CS194 PROJECT Four - Alex Wu
Part One - Nose Tip Detection
For the nose tip detection, I have used a relatively smaller convolutional network. My network has three convolutional layer and three fully connected layer. The network takes in an image with one channel and output a vector of size two. Here are the detailed paramters:
- (conv1): Conv2d(1, 16, kernel_size=(7, 7), stride=(1, 1))
- (conv2): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1))
- (conv3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1))
- (fc1): Linear(in_features=1152, out_features=210, bias=True)
- (fc2): Linear(in_features=210, out_features=20, bias=True)
- (fc3): Linear(in_features=20, out_features=2, bias=True)
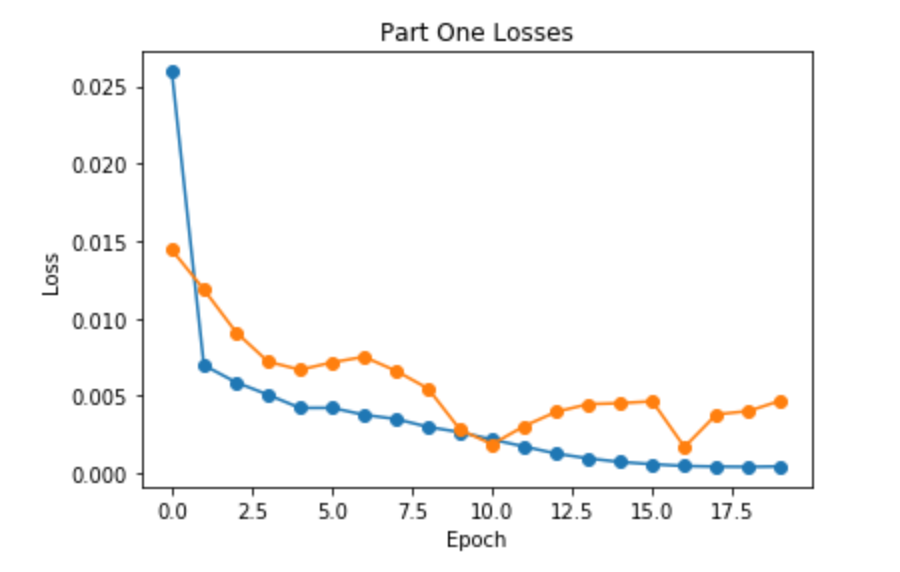
Here are the loss during the training process and verification losses. Blue line is the training loss and yellow line is the verfication loss.
Here are some example output image with ground-truth keypoints as green and the output label as red. For these two images, the network's output is relatively pretty accurate.


Here are two images that the network does not perform well. The reason that the network fails in these cases is that the resolution of the image is not enough, and sometimes, the network will simply take a point that locates near the center and near a relatively darker spot instead of the actual nose.


Part Two - Full Facial Keypoints Detection
For the full facial detection, I have used a convolutional network with more convolutional layer. My network has six convolutional layer and two fully connected layer. The network takes in an image with one channel and output a vector of size 116. For training, I have used a batchsize of one and trained for 20 epochs. Here are the detailed paramters:
- (conv1): Conv2d(1, 8, kernel_size=(7, 7), stride=(1, 1))
- (conv2): Conv2d(8, 16, kernel_size=(7, 7), stride=(1, 1))
- (conv3): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1))
- (conv4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1))
- (conv5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1))
- (conv6): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1))
- (fc1): Linear(in_features=2048, out_features=500, bias=True)
- (fc2): Linear(in_features=500, out_features=116, bias=True)
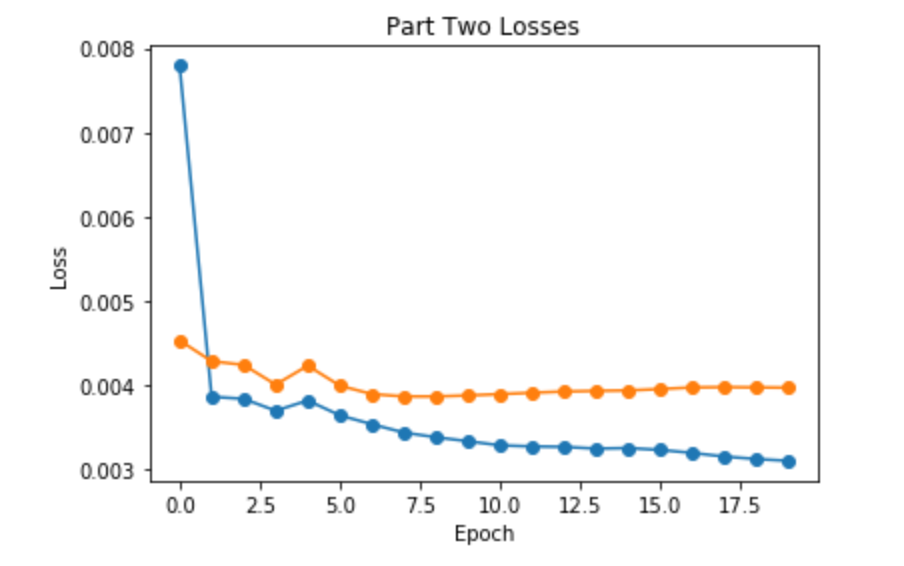
Here are the loss during the training process and verification losses. Blue line is the training loss and yellow line is the verfication loss.
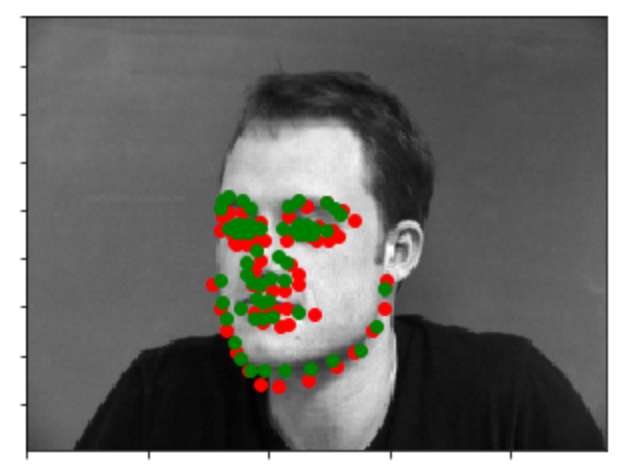
Here are some example output image with ground-truth keypoints as green and the output label as red. For these two images, the network's output is relatively pretty accurate.

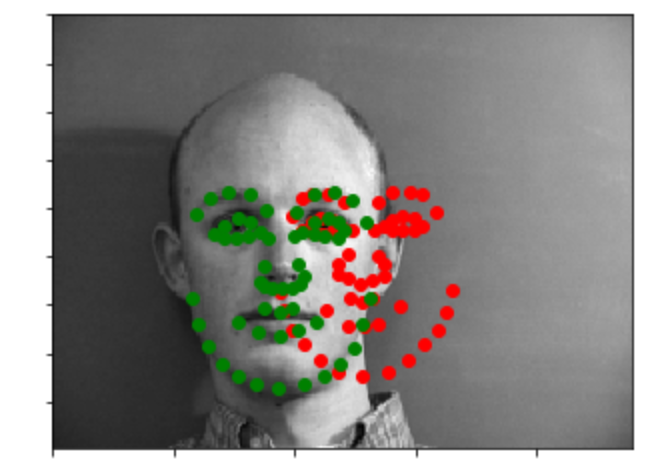
Here are two images that the network does not perform well. The reason that the network fails in these cases is that both of the faces are a little bit off-centered. You can see that the network still is able to capture the edge and the shape of the face quite well, but the offset is wrong.

Here's the learned filters in the first layer with a width of seven.

Part 3 - Train With Larger Dataset
For the full facial detection, I have used resnet18 and slightly alter the architecture of the resnet18. I have used ten epoch to train the model, and the batch size is one. The architecture of my net only differs from the original resnet18 in two aspects: the input layer receives a one-dimensional image input, and the output layer outputs a vector of size 136. The final score that I received on Kaggle is 10.20.
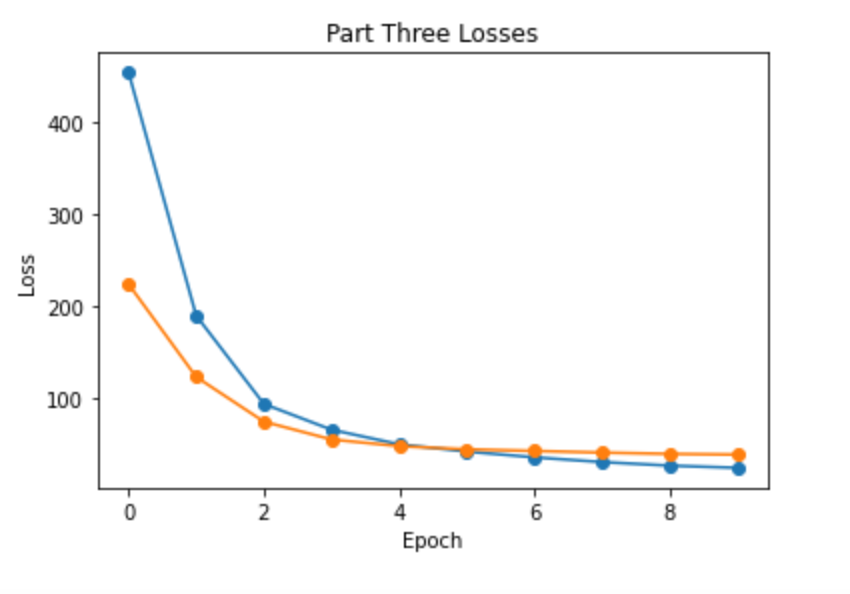
Here are the loss during the training process and verification losses. Blue line is the training loss and yellow line is the verfication loss. The reason for the relatively high losses is because instead of converting the pixel position to relative position, I have used absolute posintioning. This results in a higher scale of the loss.
Here are some example output image from the test dataset.
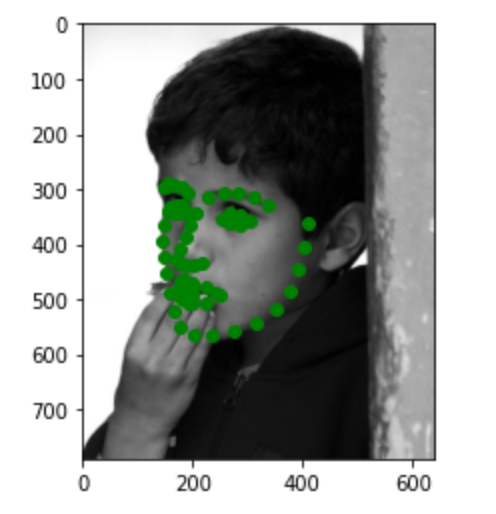
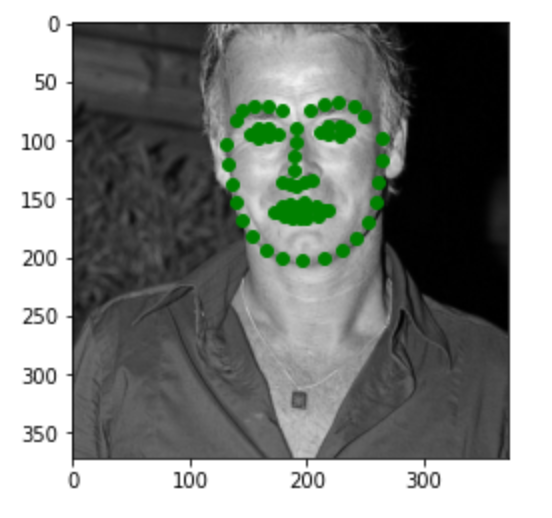
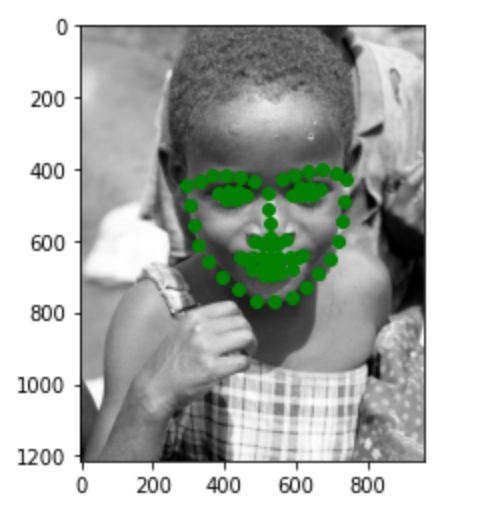
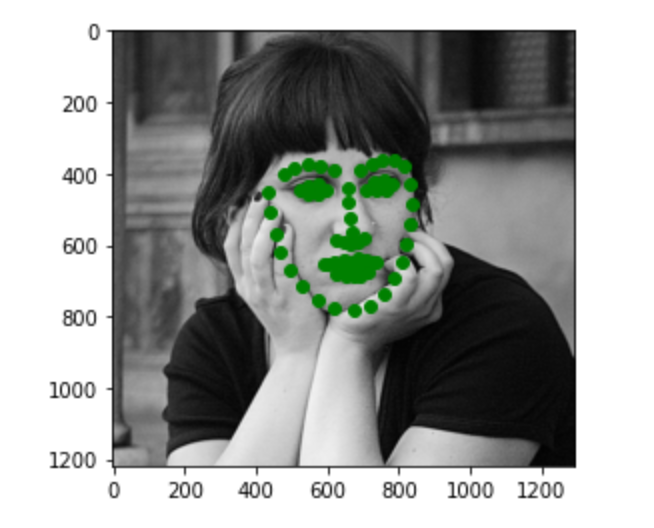
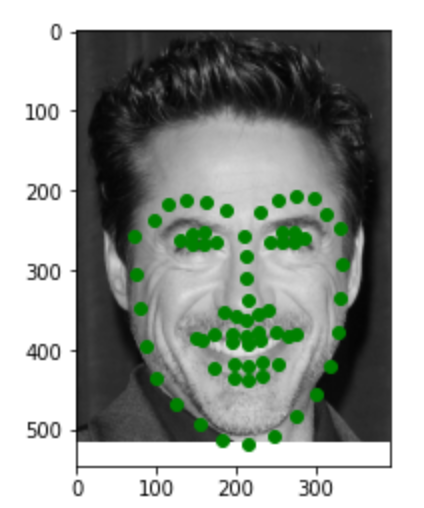
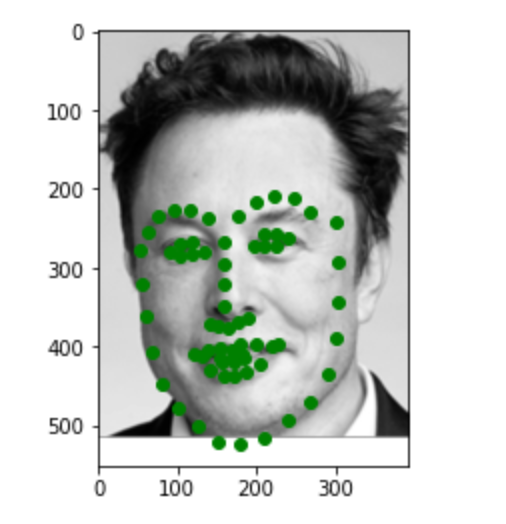
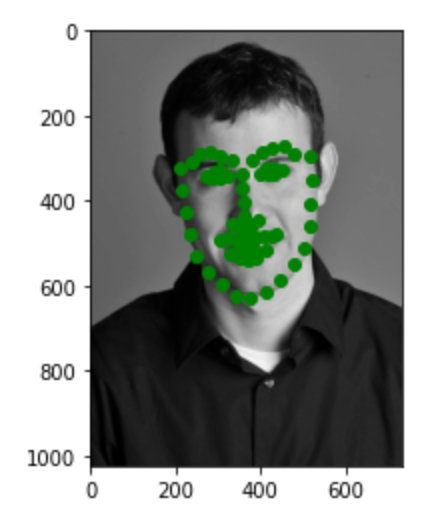
Here are three images of my choices. Most of the points are pretty accurate. In the first image, the point for the lips is a little bit off. This may be due to the large smile on the face.