Project 4: Facial Keypoint Detection with Neural Networks!
Overview
In this project, we attempt to detect the positions of a set of facial keypoints with convolutional neural networks in PyTorch.
Part 1: Nose Tip Detection
We write a custom dataloader, and scale images down to (80,60) pixels. Here are some of those images(pls zoom in a little cause the dots are tiny cause of resized images):

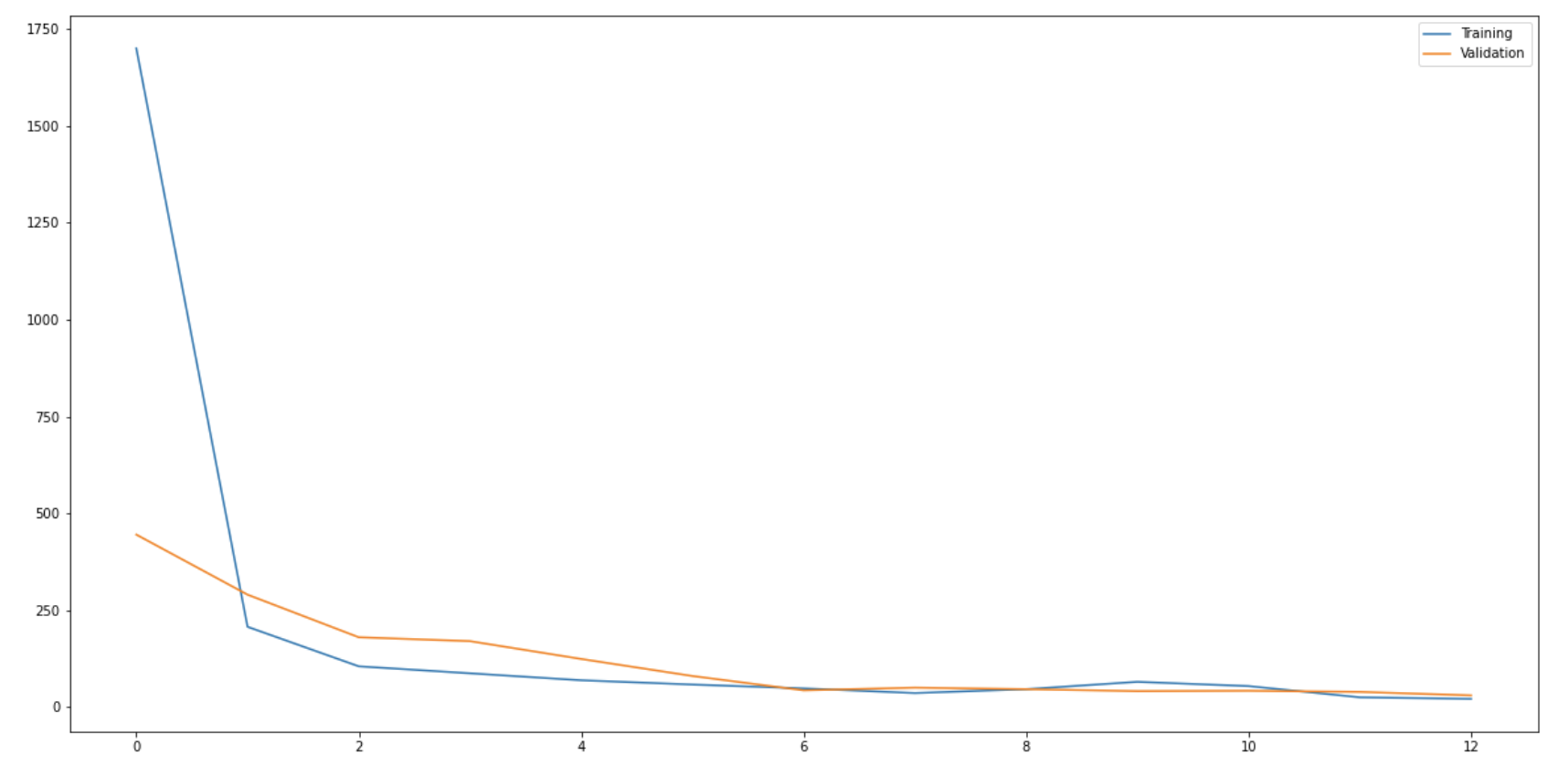
Here is the MSE loss of the pixel values on the (80,60) image. Both training loss and validation loss.
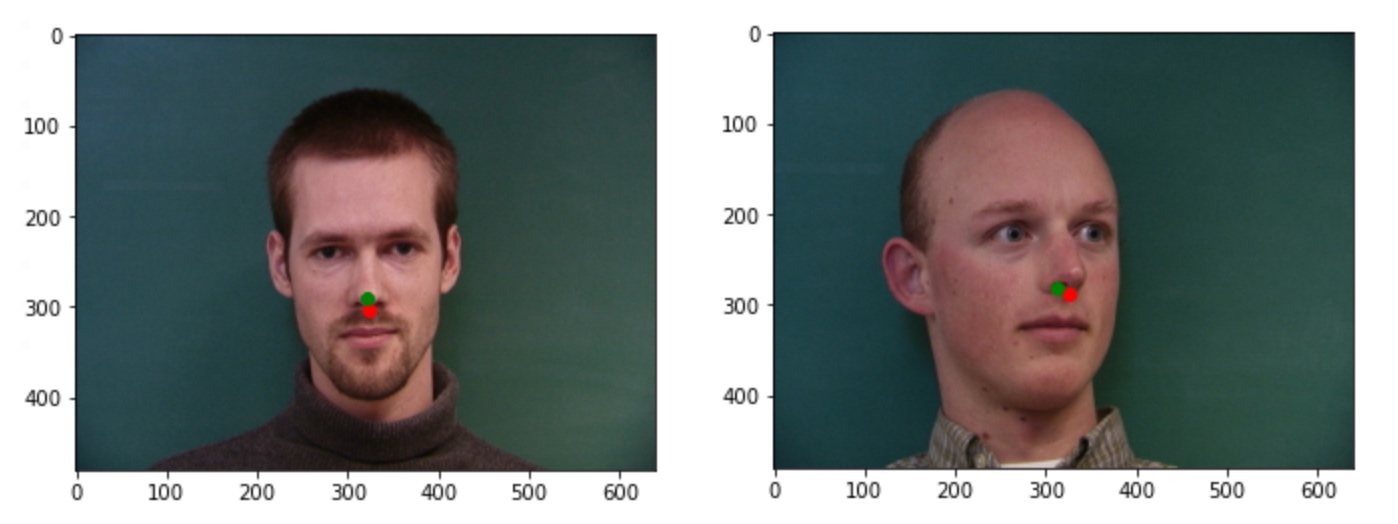
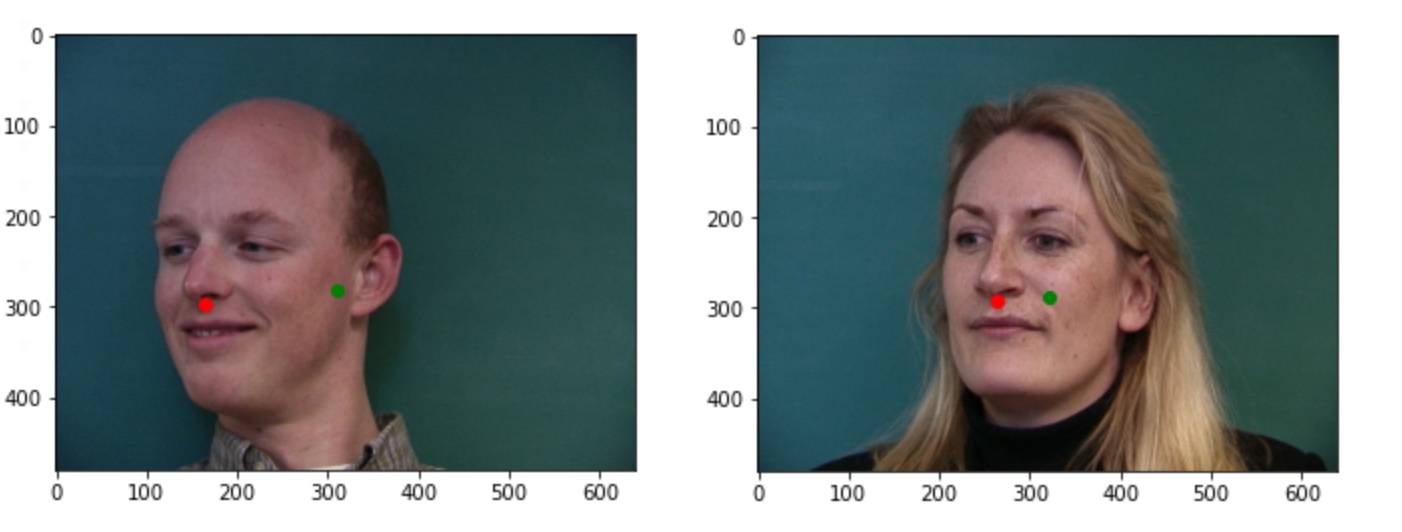
Here are some images that worked and some that didn't work. The ones where the people faced directly in front worked very well, with almost accurate results, but the cases where people turn their heads doesn't work well at all. This is probably because we have a very simple model with few layers and less data, so it doesn't generalize well. It hasn't learnt to capture the features yet or learn what a nose is, and is probably just learning to output a point near the center of the image.
Part 2: Full Facial Keypoints Detection
Now, we want to detect on all the 58 keypoints on the faces. Here are some faces with augmentation applied. You can see that some of them are x-shifted. Some are y-shifted and some are shifted in both x & y. I also did jittering where I distorted the image slightly.

Here I've printed out my model's layers:

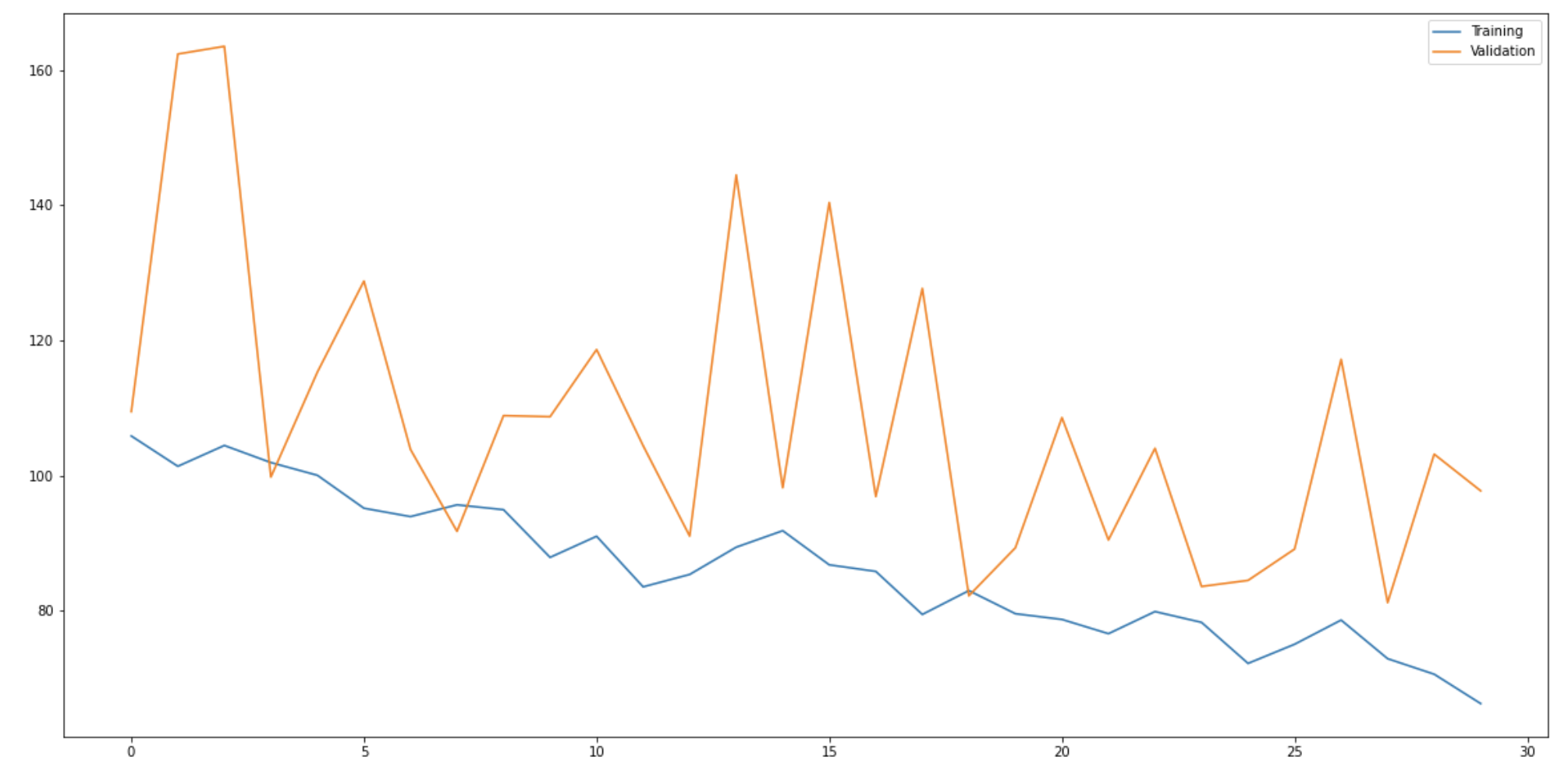
I ran my model for about 30 epochs and I observe that my training loss converges. Also, I used a batch size of 8 while training and a learning rate of 1e-4.
Please note that the loss is MSE over the absolute pixel values and not a ratio. So, loss is calculated based on how far pixels are in the image of size 180 * 240.
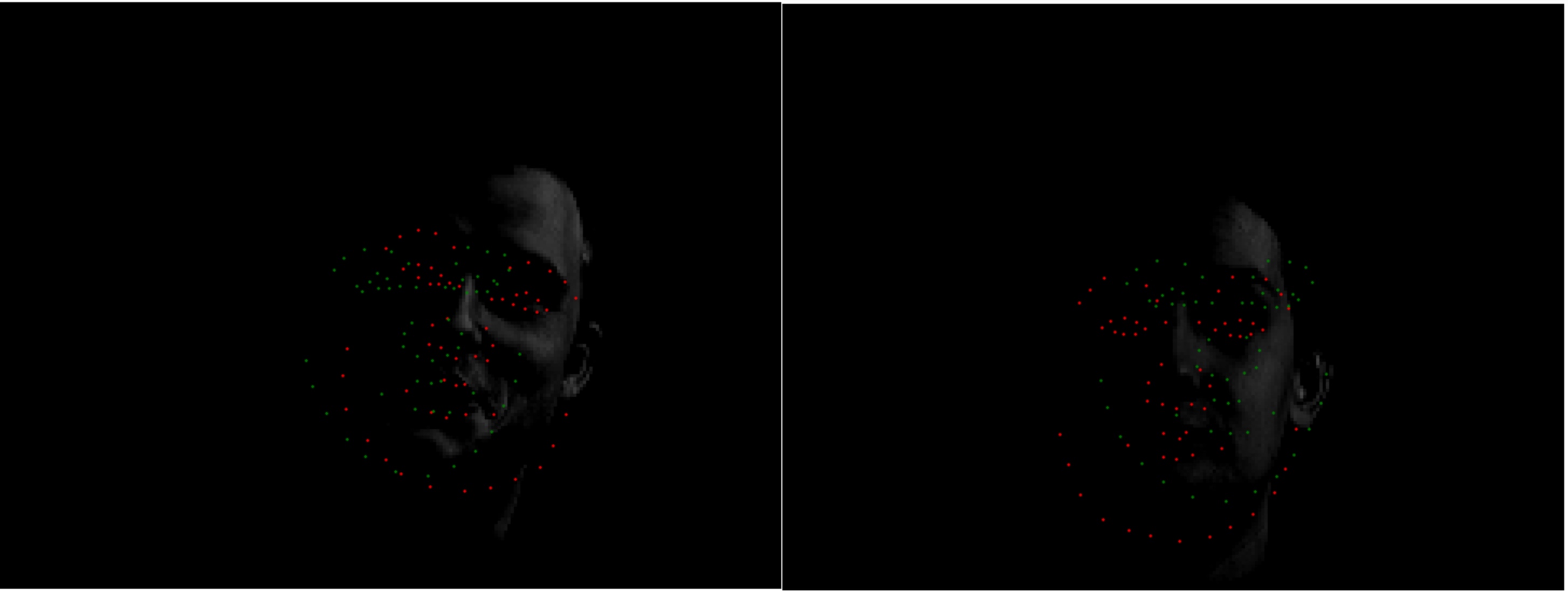
Here are some cases that work and some that don't. Similar to part 1, the model result is most accurate visually when the subject's face is front-facing. But for some cases where it turns, we are able to get points pretty close to the ground truth. Interestingly, the same bald subject (row 4, right image) also has the worst results in this part. I suspect the failures are because of slightly off centre faces. On the one on the left, the guy's face is slighty tilted.

Now, let's see how the filters look in the first conv and second layer.


Part 3: Train With Larger Dataset
My architecture is essentially Resnet 18 with the following changes for input and output:
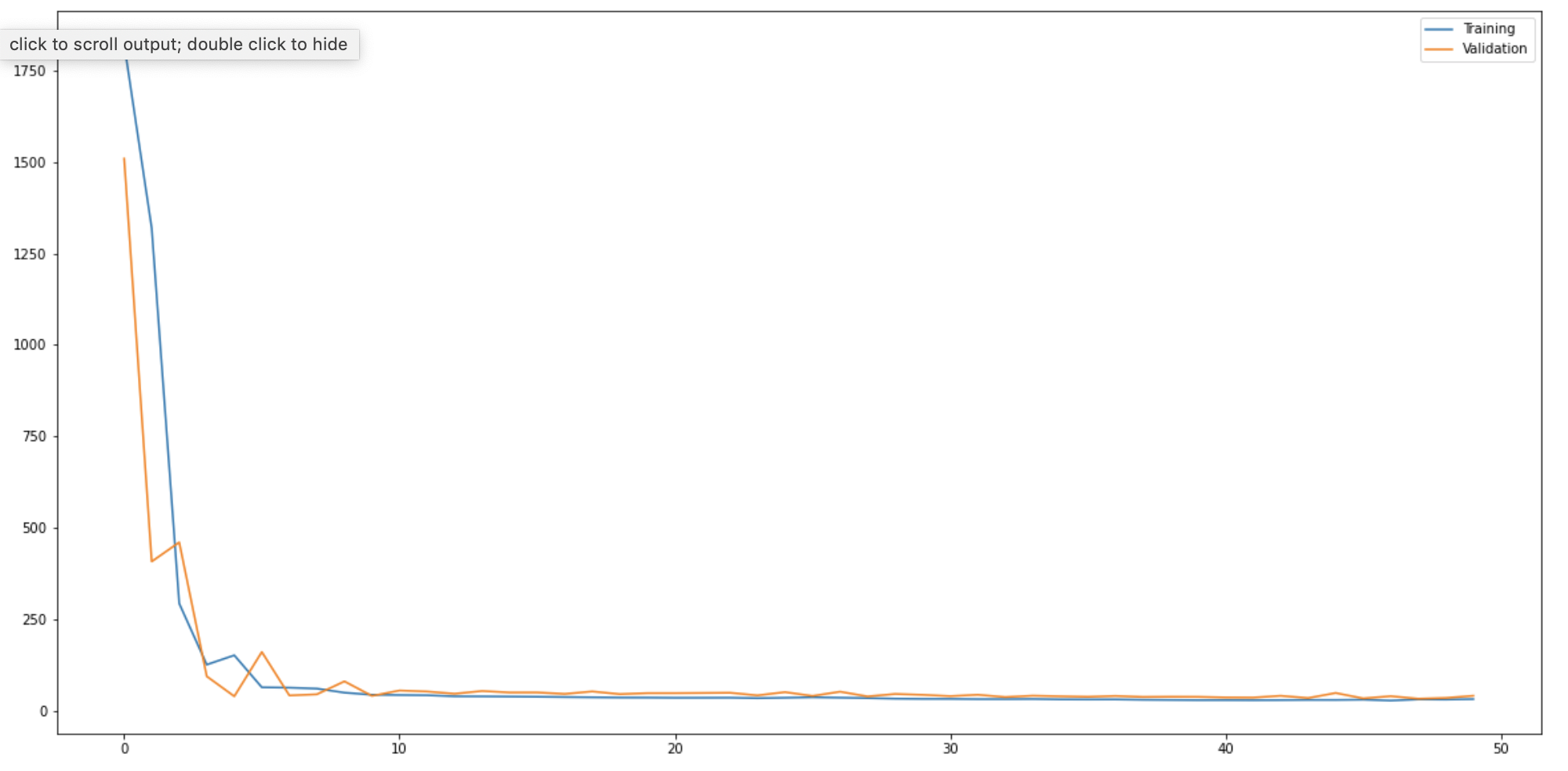
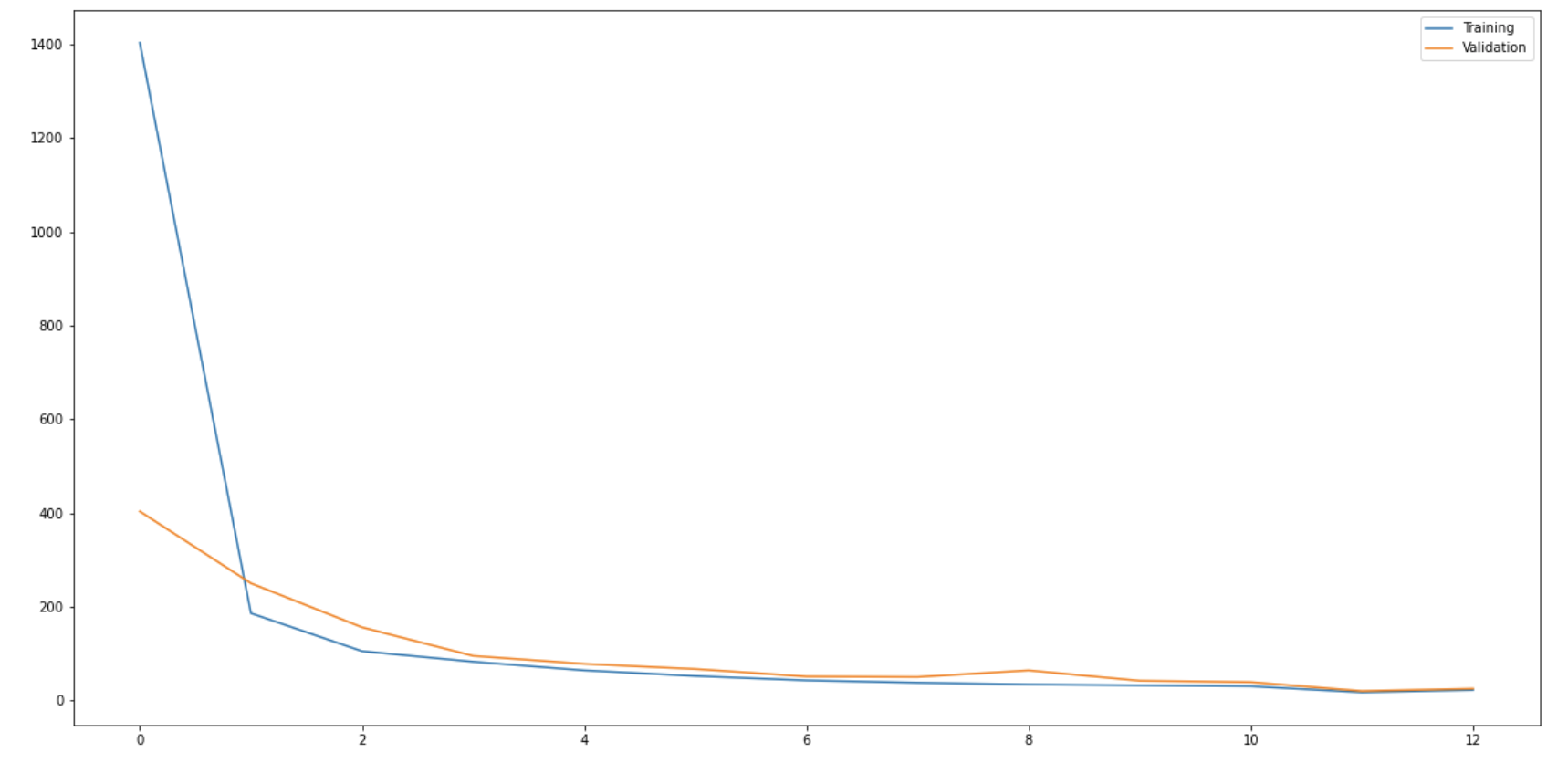
After 9 epochs, my training and validation both seem to flatten out. The model architecture is essentially resnet18, with small modifications to fit my input data and output size. I used a batch size of 6 and a learning rate of 1e-4 during training.
Here are some visualizations from the test set, with predicted keypoints. they seem to do better than the

Here are some visualizations from my own photos It seems that the model is fairly accurate in these photos, with the exception of the photo of iron man. This is probably because while the shape is similar to that of a face, lots of key features are missing, like eyebrows and nose and a mouth.

Extra Credit: Bells and Whistlesno
I used anti-aliased version of Resnet 18 on part 2 to see if it would improve accuracy for the full keypoint detection. Model was not pre-trained. Here is a prinout fo the model's parameters and layers. The same changes were made to input and output layers as in the regular Resnet 18.

Results were the following, not that much difference. It started with with a higher loss and then after 12 epochs was around the same as regular resnet. Perhaps more can be explored by applying the idea of blur pooling to only certain layers. It is also possible that using pre-trained models would perform better, since in the actual paper they compare pre-trained models versus anti-alias pretrained models