
|
|
The goal of this project is to use neural nets to automatically detect facial keypoints of images of peoples' faces.
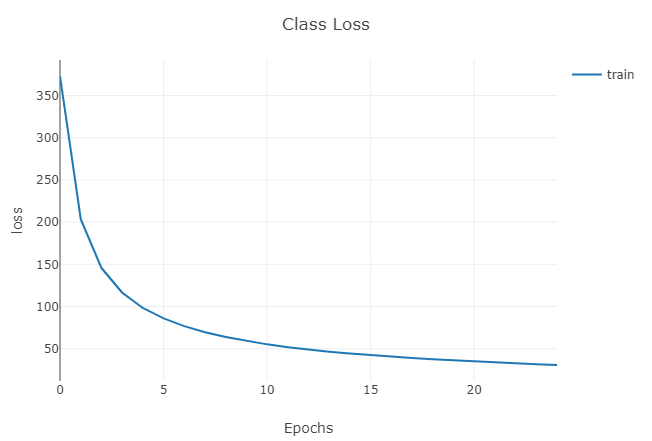
For the first neural net I used 3 convolutional layers with 12, 22, and 32 channels with kernel sizes 5, 6, and 3 respectively (should have been 7 instead of 6 but it was a typo and I didn't want to re-run the net again). I trained 25 epochs with a learning rate of 0.001.
|
|
|
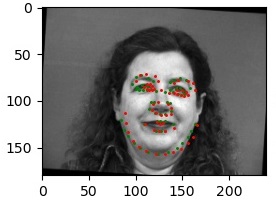
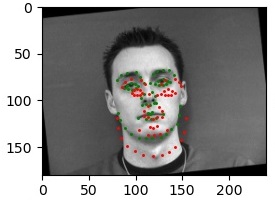
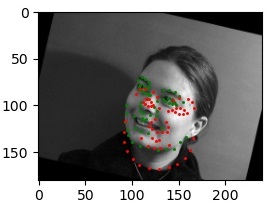
For the two images to the left, all of the predicted points happened to be around the right corner of his mouth, distinctly more so in the images where his head was turned. It may also be due to the lighting, with features on the illuminated side of his face showing up more prominently than central and left features, that the neural net chooses the right corner as the nose keypoint.
For the two images to the right, his face was more consistently illuminated, and in the variants where his head was turned the predicted nose keypoint wasn't as far off from the ground truth as the first man's was. The consistent illumination was a significant factor in the better results in this case.
This neural net has 5 convolutional layers, with (12, 7), (22, 5), (32, 3), (27, 3), and (27, 3) channels and kernel size per layer. I trained the net on an augmented data set (3 sets of random rotations so 4x the total number of images) for 25 epochs at a learning rate of 0.003.
Net( (conv1): Conv2d(1, 12, kernel_size=(7, 7), stride=(1, 1)) (conv2): Conv2d(12, 22, kernel_size=(5, 5), stride=(1, 1)) (conv3): Conv2d(22, 32, kernel_size=(3, 3), stride=(1, 1)) (conv4): Conv2d(32, 27, kernel_size=(3, 3), stride=(1, 1)) (conv5): Conv2d(27, 27, kernel_size=(3, 3), stride=(1, 1)) (fc1): Linear(in_features=10368, out_features=6900, bias=True) (fc2): Linear(in_features=6900, out_features=116, bias=True) )

|
|
|
|
The left failed prediction seemed to have identified the man's Adam's Apple as his chin and his chin as his mouth, and as such predicted its keypoints shifted down from the actual. The right failed prediction identified the line between the woman's neck and clothes as her jawline and predicted keypoints based off of that.
Modified ResNet18 structure
ResNet( (conv1): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (layer1): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (1): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer2): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer3): Sequential( (0): BasicBlock( (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer4): Sequential( (0): BasicBlock( (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) (fc): Linear(in_features=512, out_features=136, bias=True) )
I wasn't able to plot the losses during testing but most likely had a similar 1/x appearance like the other graphs, going from an average 8000 loss at epoch 0 to an average 50 loss at epoch 24, with the lowest individual losses around 10.
|
|
|
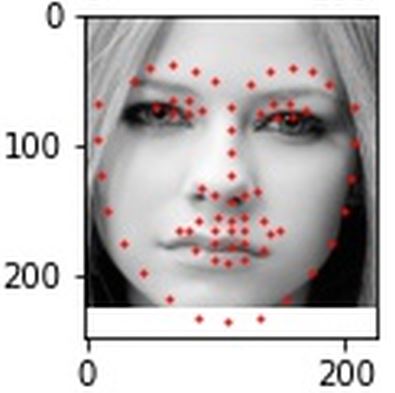
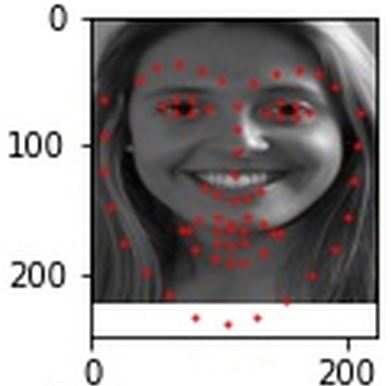
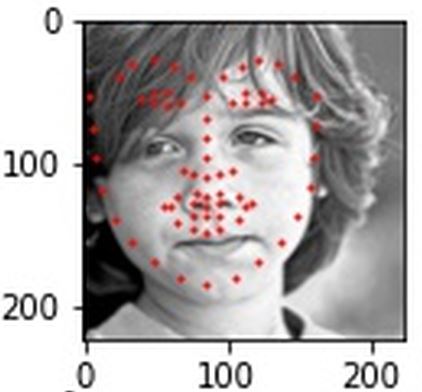
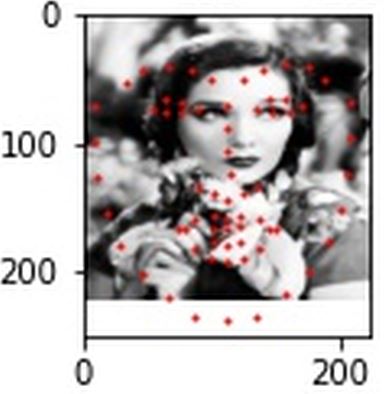
These predictions on the test set came out alright, far from good predictions but some of the best I had. The left and right ones turned out fairly accurate, the middle one at least got the eye keypoints correct.
|
|
|
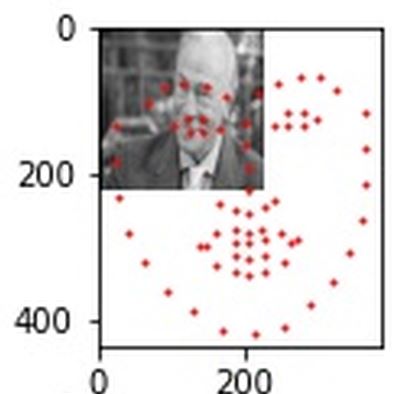
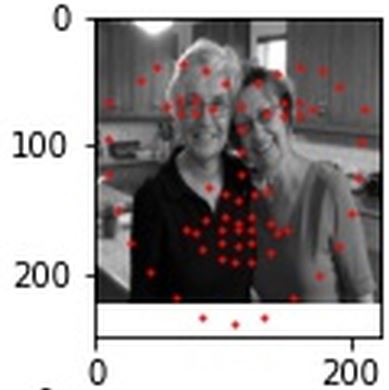
These predictions on the test set are... less successful, and this is the case for the majority of my predictions. Something may be wrong with my dataloader or ground-truth-keypoint-resizing calculations, since some of the predicted keypoints are waayyyy off, some not even on the image at all. Additionally, the neural net was not trained to handle multiple faces to my knowledge, but there was one case where the net struck in the general ballpark of one of two faces in this image.
|
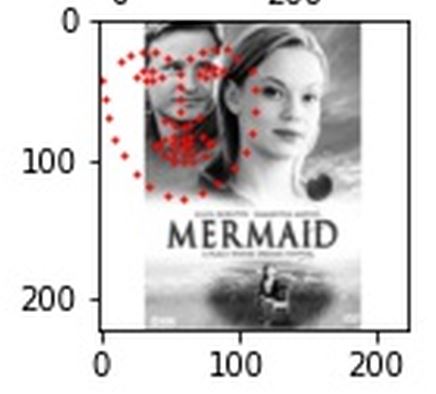
At least the predicted keypoints are centered on the man's face rather than completely off the image.