Facial Keypoint Detection with Neural Networks
Thanakul Wattanawong 3034194999
For this project I built neural networks from scratch and also used pre-existing ones to predict facial keypoints in a variety of situations.
Part 1: Nose Tip Detection
Here are a couple of sampled images from my dataloader with ground-truth keypoints:

After training, here’s my train and validation accuracy over 25 epochs:
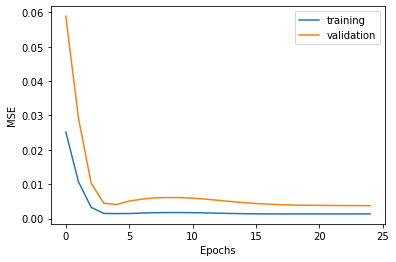
Here are two examples of when it worked correctly. I think this worked well because they were facing straight towards the camera and their face was fully upright, which is the overall average position. Also, it could be possible that the network has learned the middle region exceptionally well.
Red is ground truth and blue is prediction.


Here are two examples of when it failed. I think this is due to the fact that the face was looking off center, and so the network is not as confident where the nose is since there’s not a lot of data for each way the face looks.
Red is ground truth and blue is prediction.


Part 2: Full Facial Keypoints Detection
Here are a couple of sampled images from my dataloader with ground-truth keypoints:




Here’s the architecture of my model:
NetBig(
(conv1): Conv2d(1, 60, kernel_size=(3, 3), stride=(1, 1)) # Relu
(conv2): Conv2d(60, 60, kernel_size=(3, 3), stride=(1, 1)) # Relu and Maxpool width=2
(conv3): Conv2d(60, 60, kernel_size=(3, 3), stride=(1, 1)) # Relu and Maxpool width=2
(conv4): Conv2d(60, 60, kernel_size=(3, 3), stride=(1, 1)) # Relu and Maxpool width=2
(conv5): Conv2d(60, 60, kernel_size=(3, 3), stride=(1, 1)) # Relu and Maxpool width=2
(conv6): Conv2d(60, 60, kernel_size=(3, 3), stride=(1, 1)) # Relu and Maxpool width=2
(fc1): Linear(in_features=180, out_features=5000, bias=True) # Relu
(fc2): Linear(in_features=5000, out_features=300, bias=True) # Relu
(fc3): Linear(in_features=300, out_features=116, bias=True)
)
Reading guide: conv refers to convolutional layers, where the first argument is the input channels and second is the output channels. fc refers to the fully connected layers and the in/out features are described by keyword arguments. The bias keyword indicates if the FC layer should learn a bias. The comment refers to if I applied ReLU or Maxpool after that layer.
I chose a filter size of 3 for all the convolutional layers and a batch size of 100.
I chose to use input images of size 160x120 and augmented them by another 1x (so dataset size is total 2x) using random rotations up to 15 degrees, random shifts up to 10px, and color jitters with p=0.5. I used the Adam optimizer with learning rate 1e-3 and MSE Loss. I chose to train for 60 epochs to get as good results as possible. Here’s the MSE over epochs:
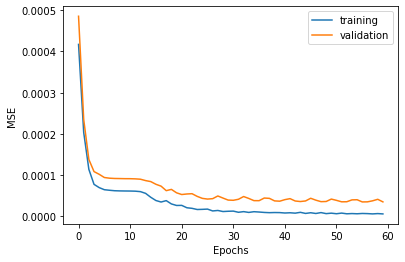
I probably didn’t need to train for this long after 40 epochs.
Here are a couple of good examples of success:
Red is ground truth and blue is prediction

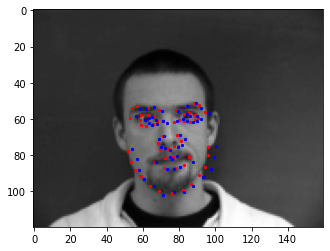
Again I think the chief factor here is whether they were looking straight and how rotated the image was.
Here are a couple of bad examples:


Clearly in the left the eye is predicted as much lower than normal, while in the right side the eye detection just breaks apart. For the left I suppose it’s just him looking slightly away, while for the right side it’s that and his weird eye opening motion.
Again, anything that deviated too far from a center person looking straight at the camera suffered worse results, including just becoming a jumbled mess of points.
Using the excellent filter visualization code from the TA-provided link here, I was able to visualize my CNN’s filters. This is an example for conv1 which has 60 output channels:
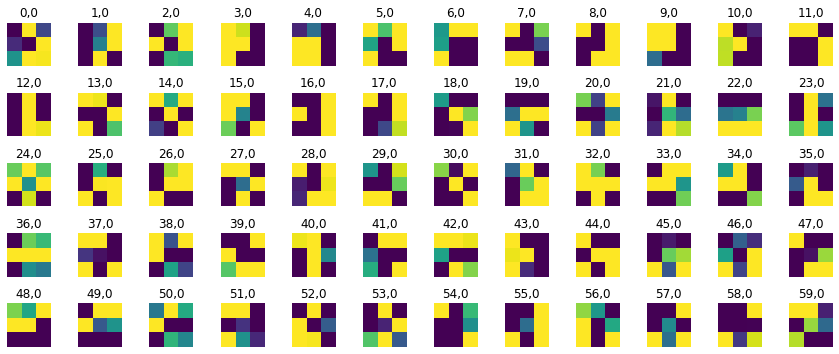
Part 3: Train With Larger Dataset
The best performance I was able to attain on Kaggle was 11.63835. However I lost that model due to some careless mistakes (somehow the saving did not work properly and I could not replicate the results after restoring the model during prediction) and so to avoid retraining I just did my part 3 writeup based on the AA version. I already have the graphs and some predicted images from training without AA so I used that to compare in extra credit.
The model that I used to achieve the results below was ResNet-18-Antialiased by Richard Zhang with all defaults except the first layer has 1 input channel and the last layer has 136 output channels. In order to avoid bogging down this document the detailed architecture of ResNet-18-Antialiased + my modifications is in the Appendix. The comparison with the base ResNet-18 with the same hyperparameters is done in Bells and Whistles.
I chose Adam again with learning rate 1e-3, and trained for 50 epochs with a batch size of 100 which was the max my GPU could support. I augmented my data by an additional 2x (so 3x total data) using the same rotation scheme as part 2. I saved the last 15% of the data for validation.
Here is the graph of the train and validation errors:
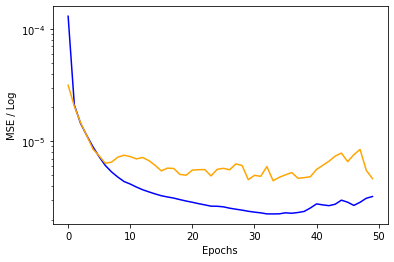
This is showing some signs of bad learning after around 35 epochs so for the competition I will adjust that.
Here are some images along with their keypoints prediction in the testing set:
Idx: 300 | Idx = 0 |
Idx: 200 | Idx: 283 |




Honestly these results are pretty good and it was hard to find any that were absolutely terrible.
Here is the model running on some images from my collection:
Good examples:


It probably gets it right on these because everyone is looking fairly straight at the camera and the rotation is minimal.
Bad examples:


I’m guessing the reason these were predicted wrong is on the left the facial shape is very weird compared to most humans and he is looking slightly down, causing the detection to be off. For the right image, I did not train on high angle rotations and so it’s reasonable that the net would not be able to recognize facial features.
Bells and Whistles
I decided to try out the anti-aliased version of ResNet that Richard Zhang proposed. I used the exact same setup as part 3 and in theory this should be a drop-in replacement for ResNet. Apparently this stabilizes outputs and improves accuracy, and it might help with the shaky loss we were seeing in the later epochs. In part 3 I decided to do my writeup based on the antialiased model but here I compare with non-AA results with same hyperparameters.
Let’s compare the training graphs and final errors after 50 epochs side by side:
No AA | AA |
Final train MSE: 2.89e-6 Final validation MSE: 3.35e-6 | Final train MSE: 3.2e-6 Final validation MSE: 4.63e-6 |
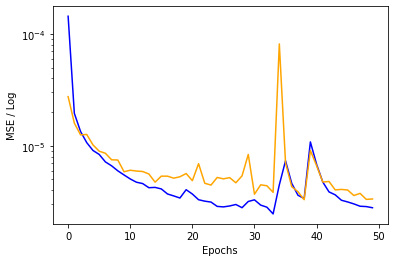
Clearly AA resnet was much more stable in training over time compared to no AA. The error ended up being slightly higher at high epochs though.
And comparing the same test images to see the visual quality:
Index | ResNet-18 | ResNet-18-Antialiased |
0 | ||
200 | ||
283 | ||
300 |




Visually there is basically no difference and I think the difference if any are minimal. When I tested on Kaggle the AA model was only slightly worse than the best model I had ever submitted.
Appendix
ResNet-18-Antialiased modified architecture
Reading guide is the same as that of part 2, except there are more parameters. This network is based off of Zhang et al’s AA ResNet.
ResNet(
(conv1): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): Sequential(
(0): MaxPool2d(kernel_size=2, stride=1, padding=0, dilation=1, ceil_mode=False)
(1): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=136, bias=True)
)
References
Zhang, R. (2019). Making convolutional networks shift-invariant again. ArXiv:1904.11486 [Cs]. http://arxiv.org/abs/1904.11486