CS194-26 Project 4: Detecting Facial Keypoints
Christine Zhu
Overview
In this project, we'll be using neural networks with pytorch to detect facial keypoints. We compare performances between training on a smaller dataset (IMM Face) of about 244 images and a larger dataset of 6666 images. Our smaller dataset uses a simple CNN to detect noses and full facial keypoints, while the larger dataset uses transfer learning with a pretrained resnet18. To improve results, we've included data augmentation via random rotations and flips.
Part 1: Nose Detection
To start out, I had to make a pytorch dataloader with a custom dataset, whose return values consisted of a dictionary with the image as well as the nose point xy coordinates. Here are some sample images from the dataloader with the true nose in red:




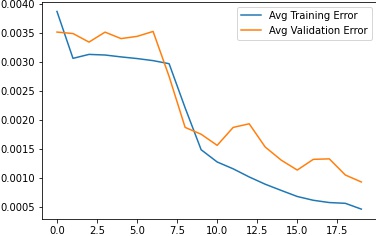
The training and validation accuracies for this dataset across epochs can be seen below. There were 20 epochs total during training.
Results
Here below, we see two good results and then two bad results. The predicted nose point is white, and the true nose point is red. Out of all the different learning rates I tried, .001 seemed to do the best. You can see that the model does a little bit worse with tilted / non-centered and front facing heads, indicating a lack of varied training data. We can hopefully improve this later using data augmentation.




Part 2: Full Facial Keypoint Detection
Now that we've built a model to predict a nose, we can extend this model to predict a full set of facial keypoints. Again, we have some sample images from our dataloader, which now has 2*58 landmarks instead of 2 landmarks (x and y for the nose).




Defining Network Architecture: CNN
Since we have a more complex problem with 68 points to predict, I included 6 convolutional layers in my model compared to around 3 layers for the nose. Each layer had padding of 1 or 2 with a larger kernel size of 5 in the first two layers and kernel size of 3 in the last 4 layers. I added a max pool layer to 3 out of 6 layers and every layer was followed by a ReLu. I originally had the output channels doubling each time, however, this produced a model that predicted the same average set of keypoints every time. After I changed the last several layers to stop at a max of 32 output channels then 24 output channels, the model was able to predict the facial keypoints.
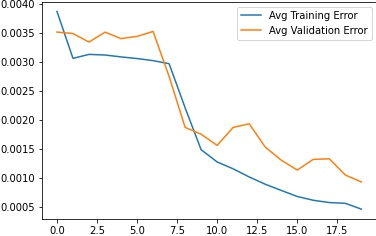
Training and Validation Error
Results on images
Again, we can look at two good results and then two bad results, with predicted points being in white and true points being in red. Like before, you can see that the model does a little bit worse with tilted / non-centered and front facing heads, and the points on those images tend to converge to the center. A shortage of varied training data (the model is learning front faces because they are prevalent and are an "average" of left tilt or right tilt) and absence of data augmentation is the likely reason for these failures.




Learned Filters
Something interesting we can do is we can take a look at the actual filters learned by our convolutional layers. The filters of our first convolutional layer are shown below: