Good Result 1
Good Result 2
Bad Result 1
Bad Result 1
This project will explore how to use neural networks to automatically detect facial keypoint to avoid manual clickings when dealing with face pictures. In the project, I used Pytorch as the deep learning framework and mainly used Conventional Neural Network (CNN) as my deep learning model.
In this part, I used the IMM Face Database for training an initial model for nose tip detection. The following three parts illustrate my training processing
For this part of question, I defined a subclass of torch.utils.data.Dataset, where I defined my own __getitem__ method for accessing the dataset, and is able to customize the transformation operations on the dataset. The dataset contains two kinds of items: images and landmarks. For the purpose of this part, I resized all images to 60 * 80 and changed their landmarks accordingly. Thereafter, all images are converted into grayscale and normalized as float values in range -0.5 to 0.5. Finally, both the image array and the landmark array are changed into Tensors for future processing. The followings are a few images randomly picked along with their nose keypoints.

In this part, I defined my own CNN model with 4 convolutional layers with different in/out channel but all with 3*3 kernel size. All convolutional layers are followed by a maxpool followed by a ReLU. I use maxpool before ReLU because after many experiments, I found that using maxpool before ReLU will make the experiment to converge faster and being more robust. I chose kernel size 3 because it does not have a lot penalty on time complexity but give a much precise prediction than a larger kernel size. Finally, I connect the convolutional layers with two Full Connect layers for extracting features.
For the loss function, I used mean squared error loss (torch.nn.MSELoss) as my indicator, and used Adam optimizer to update my network and minimize the loss. I also splitted all data into train set and validation set in order to prevent my model from overfitting the train data. My training process is shown as follows:
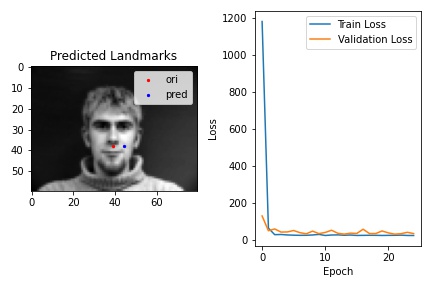
As we can see in the plot below,the train loss keeps decreasing while the validation loss starts with decreasing and ends up with alternatively increase and decrease. This may be caused by the case that our learning rate and train batch size is not well defined that our model keeps pass the true optimal.
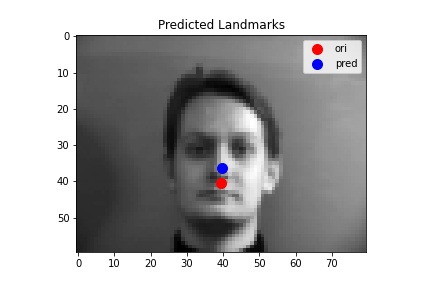
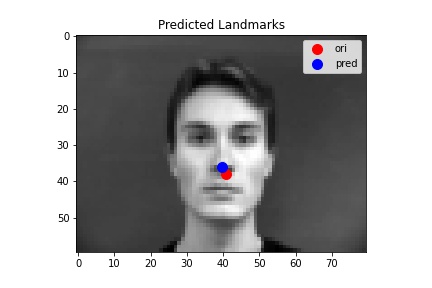
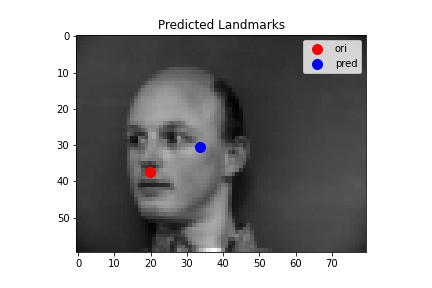
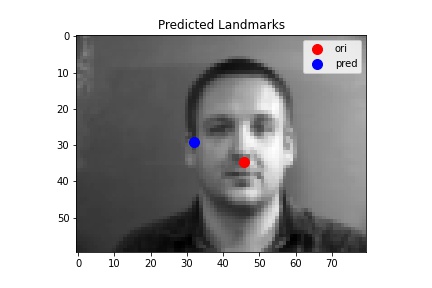
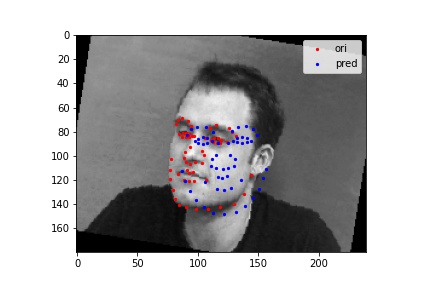
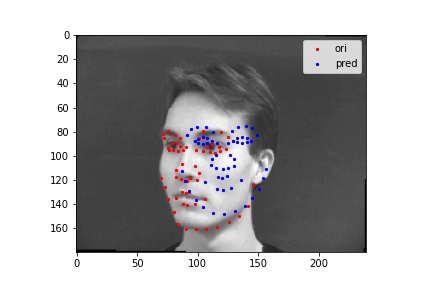
The following images shows some prediction results from the validation dataset after 25 epoches of training. For the first two images, the network detects the nose fairly correctly since there are little noise and the face is at a normal position. While for the last two images, the network detects incorrectly.
For the third one, the network detects incorrectly because the person's face direction is far from straight. Since our original dataset's training set is not large enough to cover all cases, such "edge cases" cannot be correctly detected by the network. A potential solution to this problem is to use data augmentation to enlarge the training dataset as we will do for the next part.
For the fourth one, the network detects the nose point wrong even though the man is facing perfectly straight-forward. I think this may be caused by the fact that our training set is not large enough. Also, it maybe the case that this man's nose is not as obvious as the others' may be (that is to say, maybe there are parts whose feature are very close to the feature of a nose) and therefore the network got confused on deciding which part of the face is the true nose.
In this part, I continue to use the IMM Face Database for training and validatation and tried to build a model for detecting full face keypoints (58 of them based on IMM Face Databse). The following three parts illustrate my training processing:
For this part of question, I also defined a subclass of torch.utils.data.Dataset, which is basically the same as the one in the previous part. On the other hand, as we mentioned above, one problem with the IMM Face Database is that the dataset is to small to converge and cover all cases. This problem will be extremely hurtful when we trying to predict all 58 keypoints on a face with a more deep CNN structure. Therefore, in order to solve this problem, I implemented a data augmentation method for accessing the database and enlarged the train data by a multiple that can be decided by the user. For my training, I enlarged my database by 10 times.
The data augmentation contains the following elements. All tranformations are applied to both the images and their landmarks accordingly:

In this part, the model, loss function, and optimizer are all very similar to the one in the previous part. The only difference is this part's model have two more convolutional layers. The training process is shows as follows:
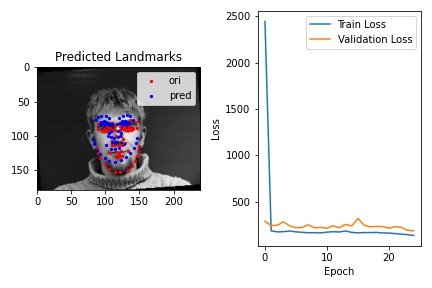
As we can see in the plot below, both the train loss and the validation loss keeps decreasing over time until the end of the 25th epoch. This may imply that a longer training can result in less loss in both train and validation set.
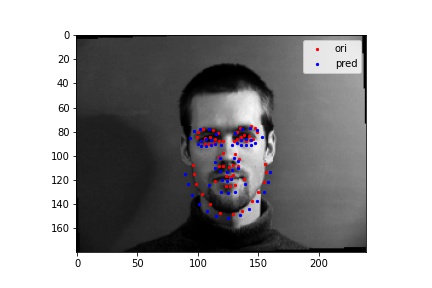
The following images shows some prediction results from the validation dataset after 25 epoches of training. For the first two images, the network detects the nose fairly correctly. Also, we can see for the second image, even though it is not facing forward and is rotated by a large angle, the model is still able to correctly detect the keypoints. This shows that the data augmentation we did is meaningful.
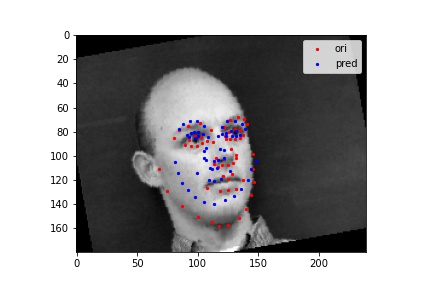
For the other two, the model failed to correctly predict and we notice that the original picture all face to left and the predicted value all stays in the center. I think the model fails in these cases because it is trying to account for both pictures facing to left and pictures facing to right. Therefore, for some extreme pictures, the best thing our model can do is to predict the middle value in order to minimize the overall loss.
The learned filters of the first four convolutional layers are as follows




In this part, I use the large wild IMM Face Database for training and validatation and tried to build a model for detecting full face keypoints (68 of them based on this Database). The following three parts illustrate my training processing:
For this part of question, I also defined a subclass of torch.utils.data.Dataset, which is basically the same as the one in the previous part. For this part, since the original training set is already big enough, the only randomness I put as data augmentation is to change color by randomly pick a brightness/contrast factor from 0.5 to 1.5 and a hue factor from -0.5 to 0.5.

In this part, I used the pre-trained ResNet18 as a base model for my CNN structure, and changed the final FC layer's output channel number to be the same as my landmark number (2 * 68). I kept all other parameter of ResNet18 unchanged.
As we can see in the plot above, both the train loss and the validation loss keeps decreasing over time until the end of the 25th epoch. This may imply that a longer training can result in less loss in both train and validation set.
For test images, I used the provided test images and the first 8 samples are shown as follows:

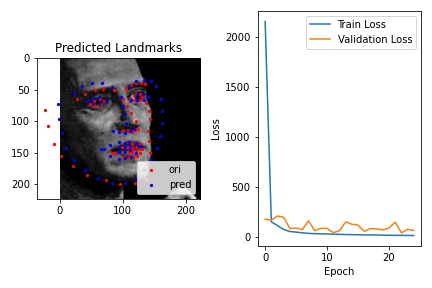
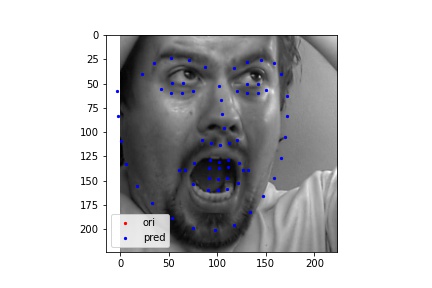
The following images shows some prediction results from the test dataset after 25 epoches of training. I randomly chose many different inputs and all of their prediction result looks fairly good to me. The cases I show below include many edge cases I could think of, such as weird face direction, weird mouth shape, open mouth, flattened face, and etc. My model succeeds in detecting face points in all of them, so I believe I was not able to find a failure case for this model.
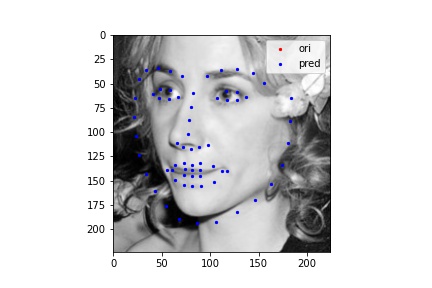
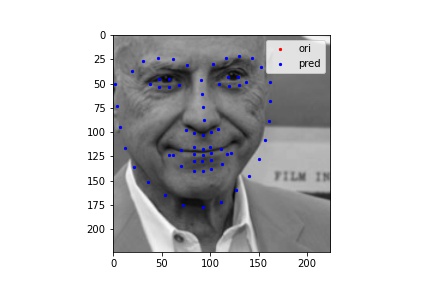
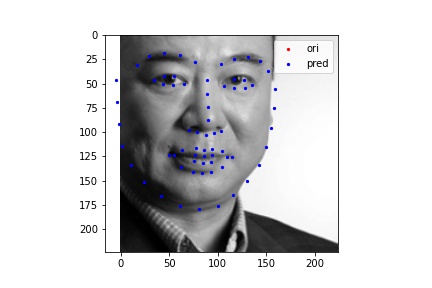
However, one challenge I faced for detecting keypoints for Kaggle submission was recovering the true abosolute coordinates after prediction. I believe the recovery process brought some more loss into my model and my final Kaggle loss is around 12.
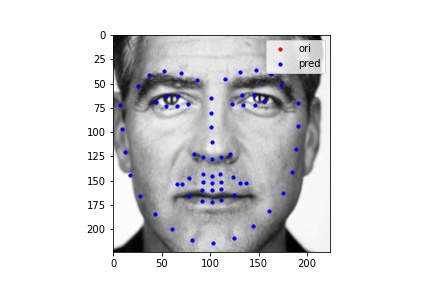
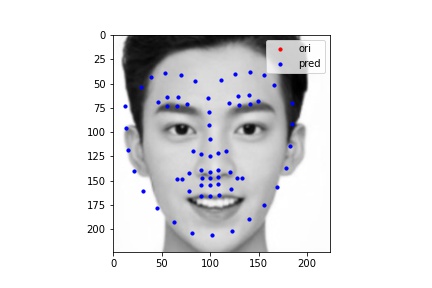
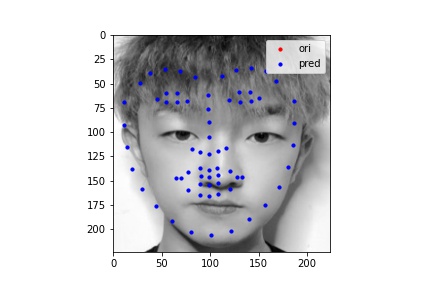
The following images shows some prediction results from images I chose from my collection. I will also use these images for presenting fully automatic face morphing in the Bells & Whistles.
As we can see the first two images are well detected, while the third one is a failure case. I purposely did this in order to test the limitation of my current model. It turns out that the cropping process is very important in order to correctly detect face keypoints. I cropped the George's picture following the same routine as the IMM dataset's boxes; on the other hand, I cropped my face randomly and left a lot of hairs in there. As a result, we can see the key point detection's ability is largely affected.
Using the model from part 3 above, I am able to integrate this face keypoint detector into my project3's code and avoiding manually annotate the facial key points. Here I generated a sequence of automatic morphing between faces with the morphing handler from project 3 and face detector from this project.
Since the way I trained my model is already using 3-layer gray scale picture, so I did not need to have any modifications in order to detect the key points on the colored pictures. In order to solve the problem mentioned above, before I do the automatic keypoint detection, I first did a ratio crop of the picture so that the noisy background is cropped a bit. Thereafter, I run my trained model to get all 68 points and run the morphing algorithm from project 3. Since the keypoint detector are only trained to detect face not the background, my face morphing only contains the part that contains the face. My result is shown as follows:
In order to contain the background, I edited my code that after obtaining the keypoints detected , I appended the four corners to the keypoint list in order: (0, 0), (w-1, 0), (0, h-1), (w-1, h-1), where w and h is the width and height of the image respectively. In order to overcome the "index out of range" issues when doing the triangulation, I put a little shift in these four points, and make them: (1, 1), (w-2, 0), (1, h-2), (w-2, h-2). My final result is shown as follows:
Following the work from Richard Zhang, I utilize the function of Anti-aliased max pool in my face keypoints detection process. I modified the CNN structure of my Part 2's network and as suggested by Richard, I replaced the Max Pool layers with the MaxBlurPool layer in antialiased_cnns. I used the same optimizer and augmented dataset as in Part 2, and I get the resulting train process. We can compare with the one from part 2.
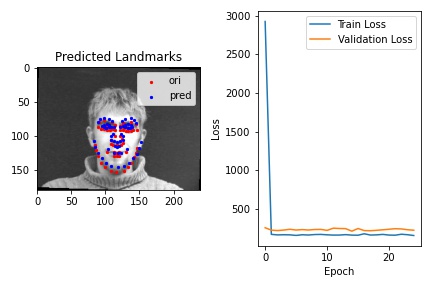
I also closely looked into the difference of the loss array of both model overtime, and I made the following discoveries:
Overall, I believe using Anti-aliased Max Pool is a good idea when we have a large enough training set that need the network to proceed faster and can prevent the model from overfitting. Therefore, in this question, since we used the augmented data from part 2, which is large and random, using Anti-aliased Max Pool is a good idea and indeed gives us a better prediction result as we can see above.