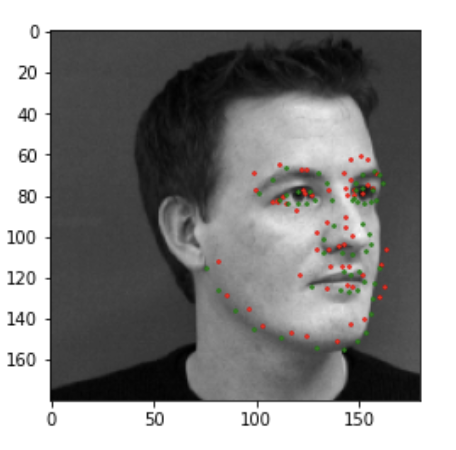
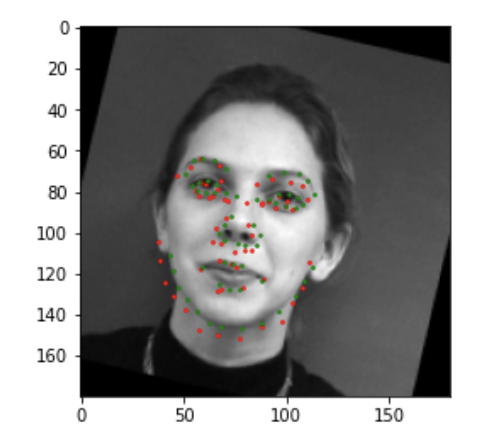
Here are two images I thought my network did bad on. I think images with the individual rotated either right or left are usually harder to predict the keypoints on. Additionally, I think the shadows come into play here as well for points that wrap around the face/cheek bones, therefore images with varying shadows will also be misclassified. We can in fact see that in the second image the points seem to wrap around the shadows of the face not the actual face.
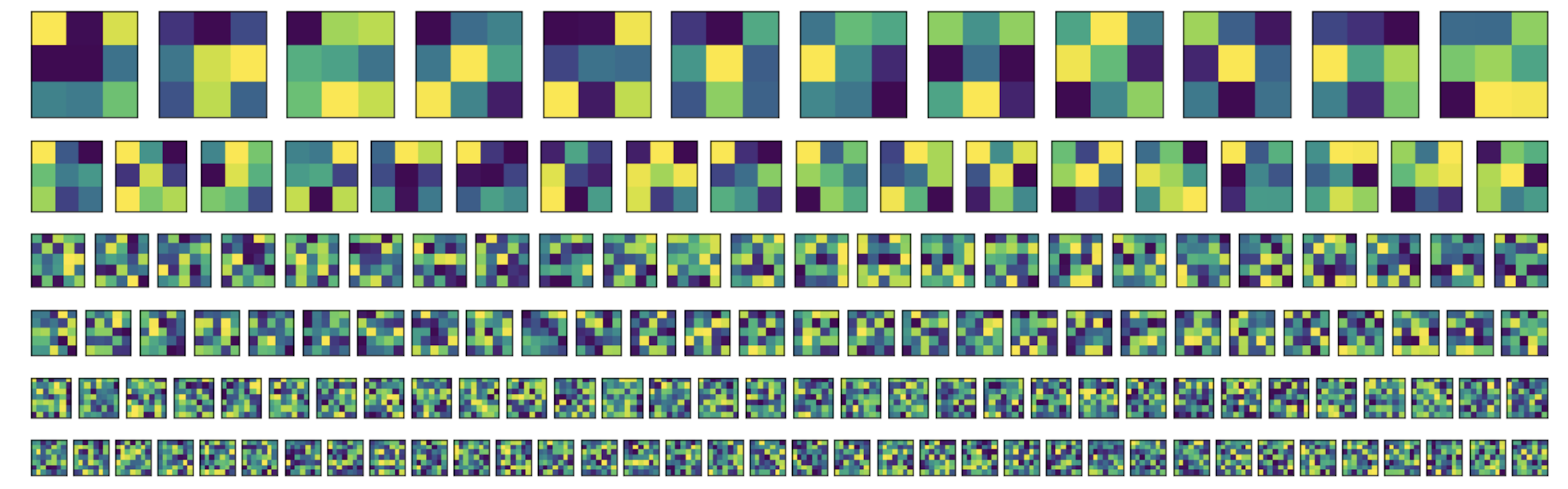
Here is a plot of the filters the network learned, each level in the plot represents a convolutional layer, i.e. the first row of filters belongs to the conv1 layer, the second to conv2, and so on..
For this part I used a pre trained resnet18 network from pytorch. I first performed the usual data augmentation techniques except I had tried adding blurring and adding noise to the images. I did not submit to kaggle with these changes but after a quick visual inspection I believe the predicted poitns were not as good as the the predicted points without blurring and adding noise to the training data. The only changes I made to resnet18 was to change the input convolution to work with one channel instead of 3 and output 128 points (68 keypoints x2). Here is my architecture:


My kaggle username is Matteo Ciccozzi and my MAE is 16.00245. Here are plots of the average training loss x epoch and validation error average for each batch:
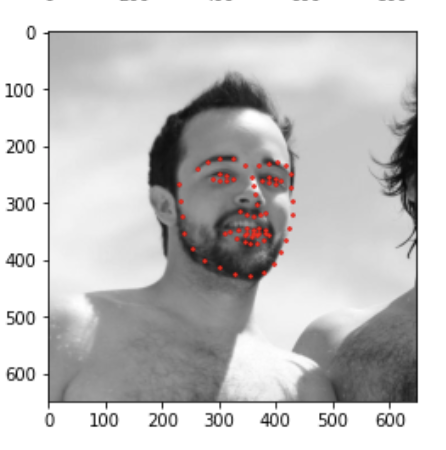
Here are some good examples from the testing set:

Here are some bad examples from the testing set. I think that these failed because of the different kind of images from the training set. The first image has a very different shape, eg no neck showing and the prominent beard probably also affected it. The second one was probably misclassified because I did not apply the rotation to enough images, as you can see the keypoints shape is correct but it is not rotated enough.
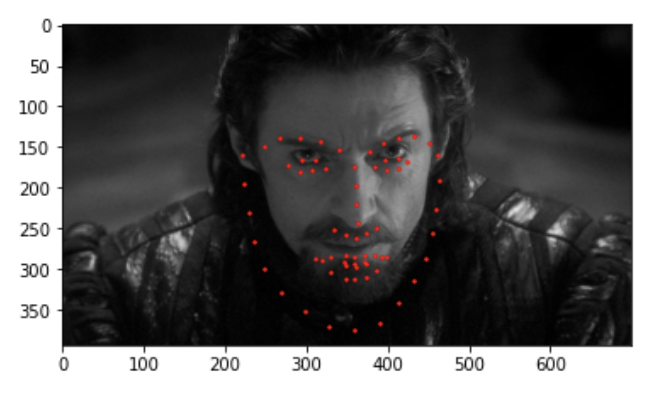
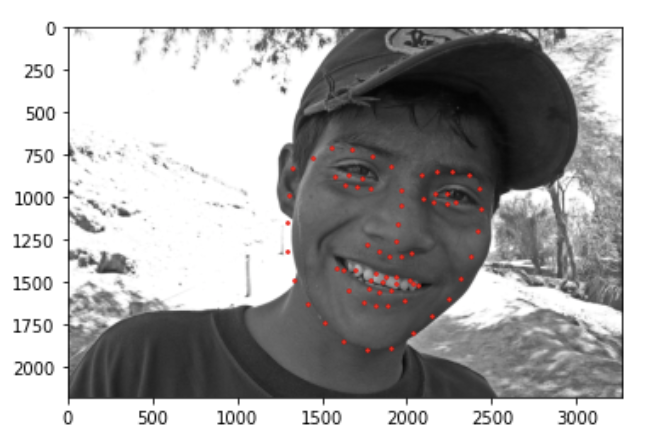
Here are my three personal images I tested the network on:

I think 2 out of 3 are good, this last one did not turn out too well and I think the shadows + long hair could be to blame perhaps. One interesting think I noticed is that the shape of the predicted face seems to be more femminine perhaps because most of the women had long hear that kind of matched the soccer player's style. Therefore it doesn't correctly predicted its more masculine/square facial features.
Overall I really enhoyed this project. I had some issues with colab that caused me to lose my network three times after spending hours training it but I definitely learned a lot. I felt the hardest part of the project was actually the data preprocessing, therefore it was nice that course staff provided many tutorials and allowed us to recycle some of the code found in the tutorials. Things to do that could improve results is flipping images in the data augmentation part and perphaps trying with a deeper network like resnet34, although it could end up overfitting so I would have to test it out more to make a decision.