
|

|

|

|
In this project, we performed facial keypoint detection using neural networks. We worked with the pytorch library and used techniques like data augmentation.
In this part of the project, we had to detect the nose tip using the IMM Face Database. First, I converted all images to grayscale, normalized to float values between -0.5 to 0.5, and then resized the image. I also slightly rescaled the points such as the nose tip point (which is actually below the nose) accurately points to the nose tip.
Below you can see some sample images from the Dataloader!
|
|
|
|
|
|
I designed the following neural network.
Net(
(conv1): Conv2d(1, 12, kernel_size=(5, 5), stride=(1, 1)))
(conv2): Conv2d(12, 16, kernel_size=(5, 5), stride=(1, 1))
(conv3): Conv2d(16, 20, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=1200, out_features=800, bias=True)
(fc2): Linear(in_features=800, out_features=400, bias=True)
(fc3): Linear(in_features=400, out_features=2, bias=True)
Here is the training (blue) and validation (orange) loss per epoch (where validation loss was calculated before training loss)
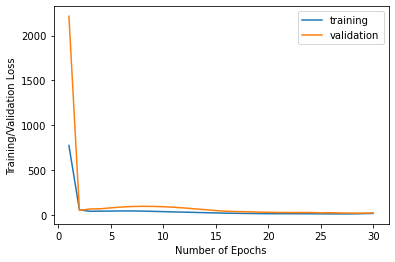
|
After training the model, here are a couple of successes and failures. The blue dot is the ground truth and the red dot is the predicted label.

|

|

|

|

|
After an initial glimpse, it seems that the model fails when the nose tip is far away from the center of the image. This might be due to the extremely small dataset and a very simple deep learning model.
For this part, we needed to predict all 58 facial keypoints. We use the same dataset as before but this time all augment it. After converting the image to grayscale and resizing it, I randomly change the brightness and contrast of the image, randomly rotate the image with a probability of 0.25 and randomly horizontally flip the image with a probability of 0.25.
Here are some sample images from the Dataloader

|

|

|

|
Here is the neural network I designed in detail. I used a learning rate of 0.0001 and Adam optimizer. I trained the model for 40 epochs.
Net(
(conv1): Conv2d(1, 16, kernel_size=(7, 7), stride=(1, 1))
)
(conv2): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1))
(conv3): Conv2d(32, 20, kernel_size=(3, 3), stride=(1, 1))
(conv4): Conv2d(20, 12, kernel_size=(7, 7), stride=(1, 1))
(conv5): Conv2d(12, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=3840, out_features=2000, bias=True)
(fc2): Linear(in_features=2000, out_features=300, bias=True)
(fc3): Linear(in_features=300, out_features=116, bias=True)
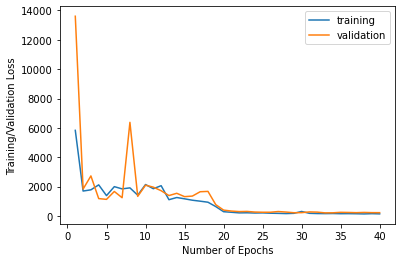
|
After training the model, here are a couple of successes and failures.

|

|

|

|
Here, in the two failure cases it seems like the model is overfitting to a very narrow face. This can be fixed be having more data augmentation and a better trained model.
Finally, below I have displayed the all learned filters for the first and fifth (last) layer of the network.
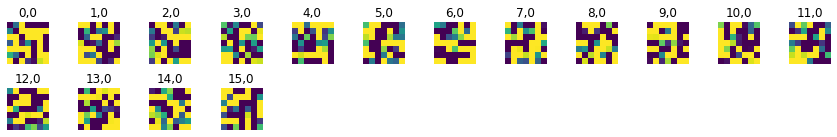
|

|
In this part, we use a very large dataset and a predefined model like the ResNet 18 to predict facial points. Thanks to Google Colab's GPU I was able to train these model very efficiently. I submitted my final results to kaggle under the username Yash Swarup Agarwal and got a MAE of 18.09785.
Below, once again, is the detailed architecure of the ResNet18 model used with slight modification to the first and last layer to suite the model to this specific problem. The learning rate was 0.001 and the optimizer used is Adam.
ResNet(
(conv1): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=136, bias=True)
)
Additionally, here are the associated training and validation losses per epoch:
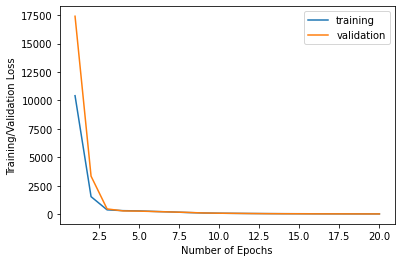
|
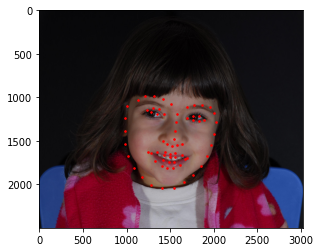
With the help of Google Colab's GPU, the model was able to achieve some decent values of loss, and produce the following predictions on the test set.

|
|

|
|

|
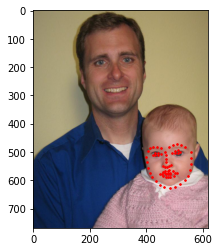
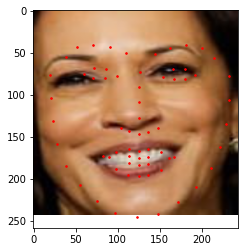
Here are some images from my collection.
|

|

|

|
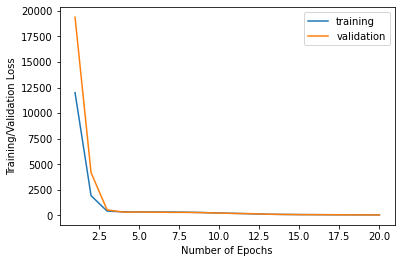
I implemented the Anti-aliased max pool from Richard Zhang's work by using model = antialiased_cnns.resnet18() instead of model = models.resnet18() . I did not see a huge difference in performance accuracy but this might be because I only trained for a few epochs. I used a learning rate of 0.001 and the optimizer used was Adam.
Here is the model in detail.
ResNet(
(conv1): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): Sequential(
(0): MaxPool2d(kernel_size=2, stride=1, padding=0, dilation=1, ceil_mode=False)
(1): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
))
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=136, bias=True)
)
Here is the training and validation loss per epoch.
|