CS194-26 Project 4: Facial Keypoint Detection with Neural Networks
Michael Park - Fall 2020
Objective
The main objective of this project is to train a neural network to automatically detect facial keypoints of portrait images. For the previous project (Project 3), I had to manually select points that determine facial features before performing image processing. To automate the process, I designed and trained a Convolutional Neural Network (CNN) using Pytorch, a Python machine learning library.
Nose Tip Detection
Before creating large models that predict all facial keypoints, I started out with a smaller-scale one to
detect nose-tip keypoints. For this part, I used the IMM dataset, consisted of 240 images of 40 persons. I
first created a custom dataset class that stores (image, keypoints) pairs. I created and applied
transformation functions that rescaled images into (60px, 80px) and selected only the nose tip
keypoints. Then, I loaded the pairs into torch.nn.data.Dataloader.
Below are some of the results of loading the data:

|

|

|

|
Then, before using the dataloader, I split the dataset into training and validation sets. I set the validation size to 48 images out of 240 total training images of the IMM dataset. Then, I created a neural network consisted of three convolutional layers and two fully connected layers followed by ReLU non-linearity filters and max-pooling. The model was trained over 20 epochs and the Adam optimizer with the learning rate of 0.003.
Below are the training and validation losses over epochs:
Training and Validation Losses
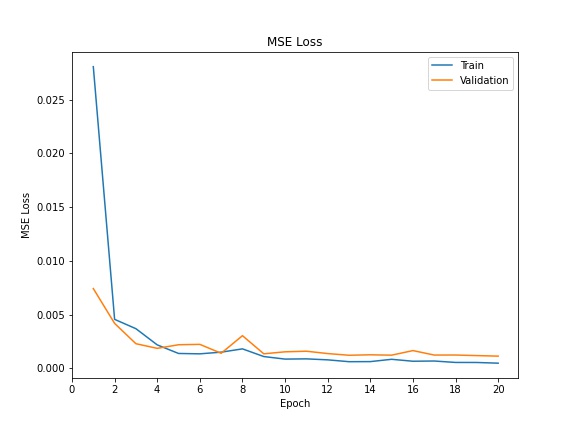
|
Below are the results. While most of them hit the ballpark, the neural net was unable to correctly predict some images. This is because most images have faces with closed mouths and forward-facing posture. This may be mitigated by adding variation to the dataset, possibly by using augmentation.

|

|

|

|

|

|

|

|
Full Face Keypoints Detection
For this task, I trained a neural network to predict all 58 keypoints as determined in the ASF files of the
IMM dataset. I followed the same procedure as for the previous task, but I rescaled the images to be
(120px, 160px) for more precise detection. In addition, I implemented data augmentations for this
part: rotation of varying degrees and translation of images. I made sure that I transformed the keypoints
according to the translation of images as well. Below are loaded images with keypoints:

|

|

|

|
I trained a 8-layer neural network. It is consisted of:
- Convolutional layer with 7x7 filter and 64-channel output
- Convolutional layer with 5x5 filter and 192-channel output
- Convolutional layer with 3x3 filter and 384-channel output
- Convolutional layer with 3x3 filter and 256-channel output
- Convolutional layer with 3x3 filter and 256-channel output
- Fully connected layer with 2048 output channels
- Fully connected layer with 1024 output channels
- Fully connected layer with 116 output channels, corresponding to 58 keypoints
Each layer besides the last layer is followed by ReLU and max-pooling. The model was trained over 20 epochs and the Adam optimizer with the learning rate of 0.0025.
Below are the training and validation losses over epochs:
Training and Validation Losses
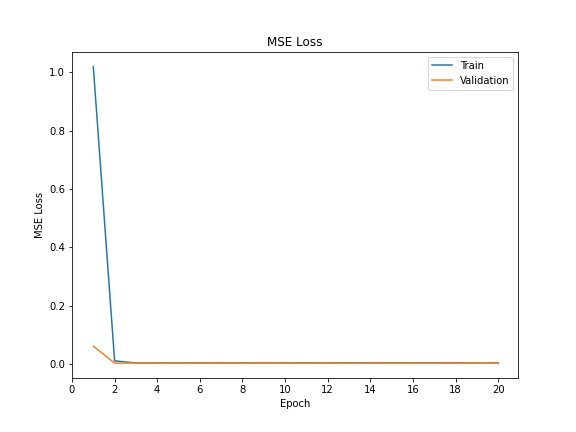
|
Below are the results. Again, while some of them hit the ballpark, the neural net was unable to correctly predict some images, even with data augmentation. This is because of the same reasons as before; there are not much variations in terms of head orientation and lip closure. Because it is more advantageous for the neural network to stick to a general shape that adhere to the majority of the data, it would incorrectly determine images of people facing sideways. Perhaps having more data or other forms of data augmentation would help mitigate the inconsistencies.
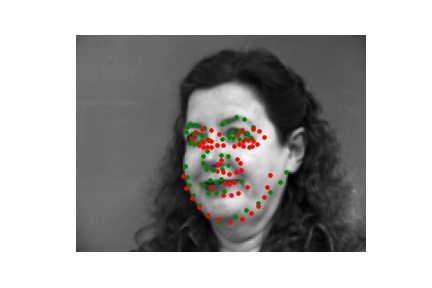
|

|

|

|

|

|

|

|
Also, below is a visualization of learned filters of the first layer. Notice that the filters have a dark concentrated spot, which seems to correspond to edges and points that are considered facial features.

|
Train with Large Dataset
For this task, I used the data augmentation technique used for the previous part to train a well-tested
preexisting neural network to classify a larger dataset. Here, instead of IMM dataset, I used the ibug face in
the wild dataset to train a 68-point facial keypoints detector, consisted of 6666 images of varying sizes. To
load the data into the dataloader, I had to first crop the images so that only the face portions are fed into
the model. Then, I resized the image to (224px, 224px) for consistency. Then, I used rotation and
translation to triple the size of training dataset.
Below are some images fed into the dataloader:

|

|
|

|
For the neural network, I used the ResNet18 model, a deep neural network designed for residual learning. I modified the input channel of the network to be 1, as I was using greyscale images. I also modified the output channel to be 136, the x and y coordinates of the 68 facial keypoints. I trained the model over 20 epochs using an Adam optimizer with learning rate of 0.001.
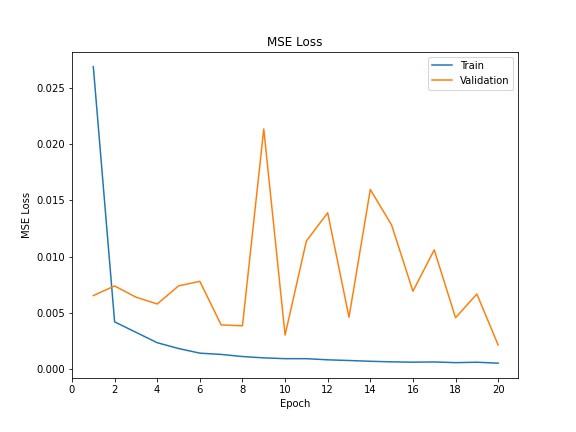
Below are the training and validation losses over epochs:
Training and Validation Losses
|
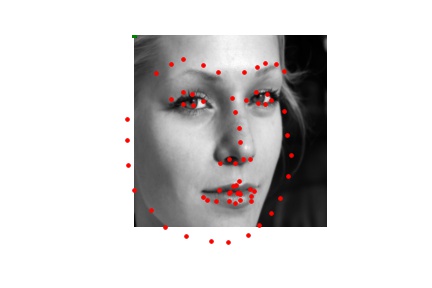
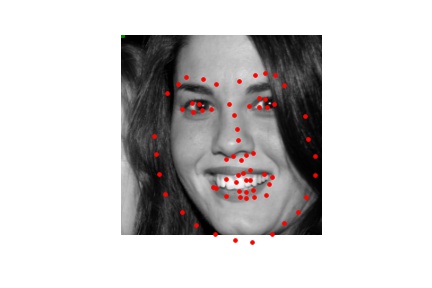
The Mean Absolute Error of predictions of the test dataset using this model, as reported by Kaggle, is 19.29542. Perhaps using a different learning rate or data augmentation techniques would have led to improvements. Below are some predictions:
|

|

|

|
|

|

|

|
I also attempted to generate predictions from my own collection of images. While the predictions seem to be pretty good, my model struggles to correctly determine keypoints around the mouth. This may be because there are variations in how the mouth looks (closed, opened, smiling, frowning, etc.) as opposed to other facial features that are generally more consistent.

|

|

|