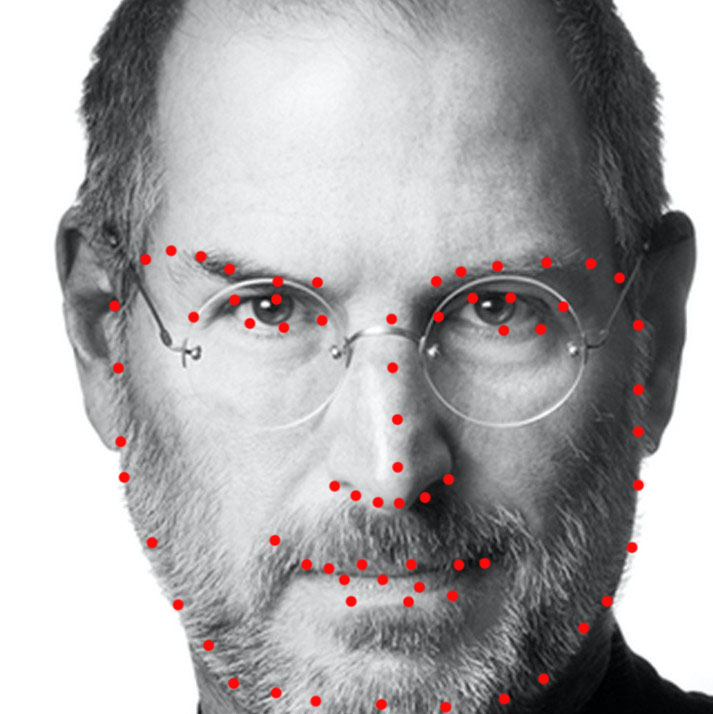
Facial Keypoints Detection with Neural Network
Table of Contents
1 Introduction
Detecting facial keypoints is essential in our daily life. It helps with detecting facial expressions and 3D facial estimation. In this project, we explore facial keypoints detection
with the neural network approach.
2 Nose Tip Detection
In this part, I implemented a 3-layer convolutional network for nose tip detection. I used the IMM Face Database which is composed of 240 facial images
of 40 persons and each person has 6 facial images in different viewpoints.
Here are some sampled images from the data loader with ground truth keypoints.




Here are the output of the neural network. The green dots are ground-truth keypoints, while the red are predicted keypoints.
Examples of good predictions


Examples of bad predictions


The top two are good predictions whereas the bottom two are not. The difference is caused by the lack of varied data. Also, the bottom two are off-centered faces which is a small subset of the dataset. As a result, the network provides more centered predictions even for off centered images.
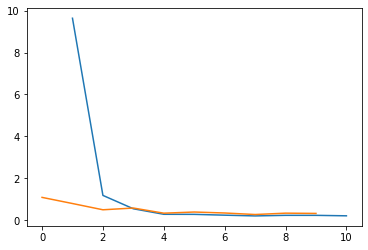
Here is the train and validation accuracy plot
3 Full Facial Keypoints Detection
After finishing the nose tip detection, we can head to detect all 58 facial keypoints. We first reshape the images into 160 * 120, and enlarge the dataset using data augmentation to
prevent the model from overfitting. Specifically, I used Rescale(250), RandomCrop(224), transforms.ColorJitter(brightness=0.5), transforms.RandomRotation(15), transforms.ToTensor() and
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]
Here are some sampled images with ground-truth keypoints.




Good predictions


Bad predictions


Again, the good predictions are centered images whereas the bad predictions are off-centered images. The lack of side images in the dataset remains even with data augmentation.
Conv1

Conv2

Conv3

Conv4

FaceNet( (conv1): Conv2d(1, 32, kernel_size=(5, 5), stride=(1, 1)) (relu1): ReLU() (conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1)) (relu2): ReLU() (conv3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1)) (relu3): ReLU() (conv4): Conv2d(128, 256, kernel_size=(2, 2), stride=(1, 1)) (relu4): ReLU() (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (fc1): Linear(in_features=36864, out_features=1000, bias=True) (fc2): Linear(in_features=1000, out_features=1000, bias=True) (fc3): Linear(in_features=1000, out_features=116, bias=True) (drop1): Dropout(p=0.1, inplace=False) (drop2): Dropout(p=0.2, inplace=False) (drop3): Dropout(p=0.3, inplace=False) (drop4): Dropout(p=0.4, inplace=False) (drop5): Dropout(p=0.5, inplace=False) (drop6): Dropout(p=0.6, inplace=False) )
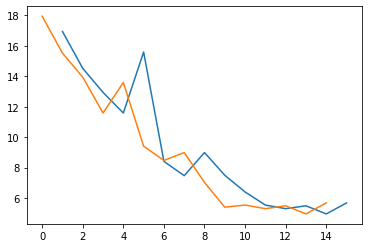
The train and validation accuracy plot:
4 Train with Larger Dataset
For this part, we will use a larger dataset, specifically the ibug face in the wild dataset for training a facial keypoints detector. This dataset contains 6666 images of varying image sizes, and each image has 68 annotated facial keypoints.


ResNet(
(conv1): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=136, bias=True)
)
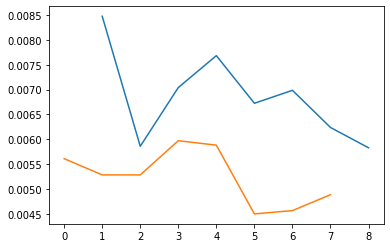
I used the following hyperparameters: epochs = 8, batch_size = 10, learning_rate = 0.001. I used MSELoss() and torch.optim.Adam optimizer. Below is the train and validation accuracy plot.



My data collection: