For this project, I learned how to use PyTorch and train a CNN to be able to detect a single point at first, a full list of points, and then train on a even larger dataset while using Google Colab (for the GPU). We were tasked to first start learning the basics of od detection with a dataloader, which involves understanding how to build a class to use as a dataset. Second, we needed to learn how a CNN works and how to feed in the correct values and functions in order to build a good one. Lastly, we looked at the loss function and optimizer to train our CNN. Through this process, we saw how our loss value changed overtime and learned why our predictions might not be so great (and how to get more data to train using data augmentation).
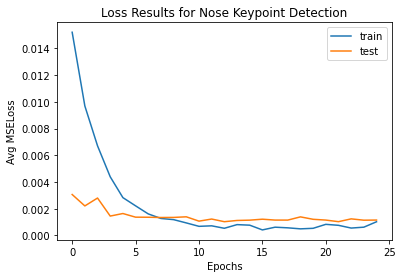
For this part of the project, we are looking at how to predict the nosetip point. I mainly used the dataloader tutorial and then the page after that to just start. It took a while to get the hang of how it all works in PyTorch. For the data, I ended up collecting all the image file names and their respectice landmark points using code from Project 3, where I used regex. After, I feed in my class, the image file names and landmark points. From there, the data is fully loaded. I ended up using batch sizes of 1, since I started debugging better that way, and just kept it as so. I believe that increasing the batch size may decrease the runtime, but it didn't take that long to train, so I just left it as 1.
For the CNN, I had to experiment a lot and learn how the input/output channels affect future layers and the
layer sizes. I knew that the first input channel for the convolution layer needed to be 1 as it is a gray scale image and that the last
output for the fc layer needed to be the number of values we wanted.
I ended up using 3 convolution layers and 3 fully connected layers as that seemed to work best with my set up.
I also applied relu and then maxpool (2,2) on every convolution layer. I used a total of 25 epochs after trying 10. My learning rate was .001.
The following is what I used:
self.conv1 = nn.Conv2d(1, 12, kernel_size=5)
self.conv2 = nn.Conv2d(12, 12, kernel_size=3)
self.conv3 = nn.Conv2d(12, 12, kernel_size=3)
self.fc1 = nn.Linear(480, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 2)
My forward function is as follows:
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = self.pool3(F.relu(self.conv3(x)))
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = self.fc2(x)
x = self.fc3(x)
Layer 0
Layer 1
Predicted: Blue, Original: Red





Predicted: Blue, Original: Red



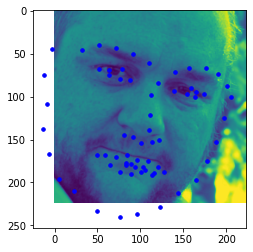
I think my detection fails here as I don't have enough data and this is one point. I also train on the same set of data that is never changing (no augmention). My CNN may also not be the most efficient and best for our case. Another reason could be that our pixel quality is small (80x60), so not much detail is picked up and it is hard for out NN to determine if something is the nosetip or not. Most of my failing ones are also those who are looking to the side. Photos like those are harder for the CNN to determine as there is less data points for those.
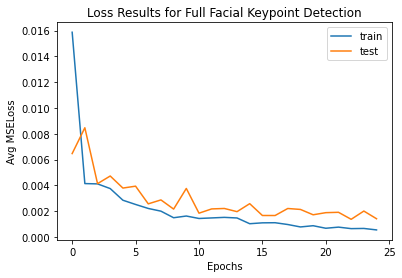
For this part of the project, we are looking at predicting all 58 landmark points instead of just one. The process was the same. However, I did run into some trouble with data formatting and mainly utilizing data augmentation. I was able to create functions for color jitter, rotate, and shift.
For the CNN, I also had to experiment more. We have a total of 58 * 2 (or 116) points to predict.
I ended up using 5 convolution layers and 3 fully connected layers as that seemed to work best with my set up.
I also applied relu and then maxpool (2,2) on every convolution layer. I used a total of 25 epochs after trying 10. My learning rate was .001.
The following is what I used:
self.conv1 = nn.Conv2d(1, 12, kernel_size=5)
self.conv2 = nn.Conv2d(12, 16, kernel_size=3)
self.conv3 = nn.Conv2d(16, 16, kernel_size=3)
self.conv4 = nn.Conv2d(16, 32, kernel_size=3)
self.conv5 = nn.Conv2d(32, 32, kernel_size=1)
self.fc1 = nn.Linear(768, 360)
self.fc2 = nn.Linear(360, 240)
self.fc3 = nn.Linear(240, 116)
My forward function is as follows:
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = self.pool3(F.relu(self.conv3(x)))
x = self.pool4(F.relu(self.conv4(x)))
x = self.pool5(F.relu(self.conv5(x)))
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = self.fc2(x)
x = self.fc3(x)
Layer 0
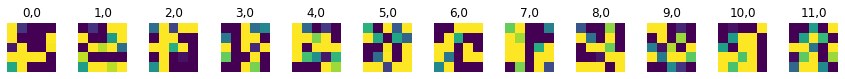
Layer 1
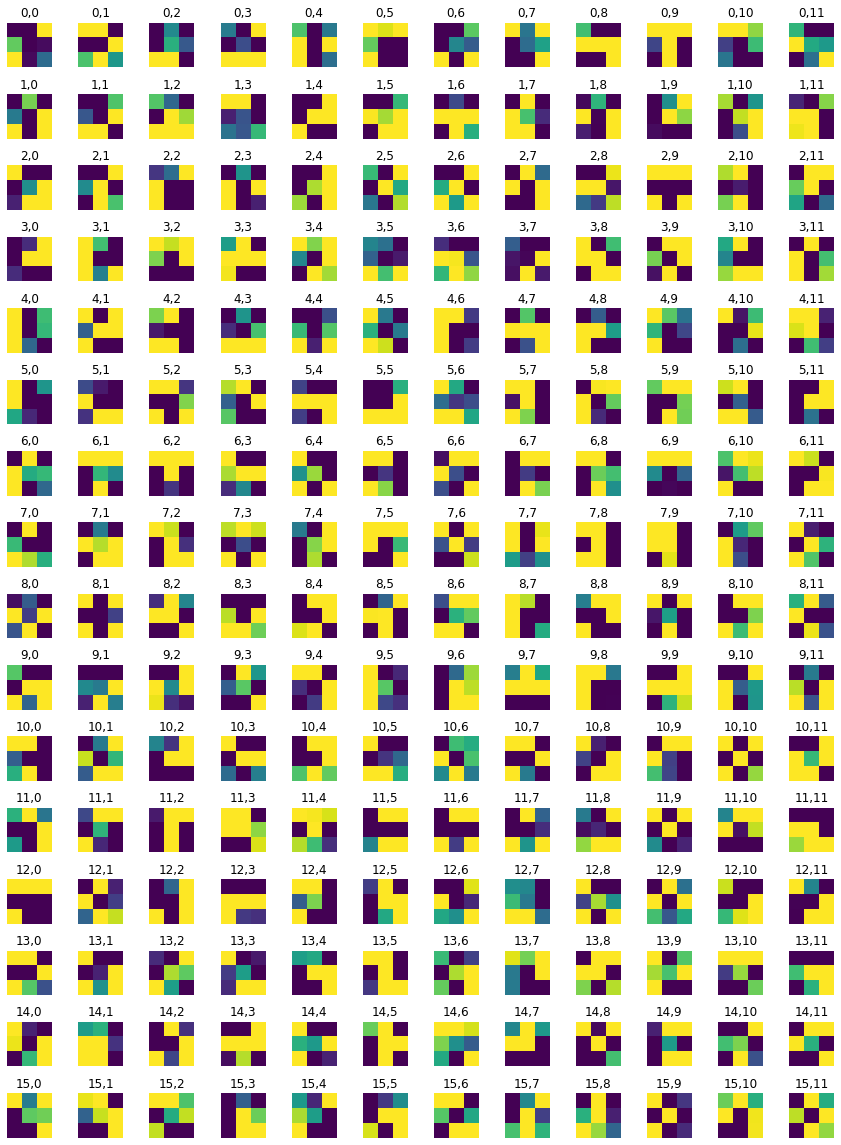
Predicted: Blue, Original: Red




Predicted: Blue, Original: Red



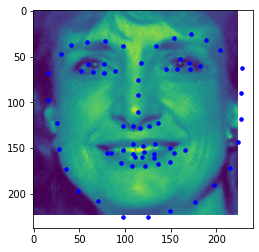
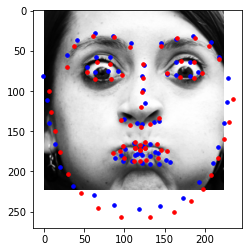
I think my detection fails in these areas as it still isn't the best for people who are looking to the sides. Although the photo quality is bigger now (240x180), the ones looking to the side, or images with an expression have a hard time beign detected. Most images in this set are of people with little or no expressions. There are always also some photos that still are fine for those looking sideways, while those with a straight face, which you'd expect succeed, still fail. To improve, I would introduce more epochs and more augmented data as well as a different CNN model (more robust one).
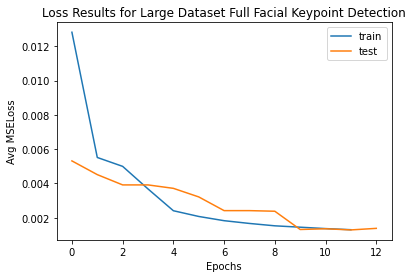
For this part of the project, it was simple for me to utilize what I had done in part 2 after correctly reformatting and cropping the data. I ran into a division by 0 error with cropping and had a lot of difficulty create functions for the transforms to work correctly. There were issues with using a numpy array, PIL image format, and tensor. However, I eventually got it to work. I built my transformations for data augmentation as classes for jitter and rotate. I am experimenting with using different batch sizes like 1, 32, and 64. Higher batch sizes are faster, but may lead to a smaller accuracy. I also experimented with different epochs. My learning rate was .001.
For the kaggle portion, I had some data mixups at first with train and test data as well as just understanding how to generate key points and save them in the correct format for submission.
For the CNN, I used resnet18, but needed to change the first
convolution layer input size to 1 and the last output to 68 * 2 or 136 points.
To see the CNN parameters, look at the bottom of the page.
I did this by:
self.resnet18 = models.resnet18()
self.resnet18.conv1=nn.Conv2d(1, 64, kernel_size=5)
self.resnet18.fc=nn.Linear(self.resnet18.fc.in_features, 136)
Layer 0
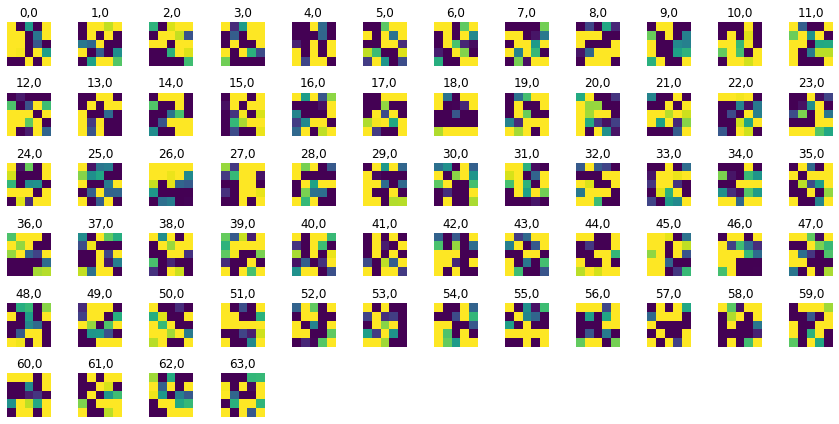
Layer 1 (view in separate tab)
Other Layers Not Visualized
Predicted: Blue

Predicted: Blue, Original: Red
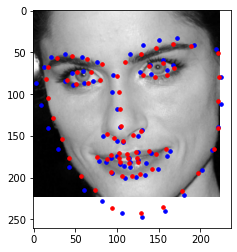
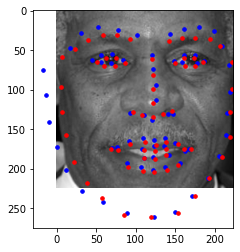
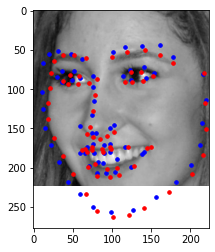
Predicted: Blue, Original: Red
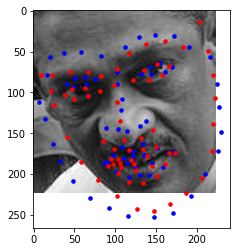
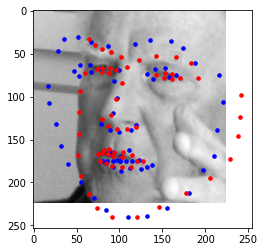
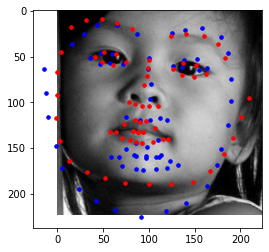
I believe these photos still fail with similar reasoning to part 2. If given more time, I would improve with more epochs and more augmented data. The images with weirder expressions or faces to the side are harder to pick up.
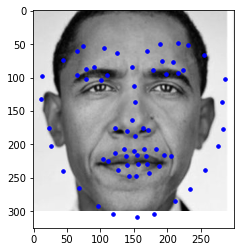



I ended up with a Kaggle MAE of 14.23660.
For my bells and whistles, I wasn't able to gather enough photos in time and okay ones to show for morphing a bunch of photos. I also didn't have the time to adapt my project 3 code. However, I would expect that the morphing would be way better, and definiteley better than more own landmarks. It would be really easy to match the landmarks given that they are good results. Given more time, I would have tried to use other types of CNN models and took more time with data augmention and epochs.
So instead, I read the anti-aliased max pool paper a little to try to understand how I could use that to my benefit. I followed the tutortial on the github (https://github.com/adobe/antialiased-cnns) and have it implemented as examples here.
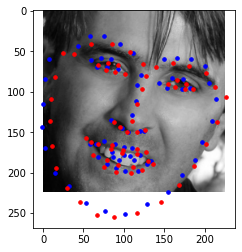
It seems like the antialiased CNN for me looked slighly better for some images, but the overal results weren't that different.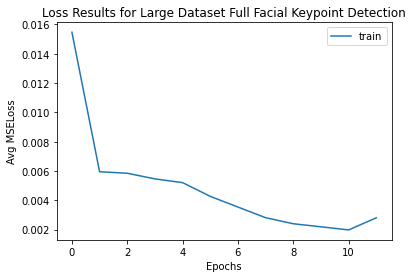

Although this project seemed really intimidating, it was also really worthwhile and fun. I deinitely learned a lot more about NNs than I would have. It is cool to see that your predictions get more and more accurate. It was a headache figuring our the dataloading and data formatting/transformations though.