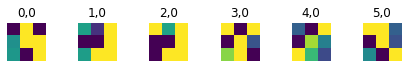This project involves building a neural network to be able to identify nose points or facial features on images. The third part of the project deals with a larger dataset to train on in Google Colab.
Part 1: Nose Tip Detection
Parts 1 and 2 use the IMM Face Database, which is split into 32 people for the training dataset and 8 people for the validation dataset. Each person has 5 images. The neural net consists of 3 layers, with the input being only 1 channel (since the image inputs are converted to grayscale) and the output 2 (x/y coordinates of the nose tip). A ReLU and MaxPool were used after every convolution in each layer. Two fully connected layers were applied after the three layers. A learning rate of .001 was used.
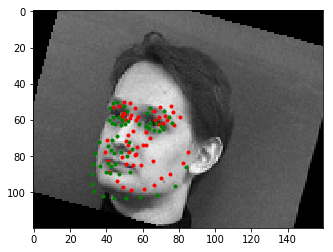
A sampled image with groundtruth nose keypoint from the dataloader
Batch size of 5
Here are some of the results of the model. Red will be used for prediction points and green for the groundtruth.
Decent result (forward facing)Good result (face turned)
The following images are a bit worse, and that is possiby due to the fact that faces turned away from the camera are harder to train on. The right image has a realtively different lighting, which might have been an outlier while training.
Bad resultBad result
Part 2: Full Facial Keypoints Detection
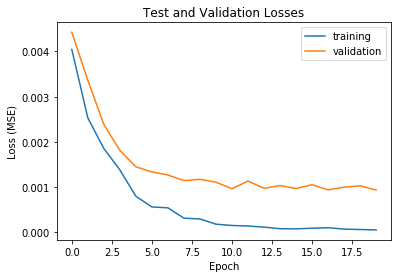
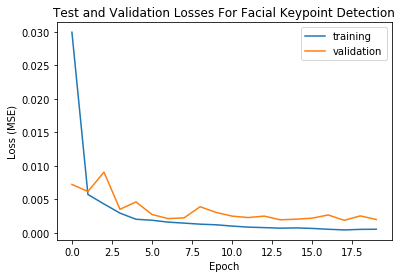
This part was very similar to Part 1, with the exceptions of changes in the dataloader to accommodate for all 58 facial keypoints. Since the dataset is fairly small, augmentation was done (shifting on the x-axis and rotating in a 30 degree range) to enlarge the training set. The neural net was also modified, with two extra layers and a MaxPool on only 2 of the 5 layers. A batch size of 15 was used for the training dataloader. The model was trained overr 20 epochs.
A sampled image with groundtruth keypoints from the dataloaderThe network architecture
Batch size of 12
Here are some fairly good results
Decent result (forward facing)Decent result (face turned)
The following images are a bit worse. Again, the worst performing ones are more likely to be sideway-facing faces. The left image is aso extremely tilted, which the model may not be as familiar with.
Bad resultBad result
Here are the first two layers visualized
Layer 0Layer 1
Part 3: Train With Larger Dataset
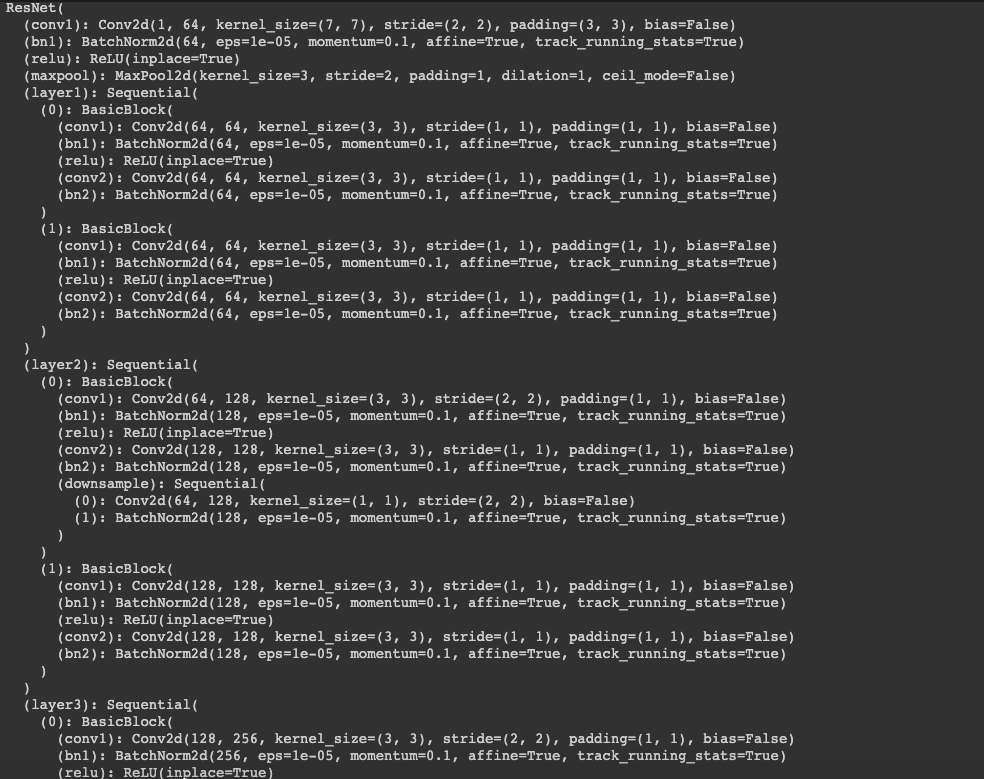
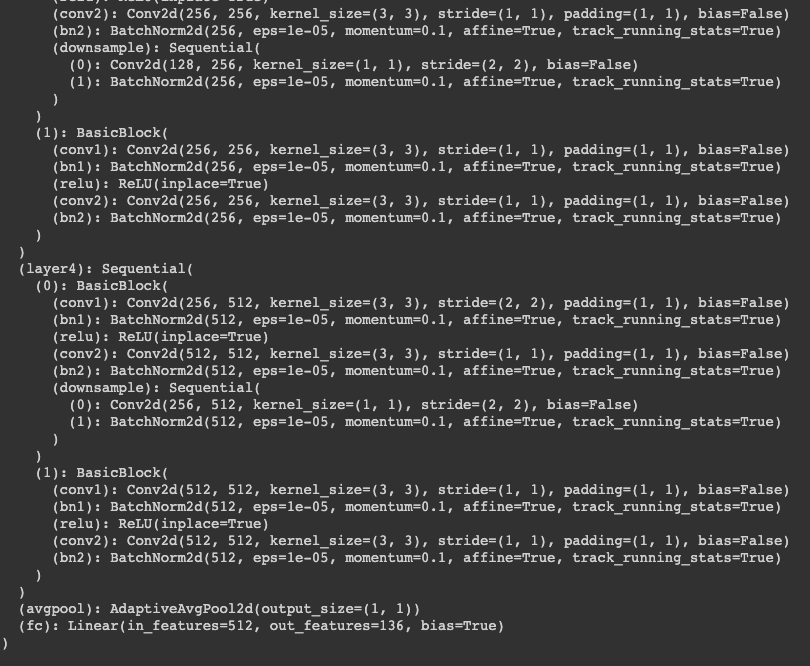
Here we use a model called ResNet18 and train it on a much larger dataset (6666 images) with augmentation as well. An XML parser was used to retrieve the images, landmarks, and boundary boxes that were used to crop only the faces of the images. Since some of the facial points were located outside of the crop zone, I expanded the boundaries accordingly to include all points, although augmentation may have caused some others to go out of bounds. Augmentation using shifting and rotation were applied to the dataset, although the degree of rotation was set between -5 and 5 this time.
Here is the network architecture.
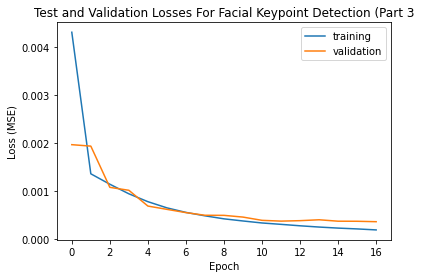
Training took about 2 hrs for my model using Google Colab.
Batch size of 5 with learning rate of .001
Here are some of the predictions on images from both the training and validation datasets.
Training datasetTraining datasetValidation datasetValidation datasetValidation dataset
My Collection
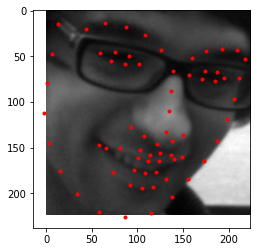
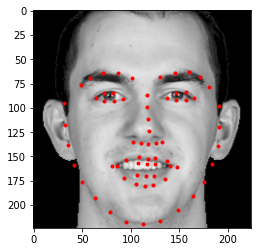
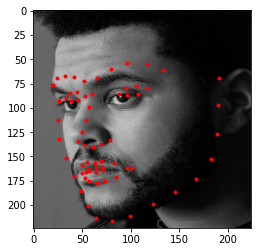
I've chosen three special images to test my model on.
NBA 4x MVP 4x FMVP 4x Champion Lebron JamesThe GOAT Alex CarusoSinger The Weeknd
My model seems to work pretty well, esepcially on Alex Caruso's. Lebron's eyebrows are a bit off, and that could be because of the weird shape that the image takes in order to fit 224x224. The Weeknd's face performed the worst, likely due to the angle his face is in.
Overall
Although this project took a while, it was really rewarding to see the performance of my model on different faces! I enjoyed getting to understand the structure of a neural network!