Project 4 CS 194-26: Facial Keypoint Detection with Neural Networks
By Diego Uribe
Project Description
In this project, I used CNNs to automatically detect facial keypoints. I used PyTorch as the deep learning framework. In the first part I worked on detecting the nose tip location while in the second part I worked on detecting 58 facial keypoints. Finally, in the last part I worked on detecting 68 facial keypoints from a large dataset.
Part 1: Nose Tip Detection
In this part I worked on detecting the nose tip of faces in the IMM Face Database. For this I first divided the dataset into training and validation sets. The training set had 192 images, while the validation set had 48 images. Then I defined a dataLoader that converted the images to grayscale and normalized them in the range -0.5 to 0.5. After that, I rescaled the images to be 80x60. Then, I defined a CNN to predict the nose tip location. The architecture of the CNN was as follows:
- nn.Conv2d(1, 12, 3) followed by a ReLu and a max pool layer with kernel size 2.
- nn.Conv2d(12, 32, 5) followed by a ReLu and a max pool layer with kernel size 2.
- nn.Conv2d(32, 20, 3) followed by a ReLu and a max pool layer with kernel size 2.
- nn.Conv2d(20, 12, 3) followed by a ReLu and a max pool layer with kernel size 2.
- nn.Linear(12 * 2 * 1, 10) followed by a ReLu.
- nn.Linear(10, 2)
For training I used Adam as the optimizer and MSELoss as the loss function. I also used 0.01 as the learning rate and ran for 50 epochs.
Sampled Images from Data Loader with Ground-Truth Points

Training Samples (before transformation)

Validation Samples (before transformation)

Training Samples (after transformations), ready to feed to network
Train and validation accuracy during the training process.
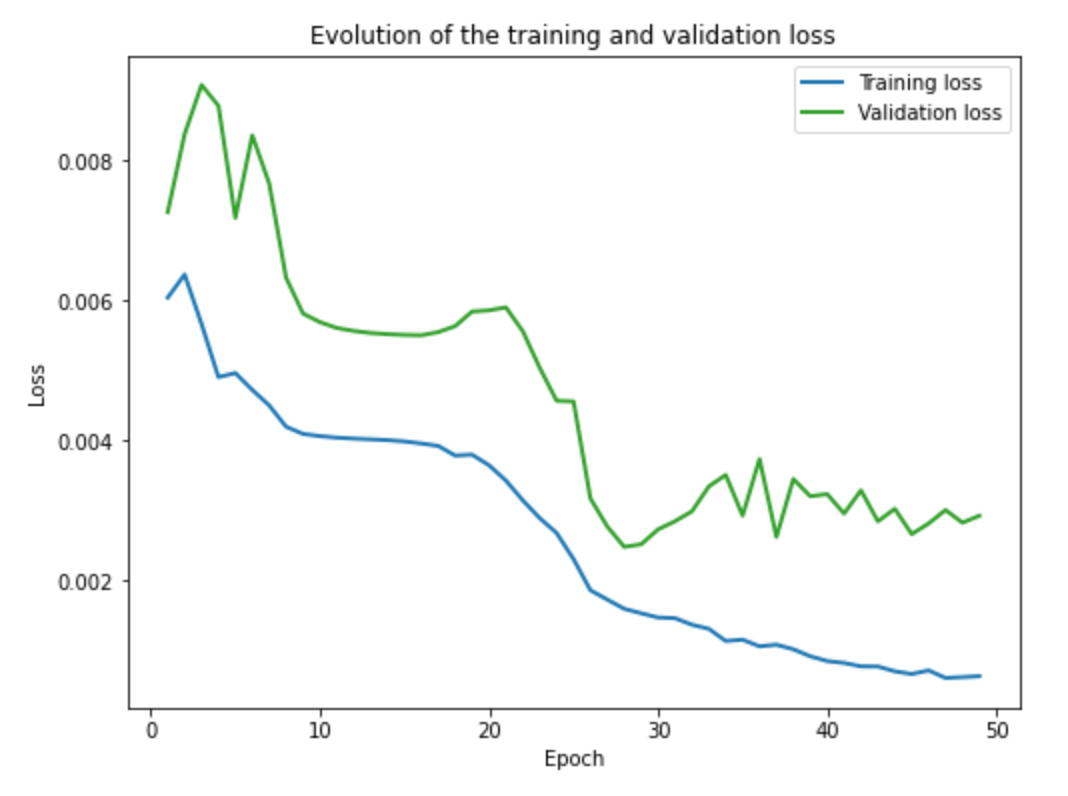
Training and Validation Errors
Prediction Results

Prediction of the Neural Network on a subset of the Training DataSet

Prediction of the Neural Network on a subset of the Validation DataSet
Where and why does it fail?
As we can see, the CNN mostly fails to correctly detect the nose tip of faces that are not straight, meaning that they are looking to the right or left. In contrast, the CNN is able to correctly detect the nose top of most faces that are looking straight to the camera. I think the CNN fails for faces that are not looking directly straight because there are not enought training example with non straight looking faces and I think the brightness and contrast is different for non straing looking faces.
Part 2: Full Facial Keypoints Detection
In this part I worked on detecting 58 facial keypoints of faces in the IMM Face Database. For this I first divided the dataset into training and validation sets. The training set had 192 images, while the validation set had 48 images. Then I defined a dataLoader that converted the images to grayscale and normalized them in the range -0.5 to 0.5. After that, I rescaled the images to be 240x180. Then, I defined a CNN to predict the location of the 58 facial keypoints. The architecture of the CNN was as follows:
- nn.Conv2d(1, 32, 3, bias = False) followed by a ReLu and a max pool layer with kernel size 2.
- nn.Conv2d(32, 26, 5)followed by a ReLu and a max pool layer with kernel size 2.
- nn.Conv2d(26, 32, 3, bias = False)followed by a ReLu.
- nn.Conv2d(32, 20, 3) followed by a ReLu.
- nn.Conv2d(20, 32, 5, bias = False) followed by a ReLu and a max pool layer with kernel size 2.
- nn.Conv2d(32, 12, 3, bias = False) followed by a ReLu and a max pool layer with kernel size 2.
- nn.Linear(924, 200) followed by a ReLu
- nn.Linear(200, 116, bias = False)
For training I used Adam as the optimizer and MSELoss as the loss function. I also used 0.001 as the learning rate and ran for 50 epochs. Similarly, for data augmentation, I performed 80 rotations and shifts of images selected randomly and added this to the training and validation sets. I used 2/3 of the generated shifts and rotations as training and the remaining 1/3 as validation. Each rotation angle was selected randomly in the range [-15. 15] degrees and each shift was selected randomly in the range [-50, 50] pixels of the original 640x480 image. Half of the shifts were horizontal and the other half were vertical. Please see images below for a visualization.
Sampled Images from Data Loader with Ground-Truth Points

Training Augmented Samples

Training Validation Samples
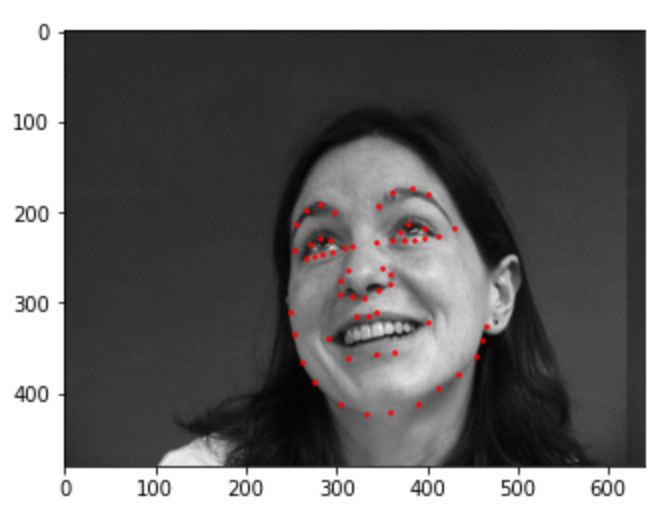
Horizontally shifted sample

Rotated sample
Training and validation loss across iterations
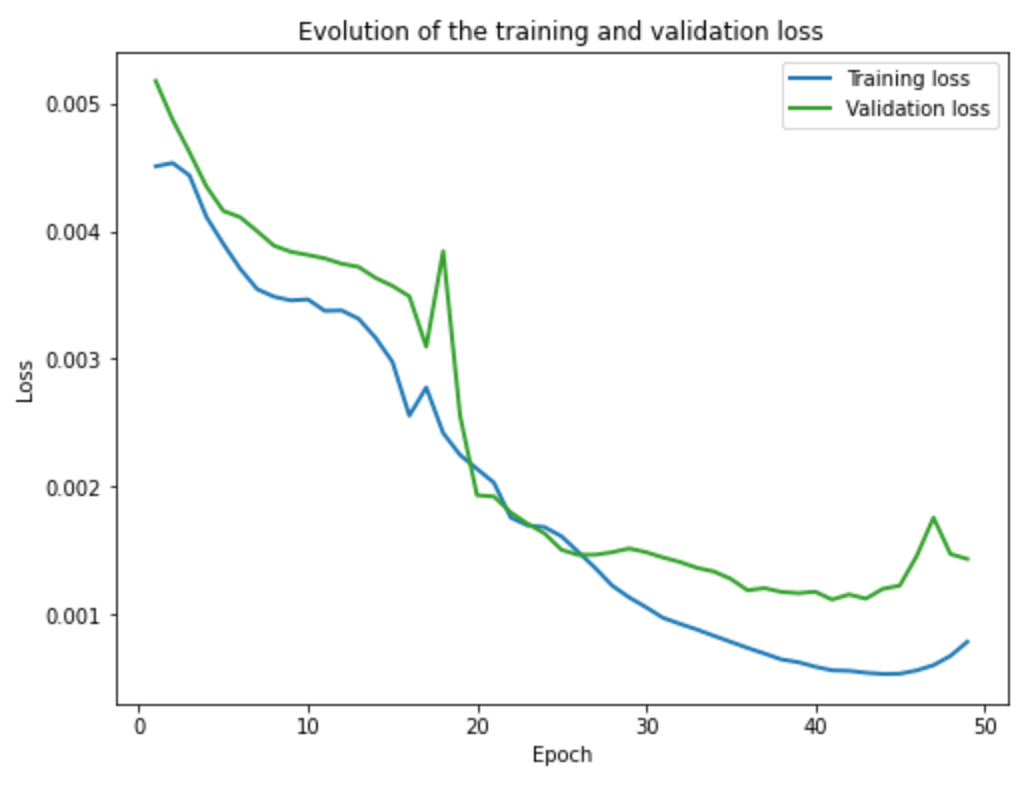
Training and Validation Errors

Prediction of the Neural Network on a subset of the Training DataSet

Prediction of the Neural Network on a subset of the Validation DataSet
Where and why does it fail?
As we can see, the CNN mostly fails to correctly detect the facial keypoints of faces that are not straight, meaning that they are looking to the right or left. In contrast, the CNN is able to correctly detect the facial keypoints of faces that are looking straight to the camera. I think the CNN fails for faces that are not looking directly straight because there are not enought training example with non straight looking faces and I think the brightness and contrast is different for non straing looking faces. This is the same reason as the nose tip detection failures.
Learned Filters
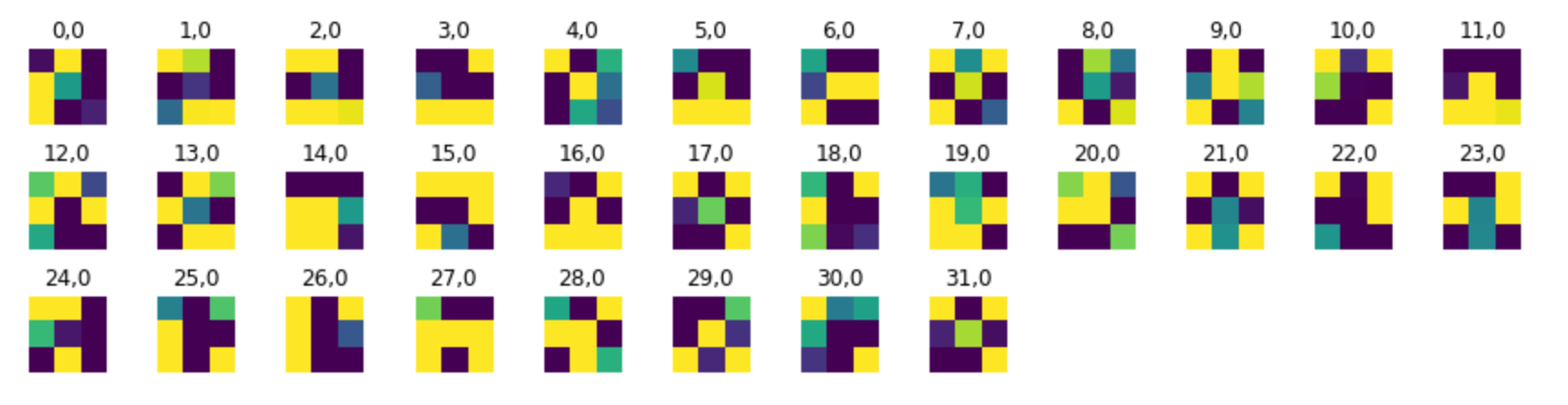
Convolutional Filters Layer 1

Convolutional Filters Layer 2

Convolutional Filters Layer 3

Convolutional Filters Layer 4

Convolutional Filters Layer 5

Convolutional Filters Layer 6
Part 3: Train With Larger Dataset
In this part, I worked on training a CNN to detect 68 facial keypoints of a dataset of 6666 images. As you can see in the image below and in the code, I was able to get all the transformations (cropping, rescaling) and data augmentation working. I was also able to succesfully modify the RestNet Architecture. Below you can see the results:
RestNet18 Architecture: I used the default architecture, except, I changed the first convultional layer and last fully connected layer as detailed below:
- First Convolutional Layer: nn.Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
- Last Fully Connected Layer: nn.Linear(in_features=512, out_features=136, bias=True)
- Training Hyperparameters: learning rate was 0.001 and the number of epochs was 10. I used a batch size of 4 and I used Adam as the optimizer.
Sampled Images from Data Loader with Ground-Truth Points
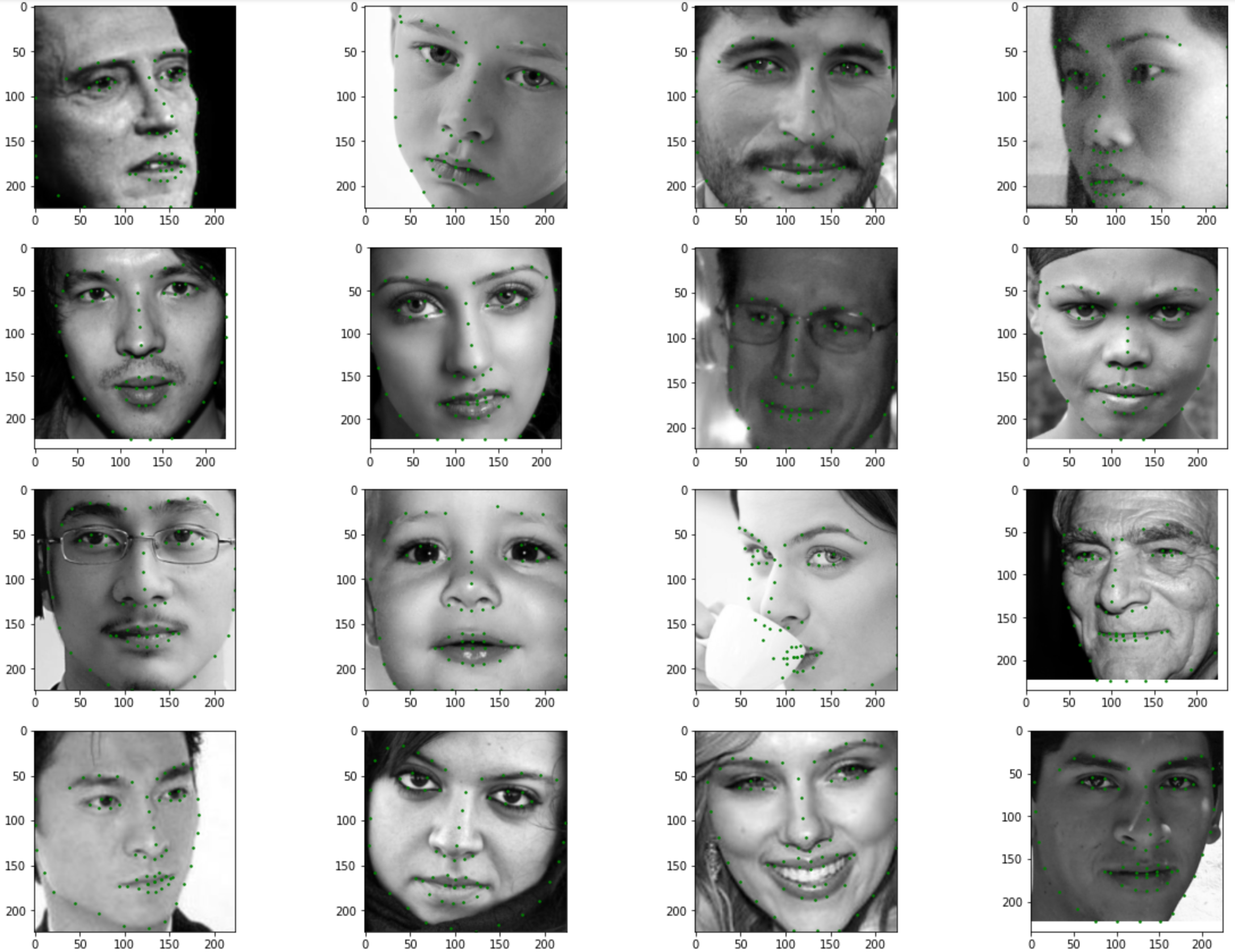
Training Samples (Transformed: grayscale, cropped, and rescaled)
Training and validation loss across iterations
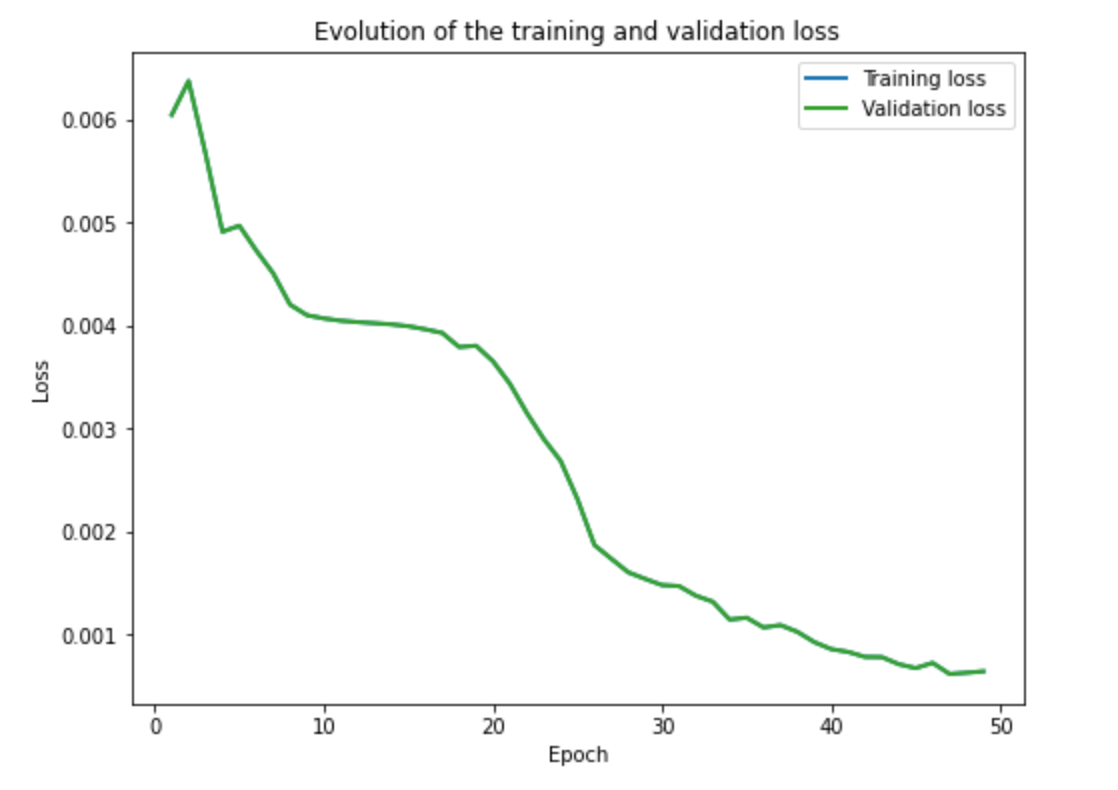
Training Errors across iterations. I forgot to divide the dataset into training and validation, thus what you see here is the training error (entire dataset of 6666 images).
Although I was fully able to train the network (please look at the code) I could not test it on the test dataset due to time contraints. I also was not able to submit my prediction to Kaggle, thus, I am not reporting a score here.