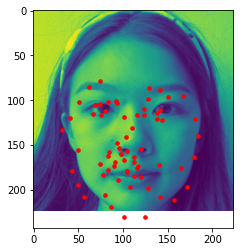
In this project I train a convolutional neural network using the IMM dataset to detect facial keypoints. First I find just the nose points, then move on to find all face features. I also use data augmentation to train the model better by changing the color map and shifting the image.
I first created a dataset class and used the dataloader to read in the asf files to find the corresponding face
points of each image. For the CNN (Convolutional Neural Network), I used PyTorch's "Defining the network" tutorial and created
a Net object with the following properties:
Net(
(conv1): Conv2d(1, 6, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(6, 12, kernel_size=(3, 3), stride=(1, 1))
(conv3): Conv2d(12, 16, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=640, out_features=500, bias=True)
(fc2): Linear(in_features=500, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=2, bias=True)
)
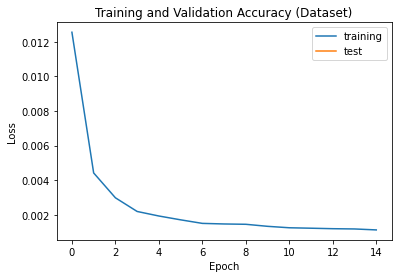
I ran 25 epoches on the dataset, with a learning rate of 0.001 and loss function using nn.MSELoss. I split the dataset into training and validation sets,
and fed them into the dataloader. My resulting loss data for
the trained loss and validation loss can be visualized here:
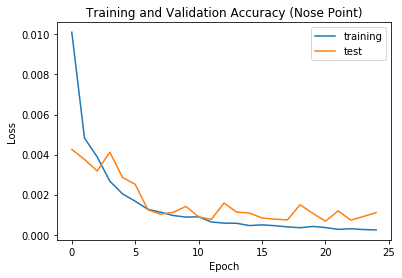
As shown above, the loss decreases as we train more epoches. The result of the trained datapoints generate some good predictions, and some bad predictions. You can see below the trained point in red, and the original (ground-truth) point in blue. Here are two examples of the good predictions:


Here are 2 examples of the bad predictions. As you can see, the bottom of the lip or side of the nose are predicted instead. Many of the bad images have the result on the side of the nose, probably because of the angle of some faces being pointed to the side.


I used the same methodology as the nose tip detection but included the entire set of face points this time. Here are the properties of my Net object:
FullFaceNet(
(conv1): Conv2d(1, 6, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(6, 12, kernel_size=(3, 3), stride=(1, 1))
(conv3): Conv2d(12, 12, kernel_size=(3, 3), stride=(1, 1))
(conv4): Conv2d(12, 16, kernel_size=(3, 3), stride=(1, 1))
(conv5): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1))
(fc1): Linear(in_features=384, out_features=200, bias=True)
(fc2): Linear(in_features=200, out_features=150, bias=True)
(fc3): Linear(in_features=150, out_features=116, bias=True)
)
This time I had to increase the fc3 to yield 116 features (2 * 58). Again I ran 25 epoches, this time with a learning rate of 0.0007. I
also used data augmentation with the tutorial "Pytorch Data Augmentation & Image Transforms Tutorial" by Aladdin Persson. The types of transformations I used
were shifting the image by a random value between 1-15, and rotating the image with a value between 1-10. This would help my neural net perform better
especially for faces that were tilted.
Here is the graph of the
loss and accuracy data:
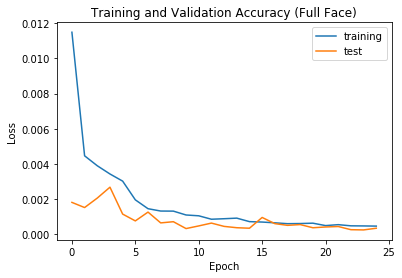
You can see below the trained point in red, and the original (ground-truth) point in blue. Here are two examples of the good predictions:


Here are two examples of where my neural net predicted inaccurately:


(1) On the left side, it seems to have predicted the eyebrows as the eye, which shifted the whole face upwards. My guess it that the
side view does not have as much data and therefore is not as accurate since his head is tilted a decent amount, plus my data augmentation
of rotating the image a bit.
(2) On the right, you
can see that part of his chin is cut off due to my data augmentation (shifting by a random value between 1-10). I believe that the neural net
had trouble finding the bottom child point because of this and predicted the bottom of the lip instead, which ultimately shifted the whole face upward.
The other data didn't have a similar expression to this man so I think that also made it harder to predict.
Here are the learned features from the neural net. Below are the 0th and 1st layer, respectively.

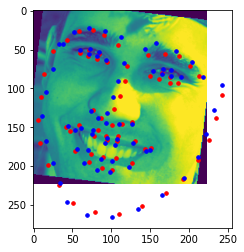
Our current dataset has less than 100 images, so we want to train our neural network on a large dataset. We use the ibug face in the wild dataset with 6666 images. I used ResNet18 to predict my model, a learning rate of 0.0007 and resulted in a MAE of 34.48381. Because the dataset was very big, I only used 15 epochs. Here are some results from...
(1) The dataset predicted (red) vs ground-truth landmarks (blue)
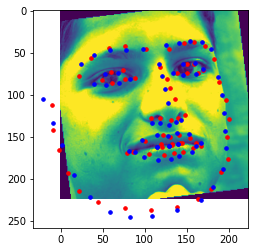
(2) The Kaggle dataset
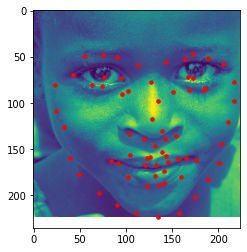
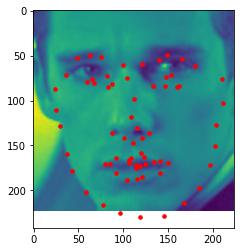
(3) My collection
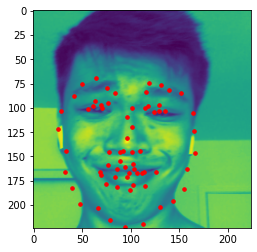
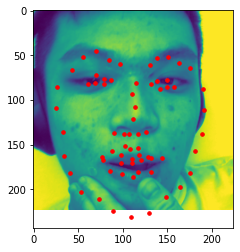

(3.5) My collection (Failed Case)