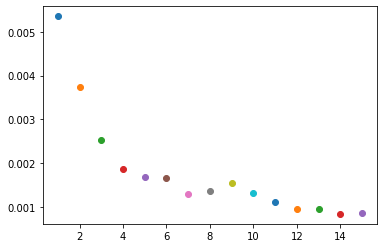
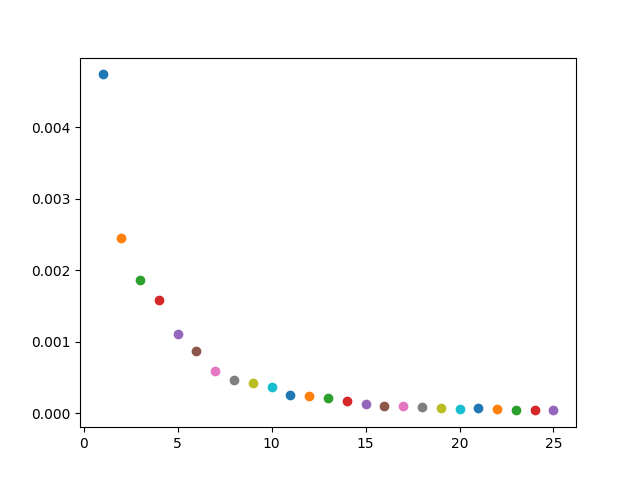
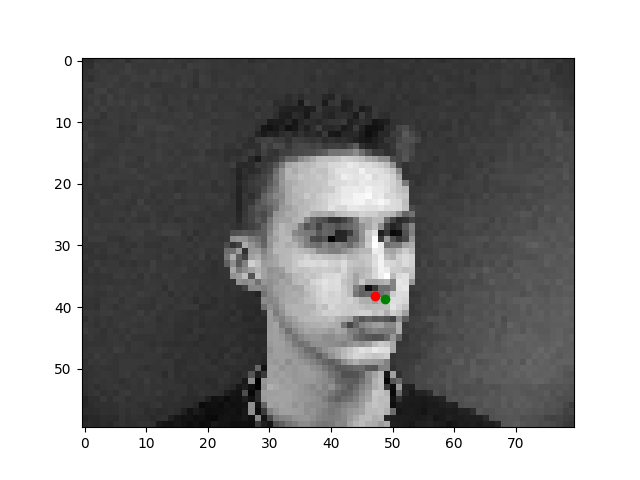
In this section, I took a set of images and single keypoint. I then created a Convolutional Neural Network with 3 CNN layers, each with a size of 7x7. I had 2 FCs layers, and I noramlized the keypoints around 0, and ran 25 epochs.
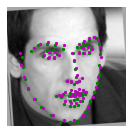
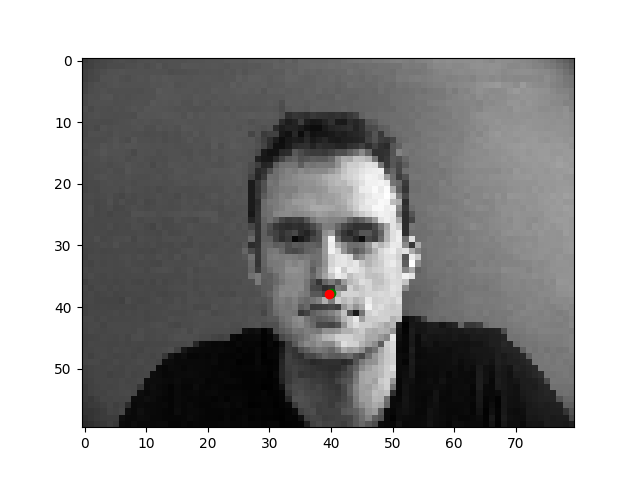
The images where the faces are directly facing the camera are easier to learn on, because there is little variation in skew and direction of faces. Their faces are a good size compared to the rest of the image and they are very centered.

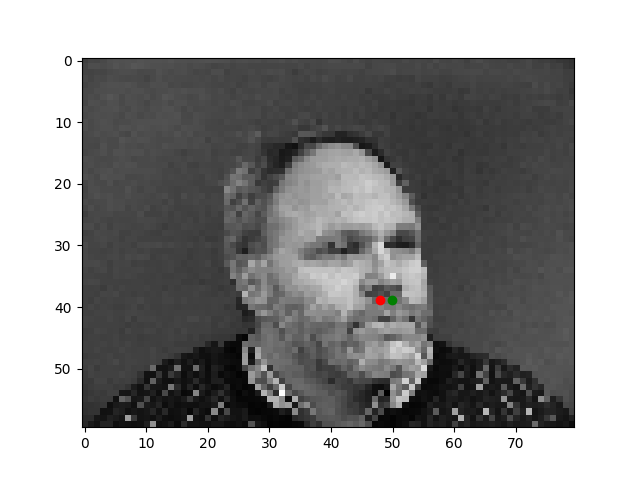
I believe these images that are at an angle are more difficult to train and result in inaccuracies in nosetip detection. This is most likely either caused by overfitting, since we didn't do transformations in this part of the project.
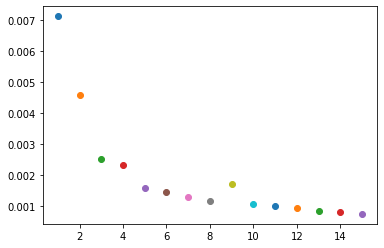
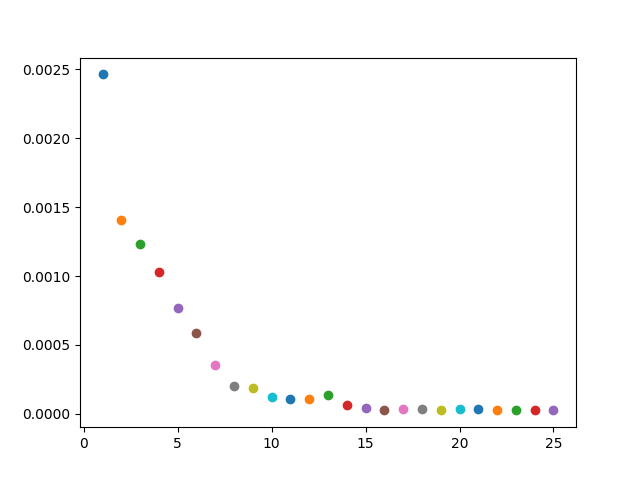
In this section, I trained the data on 6 CNNs, each with a size of 7x7. I also had 3 FC layers, and ran 25 epochs. I normalized the images, performed a random rotation between -15 and 15 degrees and a random shift between -10 and 10 for each direction, in order to prevent overfitting,.
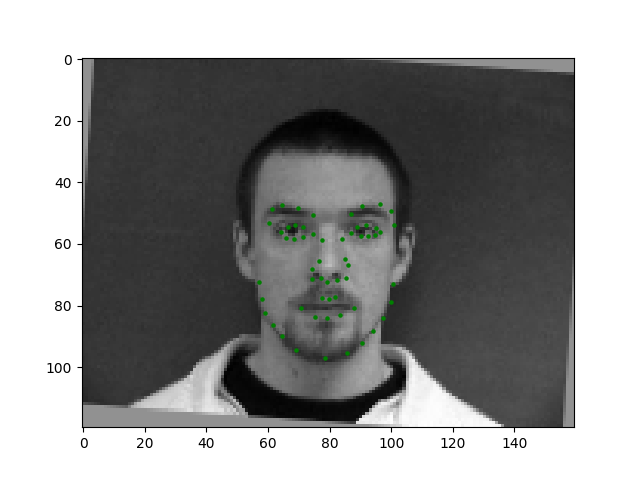
These first two images seem relatively accurate, because they are both facing straight towards the camera, and is relatively centered. The two people have very standard face shapes, making it easier to learn.

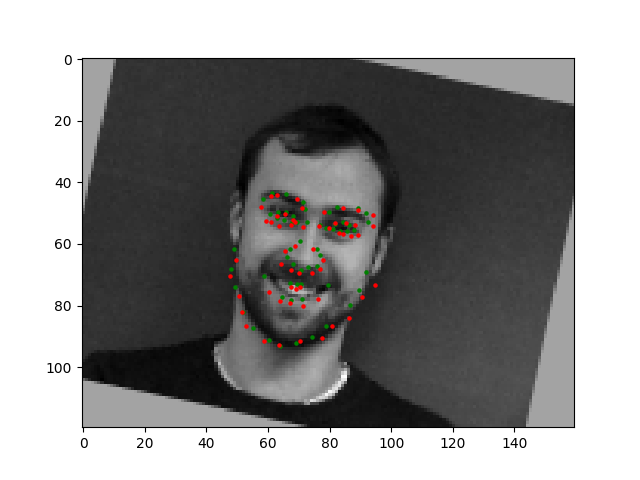
In the first image, the man's mouth is wrongly detected, perhaps because he has a bit of darker shading around that area from his chin. In addition, in the second face, the face shapes is somewhat unique, making it difficult to learn. His face is also relatively asymmetrical making it harder to learn.

In this section, I trained the data with ResNet18, which has 18 CNN, and ran 25 epochs. I performed data augmentation similar to part 2 on the training dataset, but did not on the test dataset.


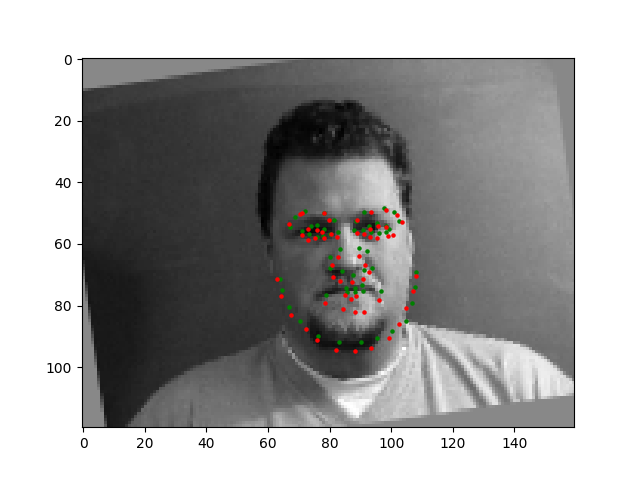
These didn't turn out as most of the training, because I think my model caused it to believe the left eyes of the faces are much higher than they are. It might be a bias in my model or some incorrect weights.



Kylie's face is detected nearly perfectly, because her face is very in focus and her face features are very prominent. Moreover, she's facing directly towards the camera.

Brads's face is slightly worse, as there's quite a bit of noise in this photo and it's more difficult to detect.

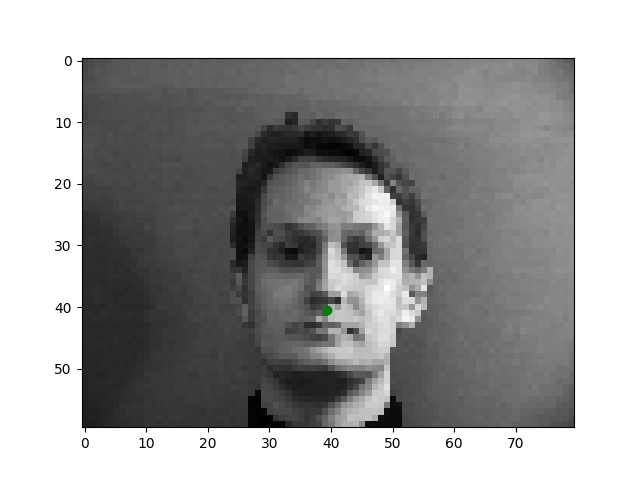
My face is detected carefully, most likely because I'm really far away from the camera, and the original colors and lighting were very distracting. In addition, my facial features are not as prominent.

In this section, I trained the model with antialised CNN resnet 50. This 50 layer model allowed for an improved predictions. I tried both Anti-aliased with 15 epochs and 25 epochs, and as it turns out the 25 epoch was less accurate than the 15 epoch, as I believe the model was overfit. However, the 15 epoch Anti-aliased did perform better than the 15 epoch non anti-aliased (part 3).