Facial Keypoint Detection with Neural Networks
by Huy HoangOverview
The goal of this project is to create a neural netowork model that automatically detects 68 facial keypoints of an input image using PyTorch.
Each of the following parts consists of the following steps:
- Defining a DataLoader: this steps loads the images and their corresponding keypoints as well as perform necessary data transforms and augmentations:
- Converting image to grayscale
- Normalizing the pixel values in the range
[-0.5, 0.5] - Rescaling the image
- Randomly rotating each image
- Randomly adjusting the brightness, hue, and saturation of each image
- Defining a CNN: this step defines a convolutional neural network, loss function and optimizer function.
Nose Tip Detection
Below are some images from my DataLoader and their ground-truth keypoints



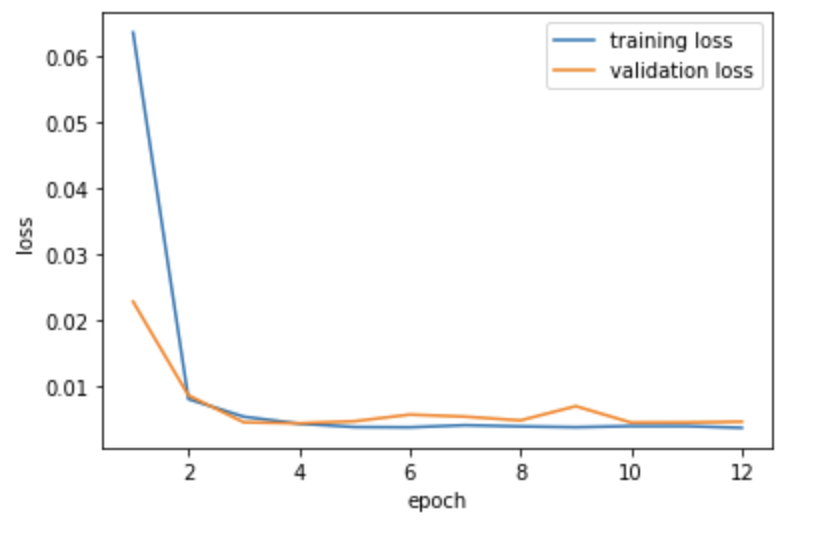
For this part, I defined a neural network with 3 convolutional layers, each followed by a ReLU and MaxPool. I used Mean Square Error (MSE) loss function and Adam optimzer function. I trained the model for 12 epochs and below is the graph showing how my training and validation error changed over each epoch.header
And finally, the results! Here I'm some images where the model predicts well and some where it doesn't predict well, with the ground truth points in red and predicted points in green. I suspect that the bad ones are because of angles, variations in pixel intensities, etc.




Full Facial Keypoints Detection
For this part, I'm also adding some data augmentations to my DataLoader, particularly random rotation and color jittering.



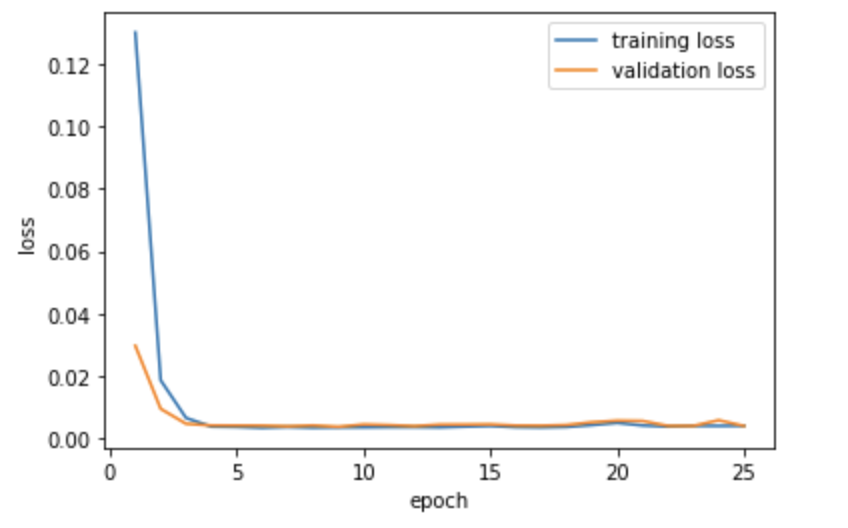
For my neural network, I had 5 convolutional layers and 2 fully connected layers. I trained for 25 epochs with a batch size of 16. My learning rate was 0.001 and I also used MSE loss function and Adam optimizer.

Here I'm some images where the model predicts well and some where it doesn't predict well, with the ground truth points in red and predicted points in green. I suspect that the bad ones are because of angles, variations in pixel intensities, etc.




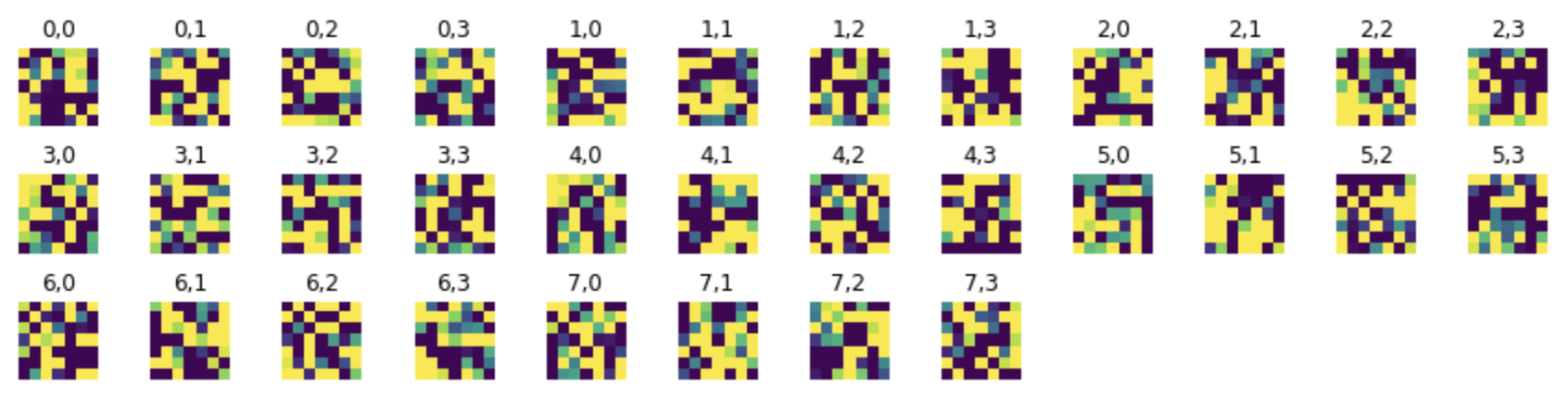
Filters for the first convolutional layer:

Filters for the second convolutional layer:
Train with Larger Dataset
For this part, I used the anti-aliased ResNet-50 model proposed by Richard Zhang. Introducing anti-alising to CNNs such as ResNet-50 make them more shift-invariant, and as a result, I observed an increase in accuracy compared to the baseline ResNet-50 model. Details of my model is shown below.

|

|

|

|
During training, I used the L1 loss function and Adam optimizer with a learning rate of 0.001. I decided on the L1 loss function through trial and error, as I noticed it produced lower validation loss than the MSE loss function. I trained the model for 25 epochs with a batch size of 16.

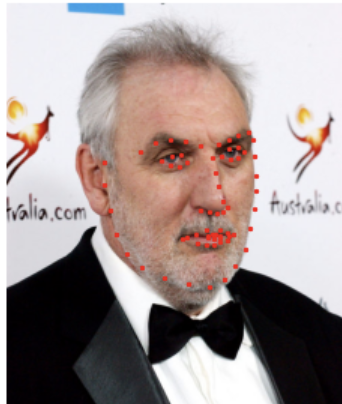
This model has a mean absolute error of 7.24 in our Kaggle competition. Not bad at all :)
Some images and their corresponding keypoint predictions:
|

|

|

|

|