CS 194 Project 4: Facial Keypoint Detection with Neural Networks
Sophia Yan
Overview
This project has three main parts: auto-detection of nose tips, auto-detection of full facial points, and training on larger dataset of human portrait. Convolutional Neural Network (CNN) is a useful tool for learning key features from input images automatically. This project uses Pytorch.
Part 1: Nose Tip Detection
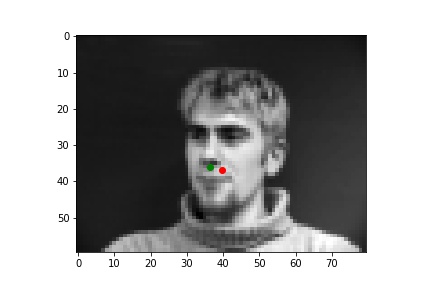
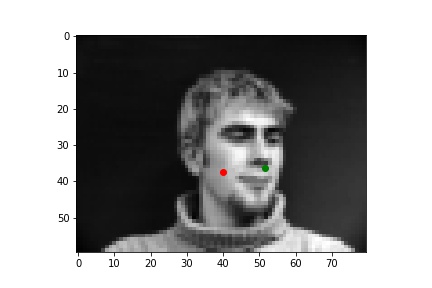
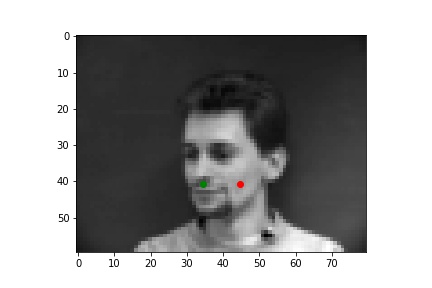
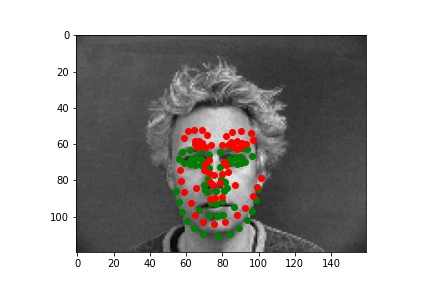
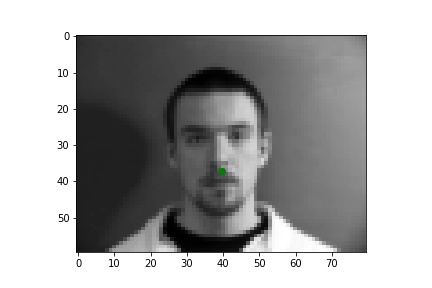
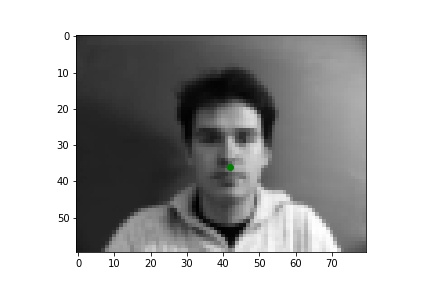
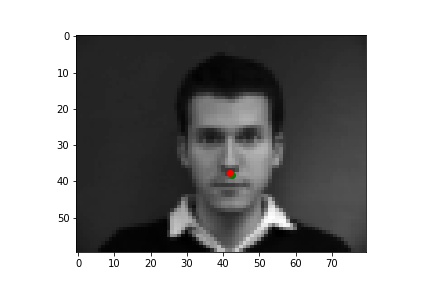
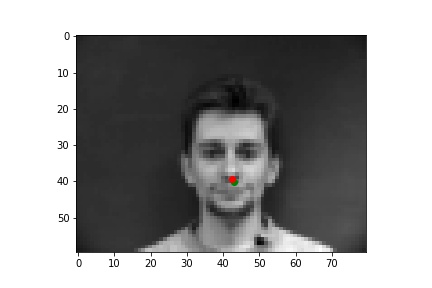
Below are three of each of my sample ground truth pictures, successful predictions, and failed predictions. I customized a dataset to read and store images and corresponding nose tips and landmarks. The whole dataset is slip into 80% of training and 20% of testing (192:48). Under the instruction of spec, I resize the data to 80x60, convert it to greyscale, and normalized it. I used two separate data loaders for train set and test set, both has a batch size of 1.
The ground-truths are in green and my predictions are in red, similarly hereinafter. The architecture of my network and the loss plot are also shown below.
Explanation of failed cases:
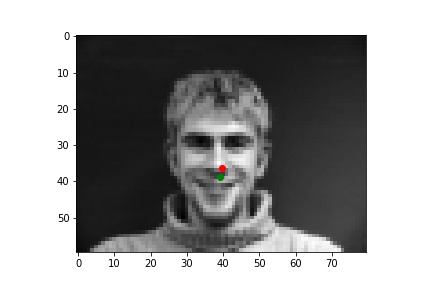
The model performs reasonably well for many of the images, However, some predictions are not doing well. One reason is that the majority of failure cases are side faces. However, most of the images in training set are front face. The second reason is that there is some special elements in some pictures, such as larger contrast to the background or raising hands. We need more training data of side faces and also data augmentation (see part 2) to improve the performance of the model.
| Ground Truth 1 |
Ground Truth 2 |
Ground Truth 3 |
 |
 |
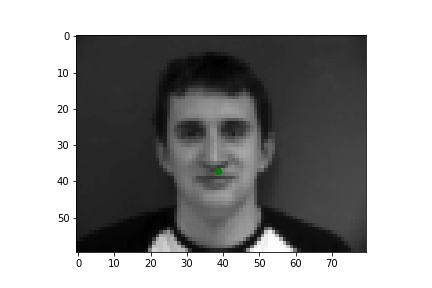 |
| Successful 1 |
Successful 2 |
Successful 3 |
 |
 |
 |
Bolow is my network architecture for nose tip detection and the loss plot for this part. I trained the model for 20 epochs with learning rate = 0.001.
| CNN |
Loss Plot (Blue: Training / Orange: Validation) |
 |
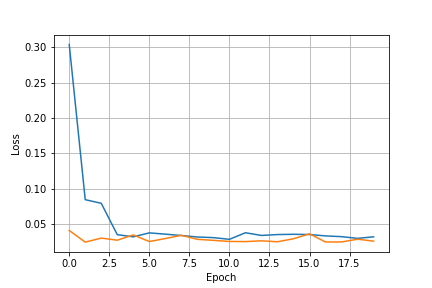 |
Part 2: Full Facial Keypoints Detection
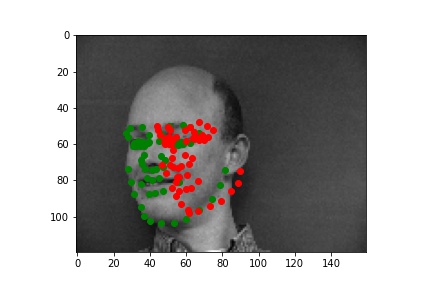
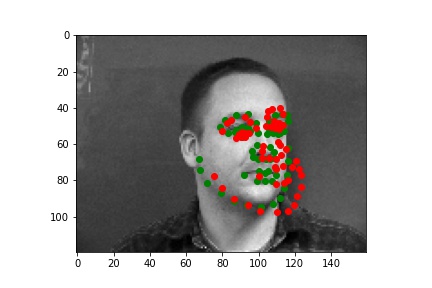
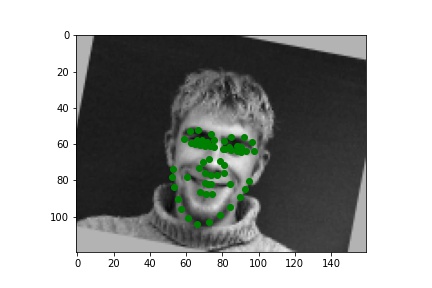
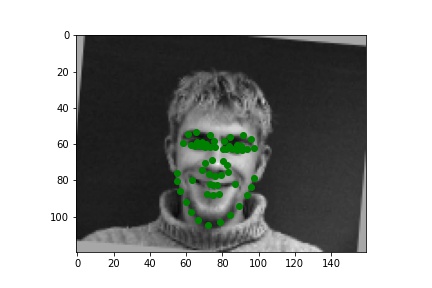
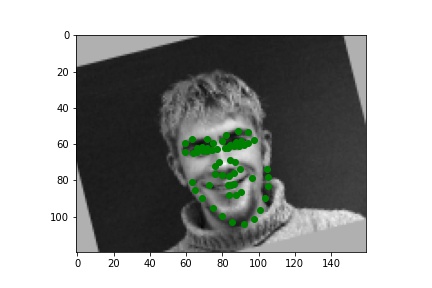
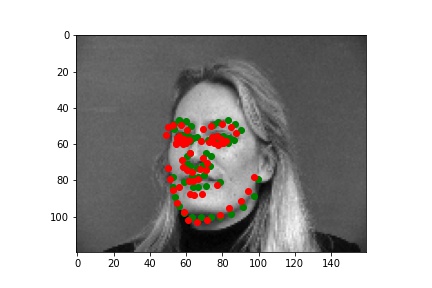
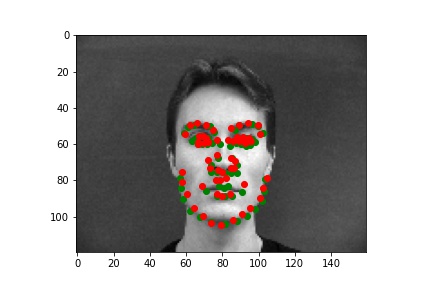
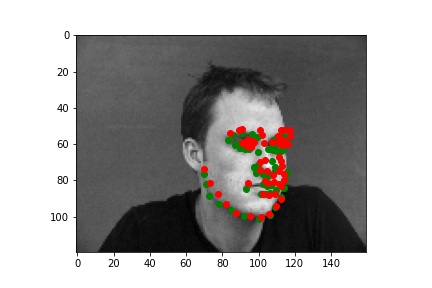
Below are three ground truth pictures and several samples, success or failure, from evaluation on a batch from the validation set. As before, the ground truth is green and my prediction is red. I also resize, normalize, and grayscale the pictures. I use a random rotation from -15 to 15 as data augmentation for this part.
Explanation of failed cases:
As we can see, with data augmentation, the model performs well for many of the images. However, some predictions are not doing well. There are several reasons to explain the inaccuracy, and I choose several pictures to illustrate them. For the first case, the person is way off the middle of the picture, which is the majority of training set does. For the second case, The contrast between the person and the background is much lower than those of most pictures. For the third case, there is some shadow on the background, and the shadow can distract the model during the prediction.
| Ground Truth 1 (w/o data augmentation) |
Ground Truth 2 (w/o data augmentation) |
Ground Truth 3 (w/o data augmentation) |
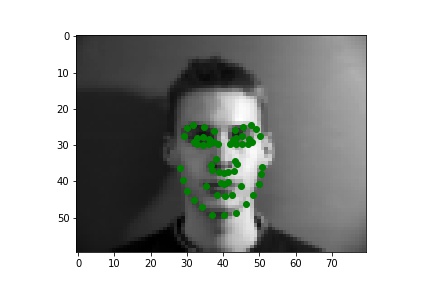 |
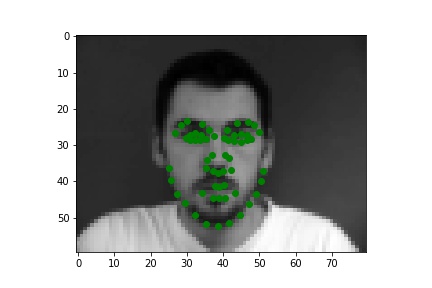 |
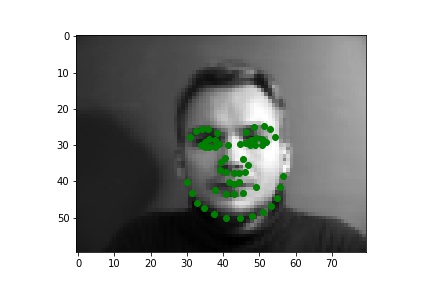 |
| Ground Truth 1 (Aug: Rotated) |
Ground Truth 2 (Aug: Rotated) |
Ground Truth 3 (Aug: Rotated) |
 |
 |
 |
| Successful 1 |
Successful 2 |
Successful 3 |
 |
 |
 |
Bolow is my network architecture for full facial landmarks detection and the loss plot for this part. I trained the model for 25 epochs with learning rate = 0.001. The two losses are sums of training loss / validation loss of each eopch.
| CNN |
Loss Plot (Blue: Training / Orange: Validation) |
 |
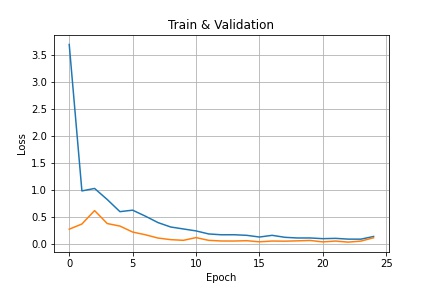 |
I visualize the filters learned for layer 0, 1, and 2. Since the entire set is too large, I display part of the set due to space limit. The dark grids represent detected features from the inputs.
| Filter(Layer 0) |
 |
| Filter(Layer 1) |
Filter(Layer 2, slightly compressed for space) |
 |
 |
Part 3: Train With Larger Dataset
I adjust the iBUG 300W dataset by cropping it, resize all images to 224x224, and adopt data augmentation from part 2. I cropped the images by the adjusted bounding box. For this part, I used the ResNet18 implementation provided in PyTorch and keep most of the implementation of it. I train my model with lr = 0.001, batch_size = 32, and trained for 24 epochs.
Explanation of imperfect cases:
As we can see, with data augmentation and a larger dataset, the model performs well for many of the images. However, some predictions are not doing perfectly. In my selection, the "my choice 2" fits the poorest among the three, and I think it is because the character has a thinner and more angular face than most of people. Just like in the previous part, inaccuracy of prediction normally comes from some "specialties" that single images / charater has while most people do not have.
| Pred 1 from dataset |
Pred 2 from dataset |
Pred 3 from dataset |
 |
 |
 |
| My choice 1 |
My choice 2 |
My choice 3 |
 |
 |
 |
Bolow is the kaggle score and loss plot and my network architecture for Part 3. I trained the model using modified ResNet for 24 epochs with learning rate = 0.001. Please see the details of my network below. The two losses are sums of training loss / validation loss of each eopch.
| Kaggle |
 |
| Loss Plot (Blue: Training / Orange: Validation) |
 |
| CNN layer1 |
CNN layer2 |
 |
 |
| CNN layer3 |
CNN layer4 |
 |
 |