
This Neural Network consists of 3 convolutional layers each outputting 12 channels. The first layer uses a kernel of size 7x7, the second uses a kernel of size 5x5, and the last one uses a kernel of size 3x3. Each convolutional layer is followed by a Relu function, which is then followed by a Maxpool with kernel size 2x2. The final maxpool is followed by a fully connected layer with 28 out features. The relu function is applied once more before a final fully connected layer that outputs 2 features, which should correspond to the x and y coordinate of the nose.
To train, I used a learning rate of 0.0005 with an Adam optimizer, and a MSE loss function. I trained on a batch size of 4 for 25 epochs.
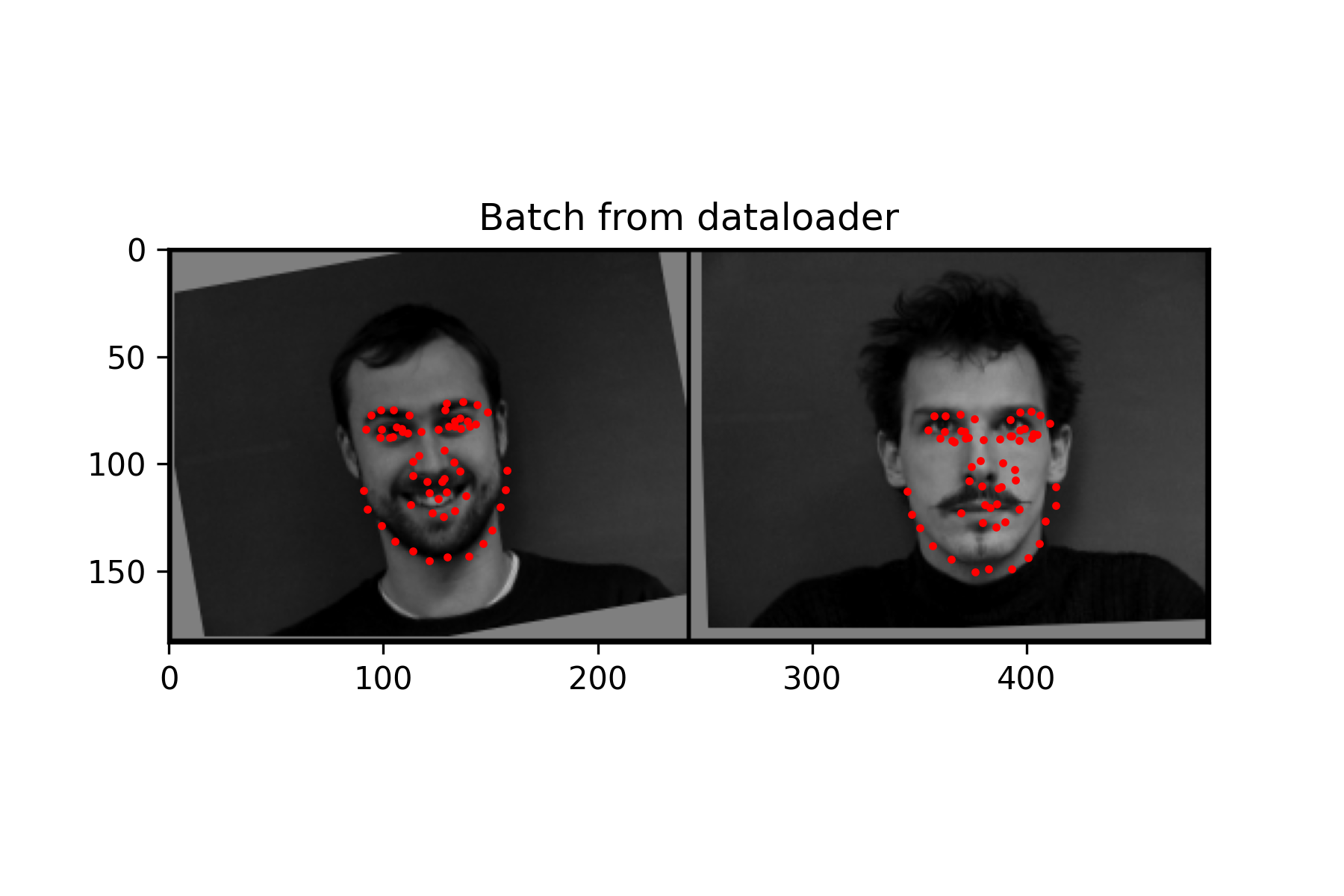
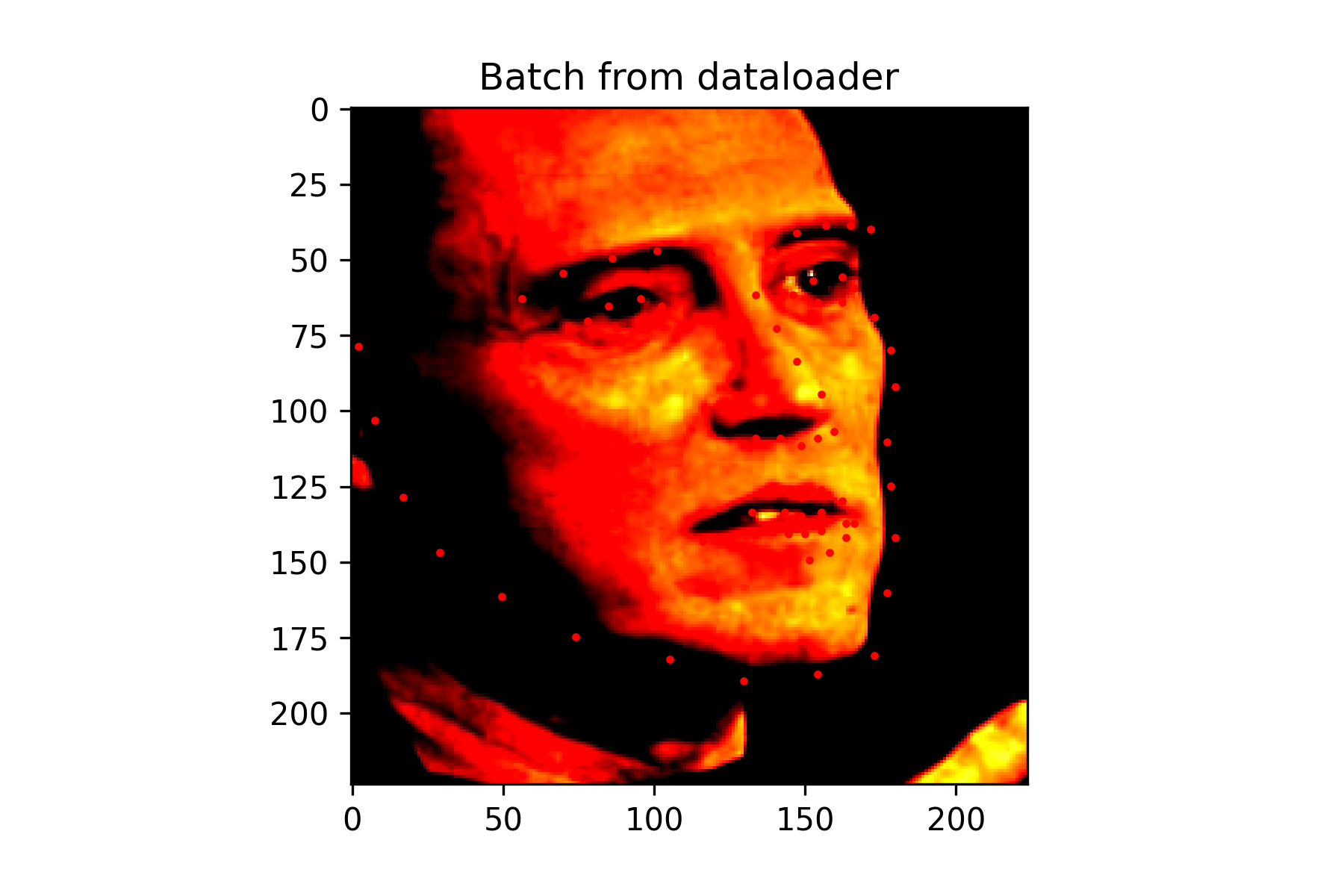
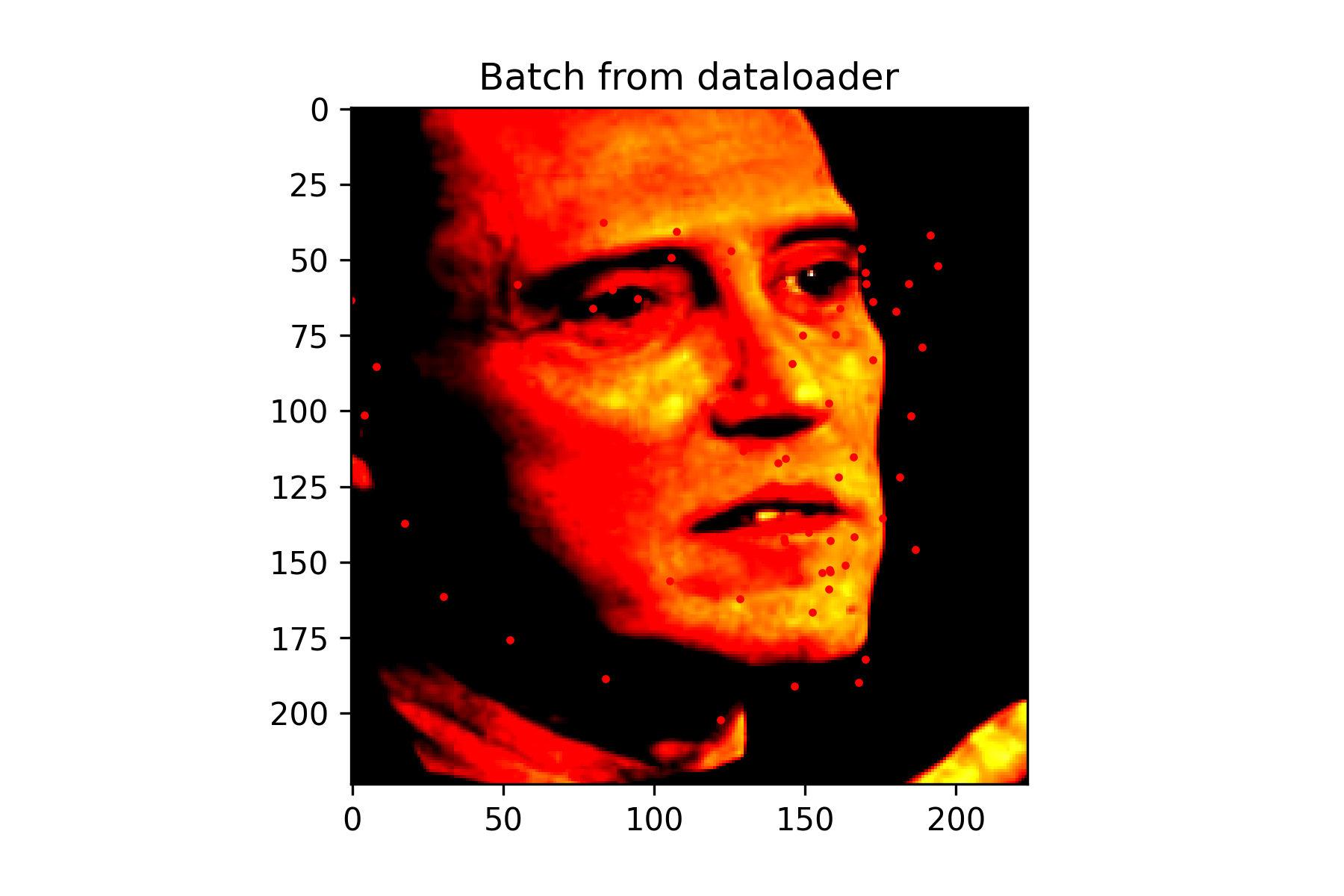
This neural network consists of 6 convolutional layers with a 3x3 kernel. The first 3 convolutional layers have 16 output channels, while the last 3 have 32 output channels. Each convolution is followed by applying a Relu. Every 2 convolutions, a max pool with kernel size 2x2 is also applied. There are also 2 fully connected layers. The first has 1024 output features followed by a Relu, while the second has 116 output features for the x and y coordinate of each of the 58 landmarks.
To train, I used a learning rate of 0.0001 with an Adam optimizer, and a MSE loss function. I trained on a batch size of 4 for 30 epochs.
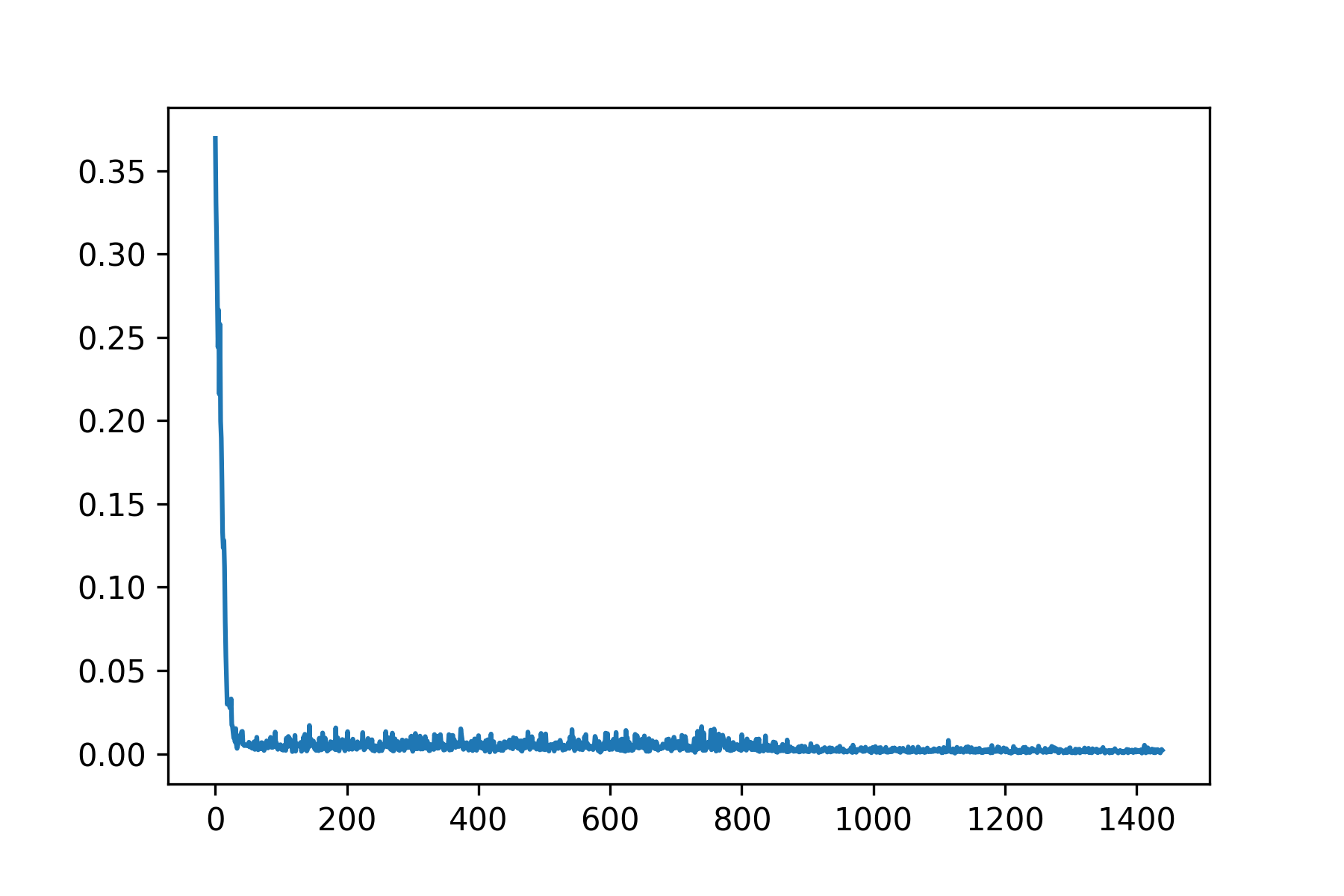
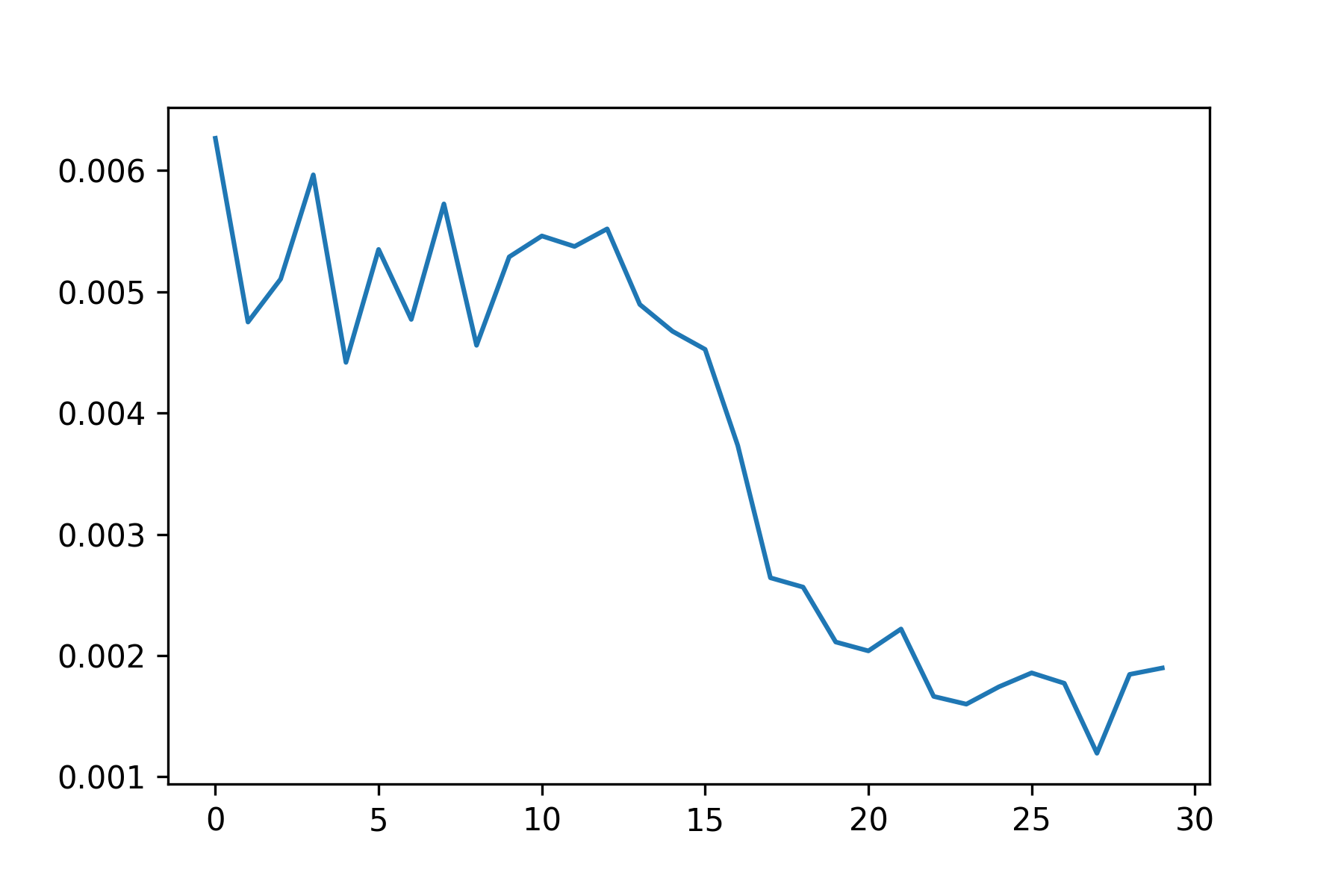
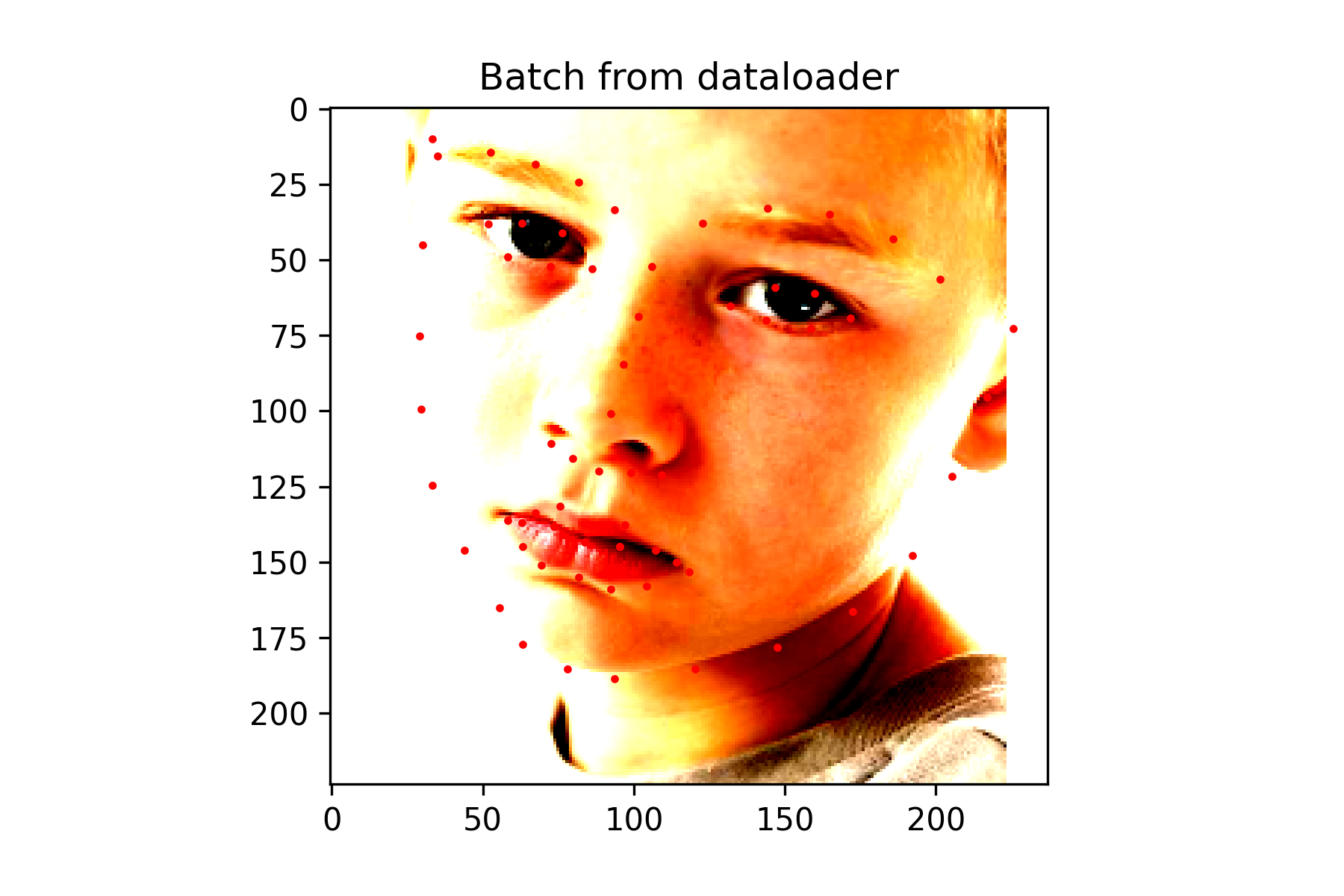
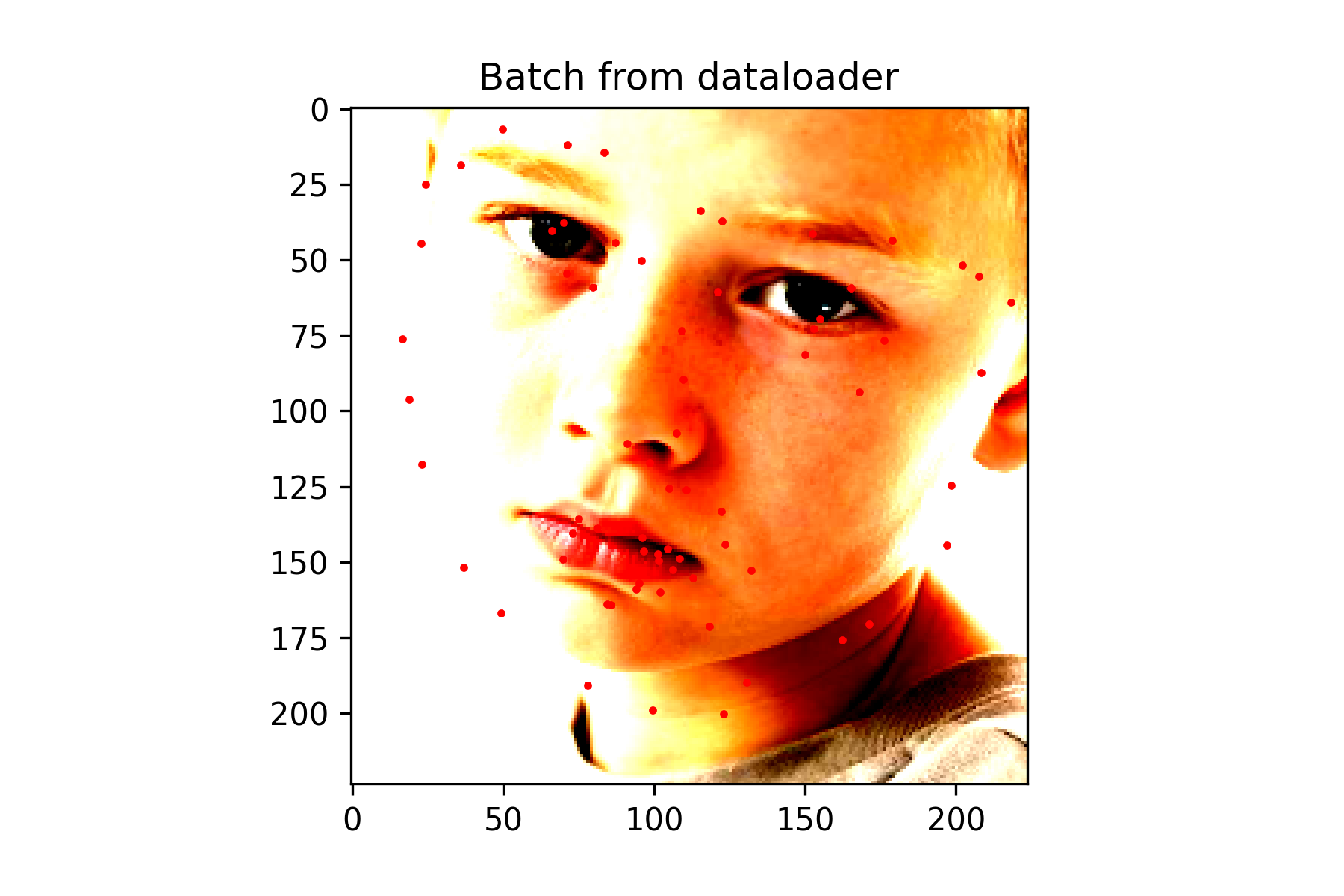
For this network, I decided to finetune a pretrained model (Resnet50). I modified the output layer to have 136 output features to represent the 68 possible land marks, and froze all of the convolutional layers except for the last one.
To train, I used a learning rate of 0.0005 with an Adam optimizer, and a MSE loss function. I trained on a batch size of 16 for 10 epochs
Multiple data augmentation techniques were used in the 2nd and 3rd task. Images were shifted randomly horizontally and vertically up to 10 pixels. They were also rotated a random amount up to 15 degrees. Vertical and Horizontal flip transformations were implemented, but due to poor performance they were not used in the end result. ColorJitter was also implemented but not used due to lack of a significant accuracy increase.

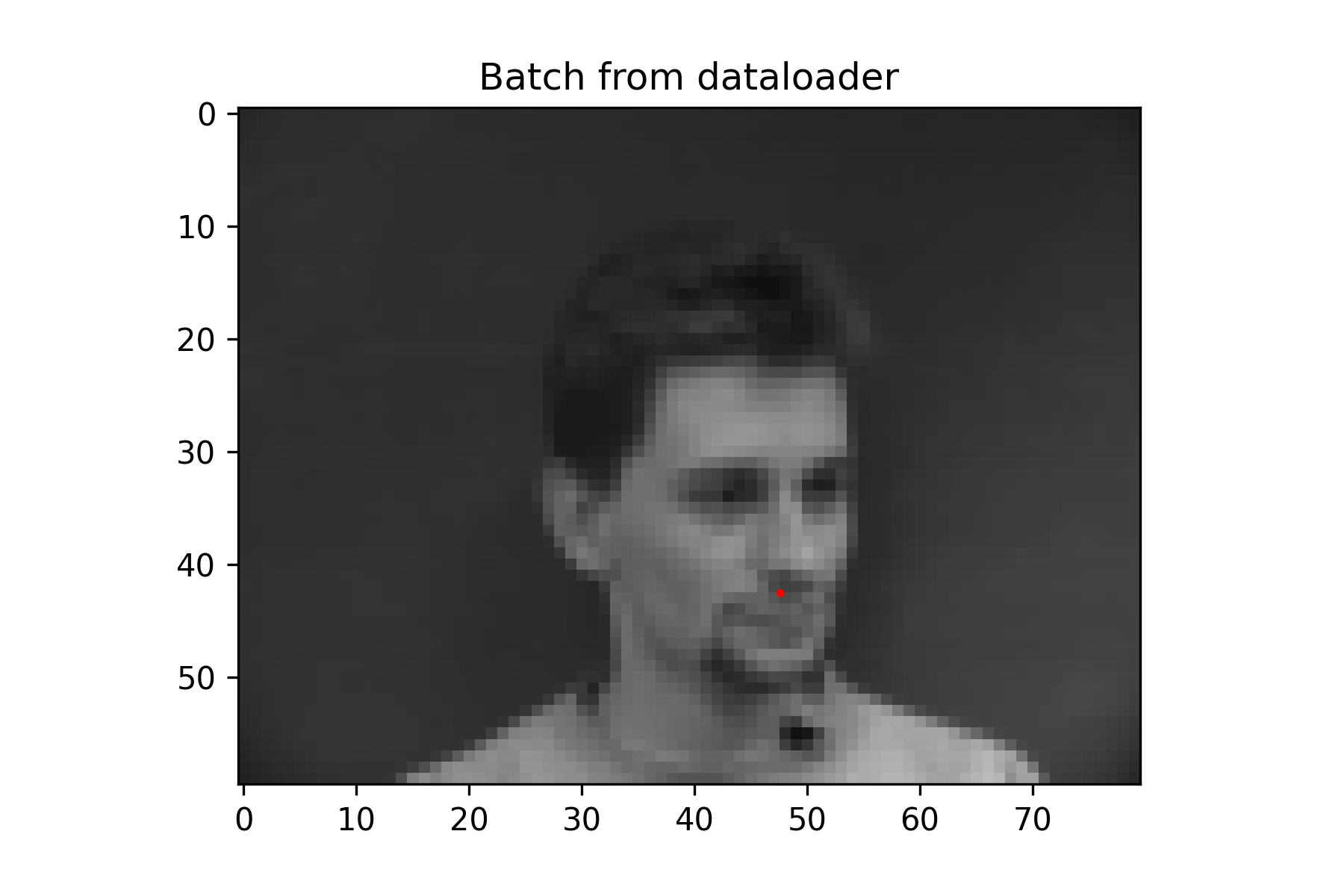

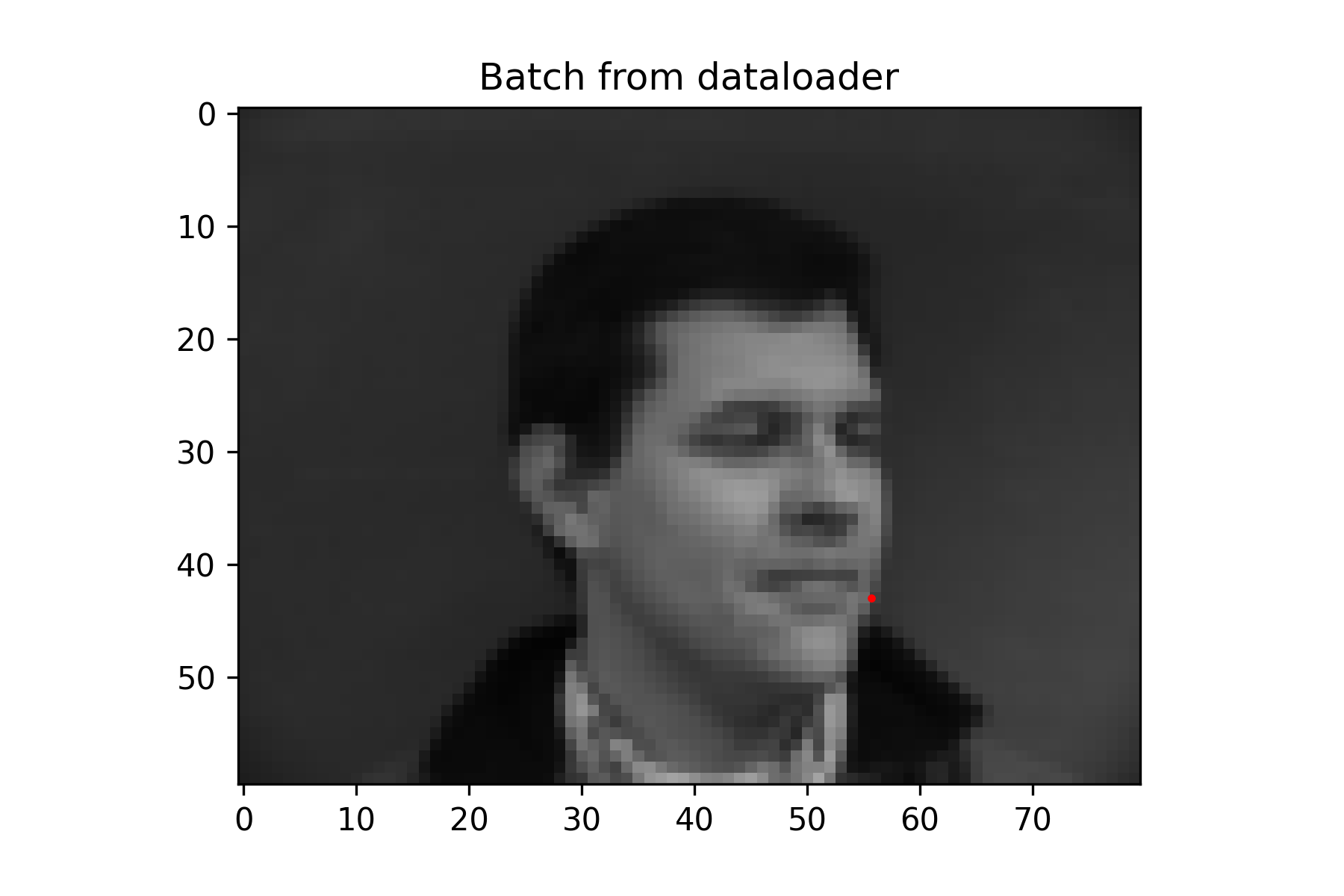

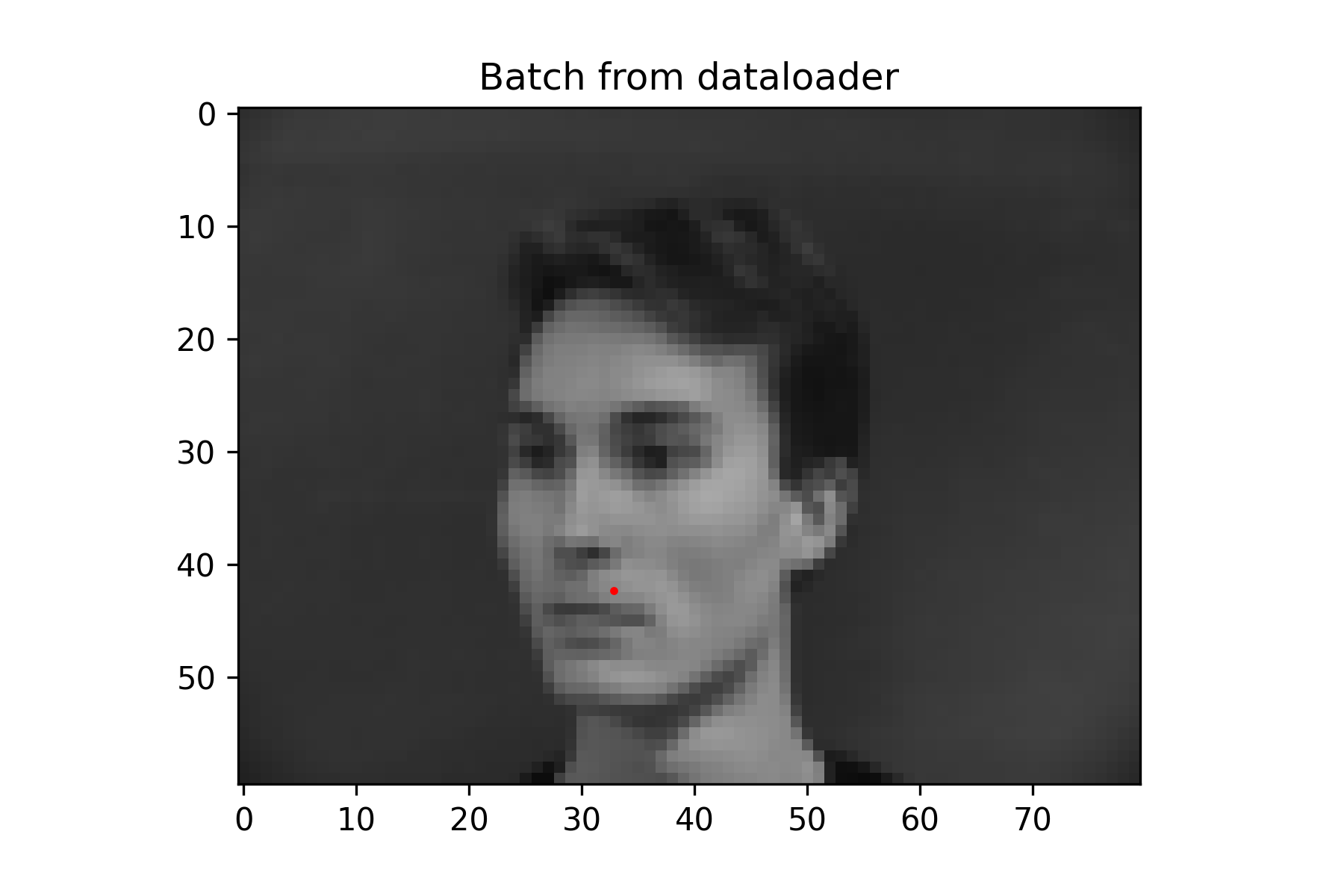

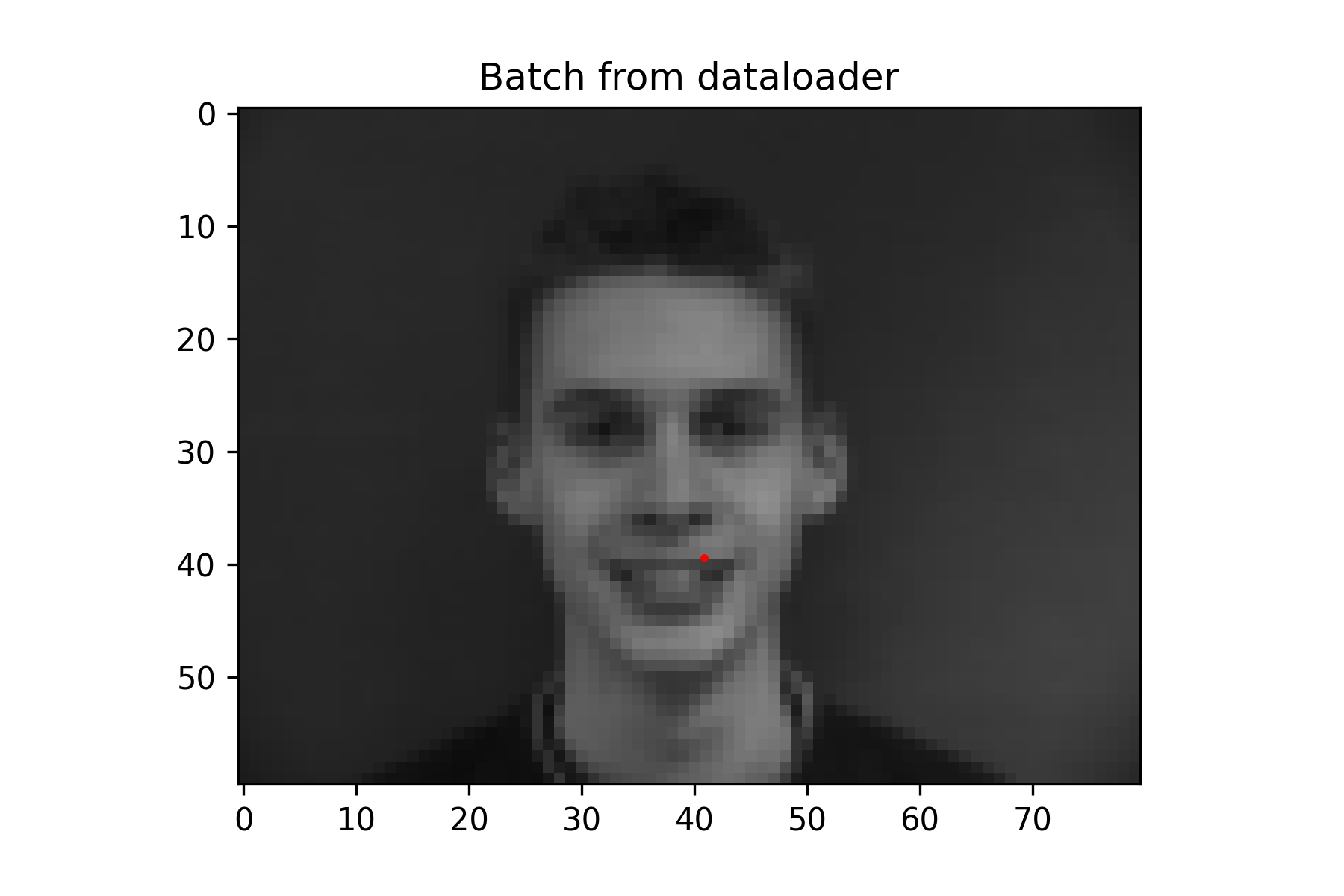
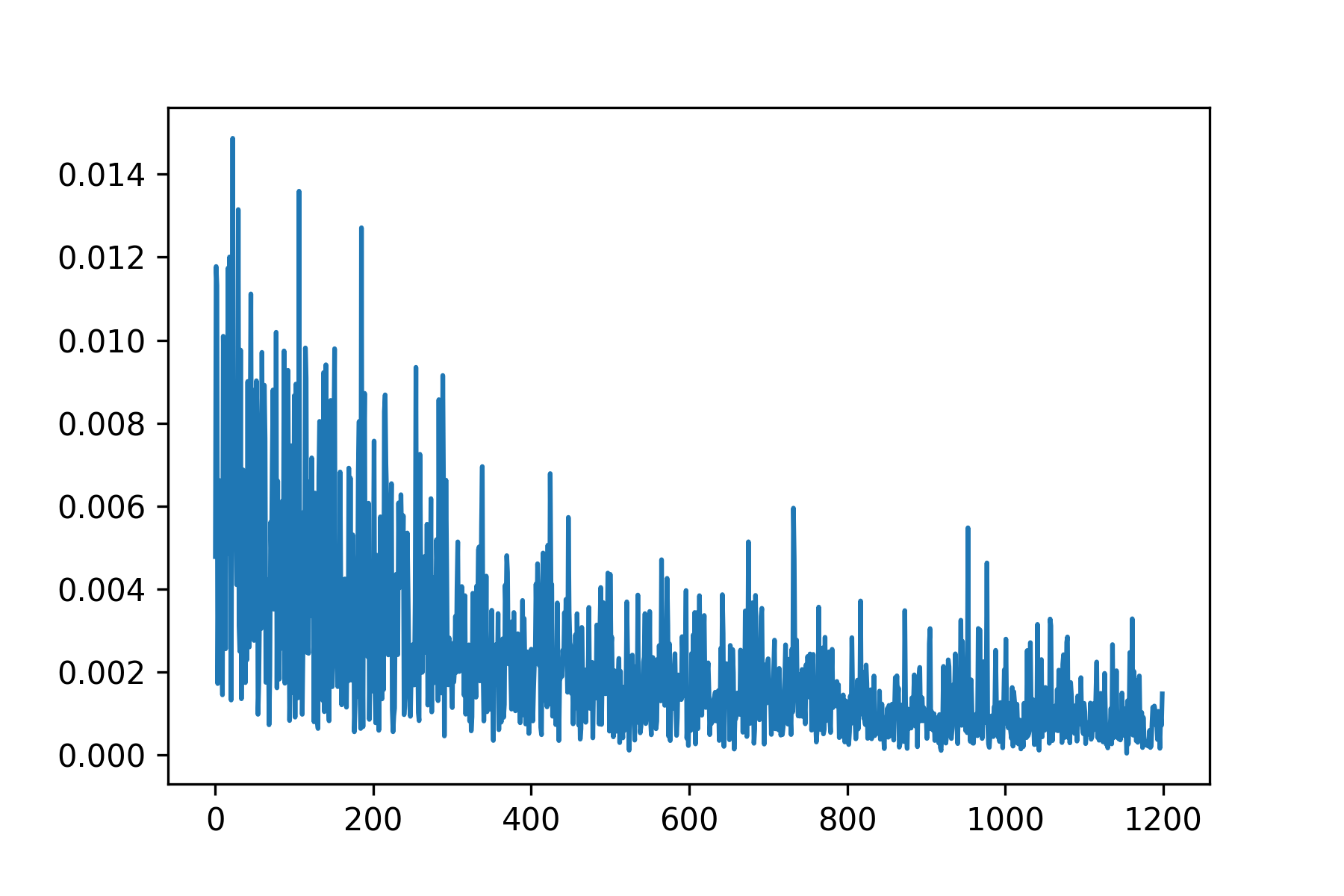
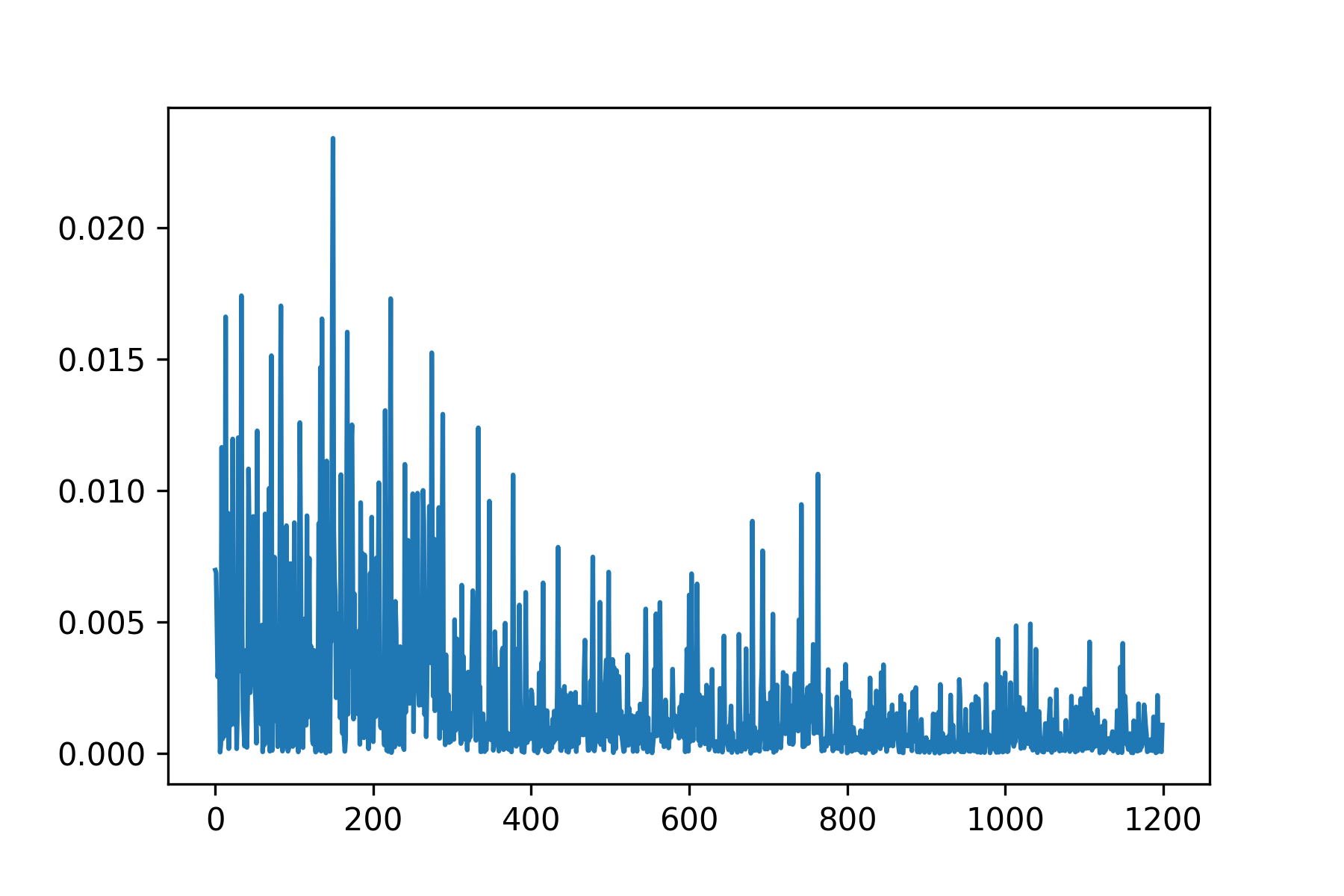
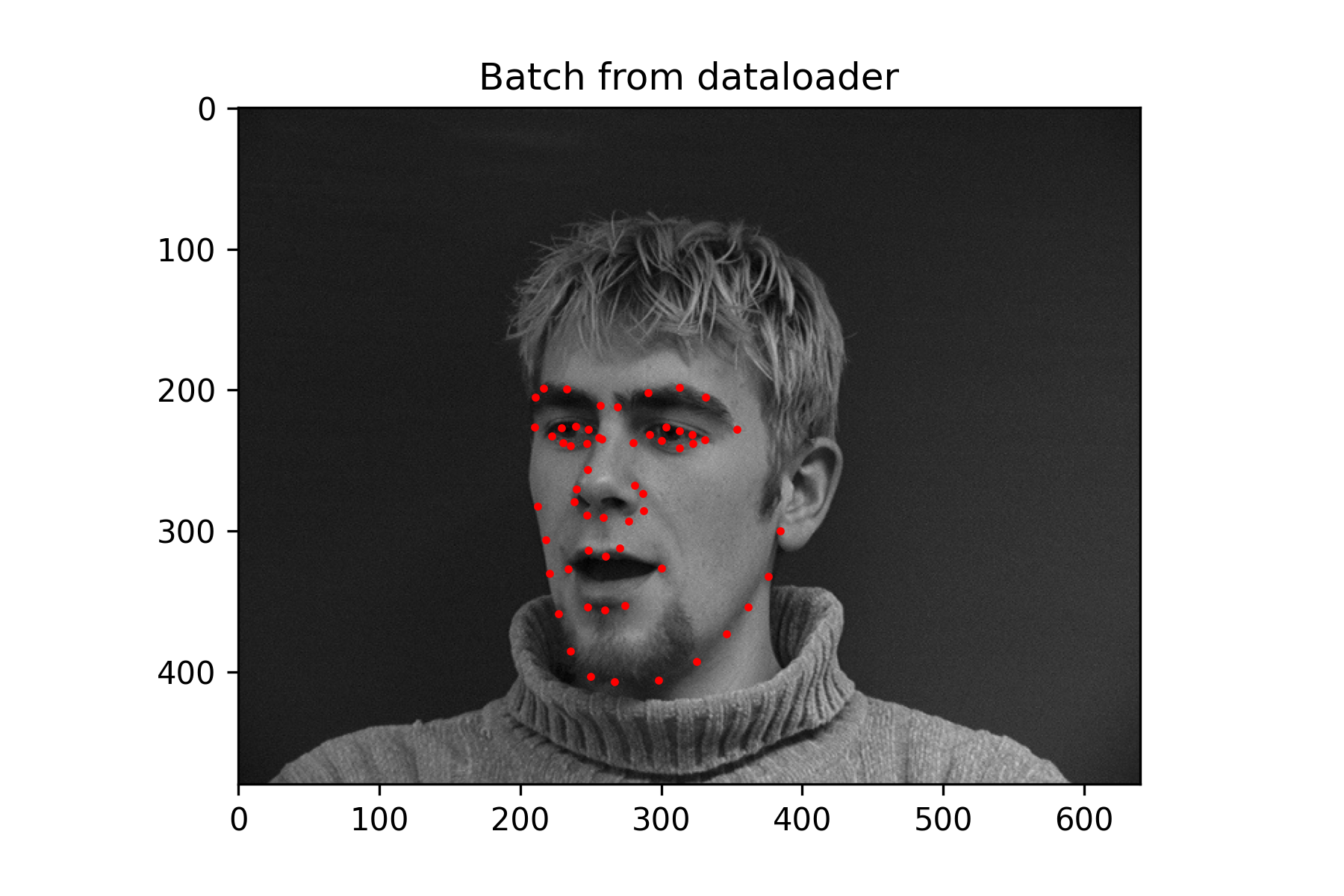
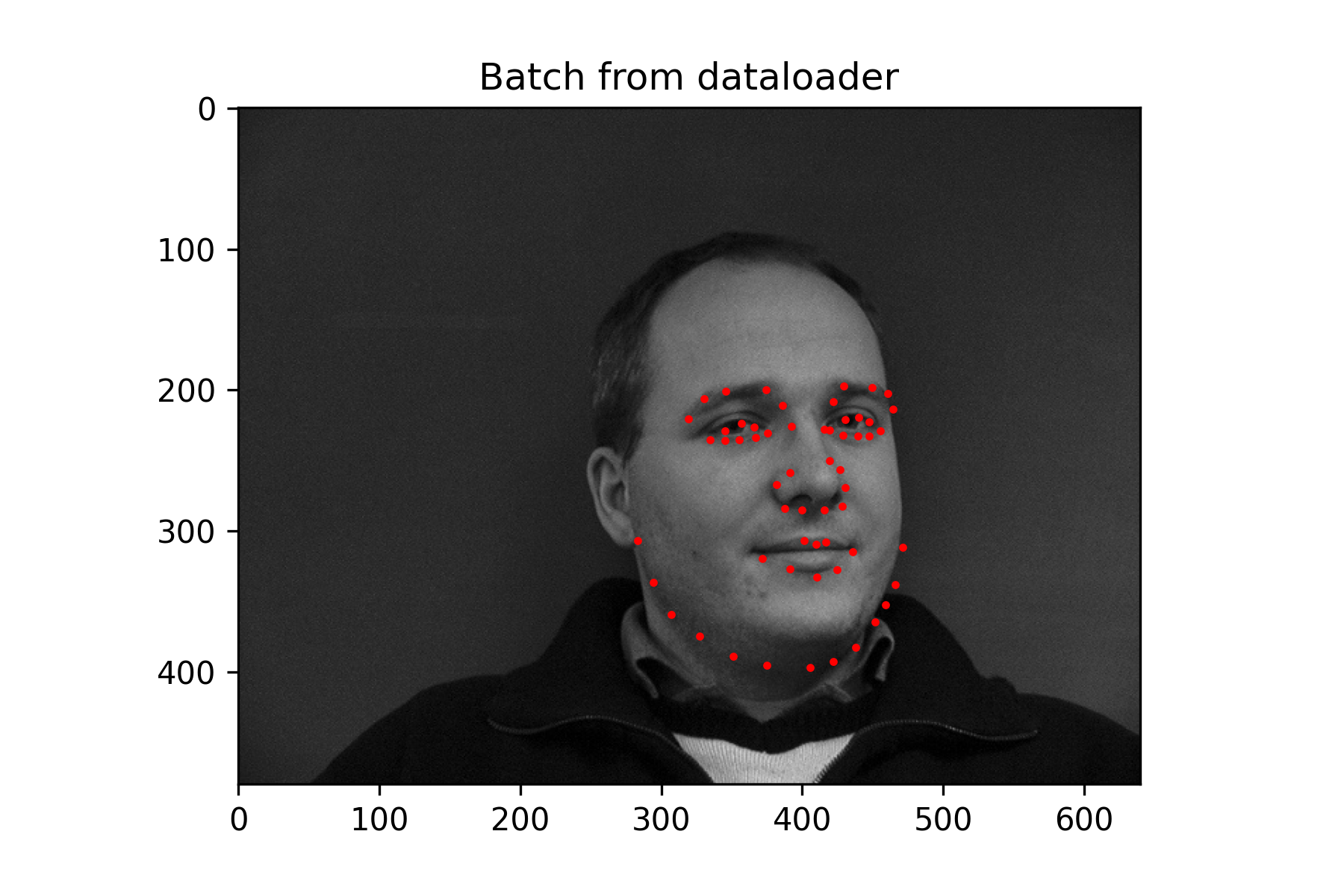
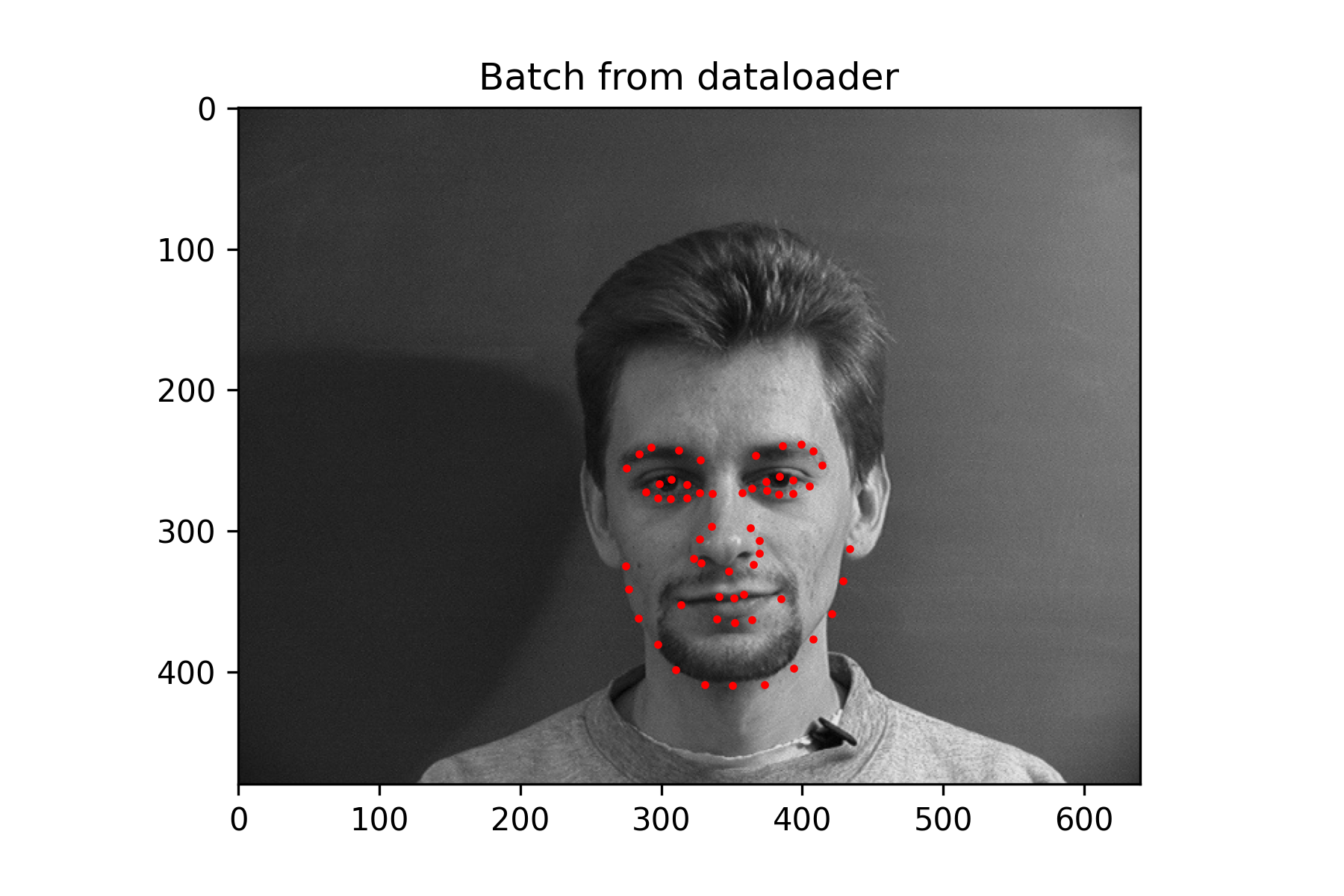

























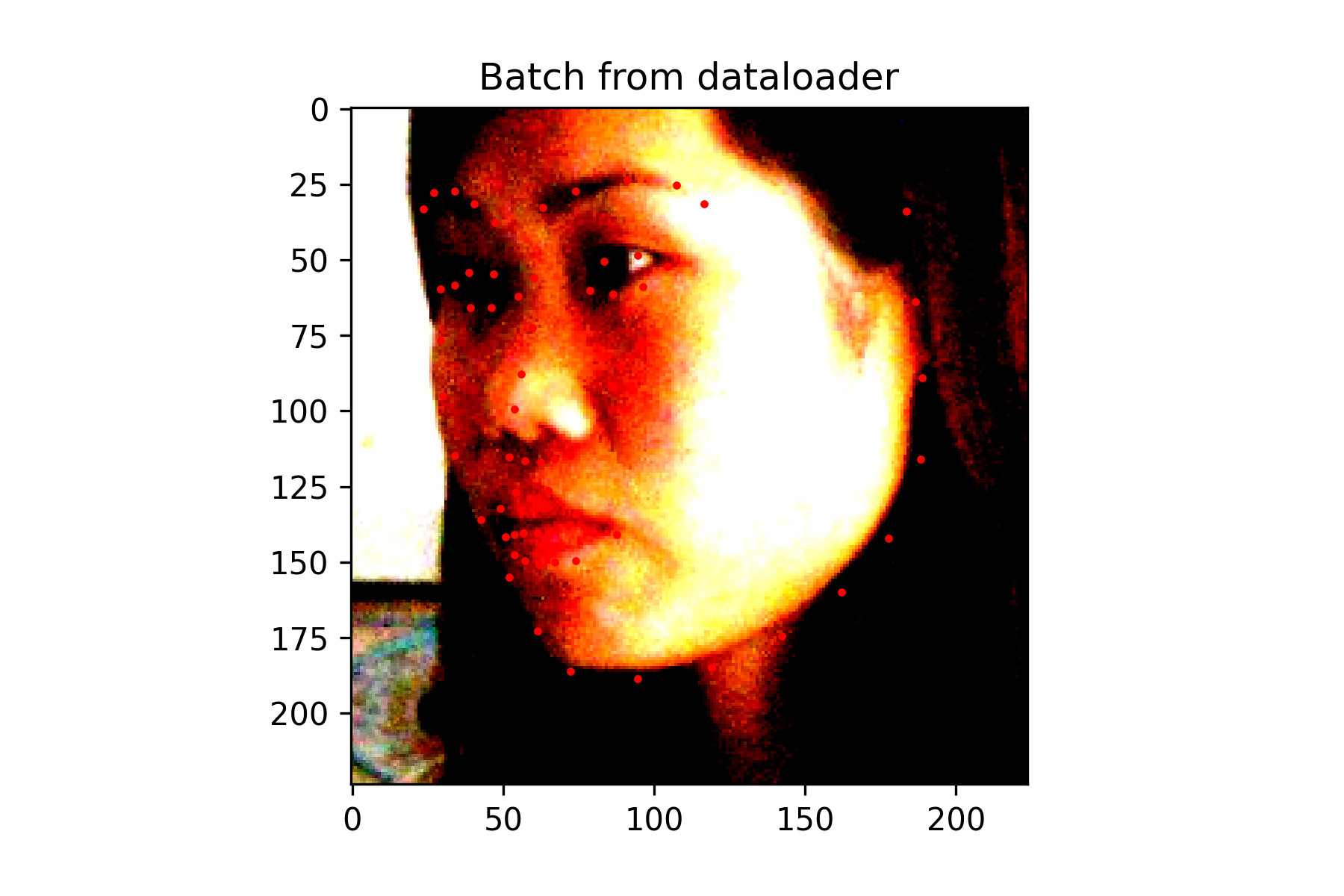
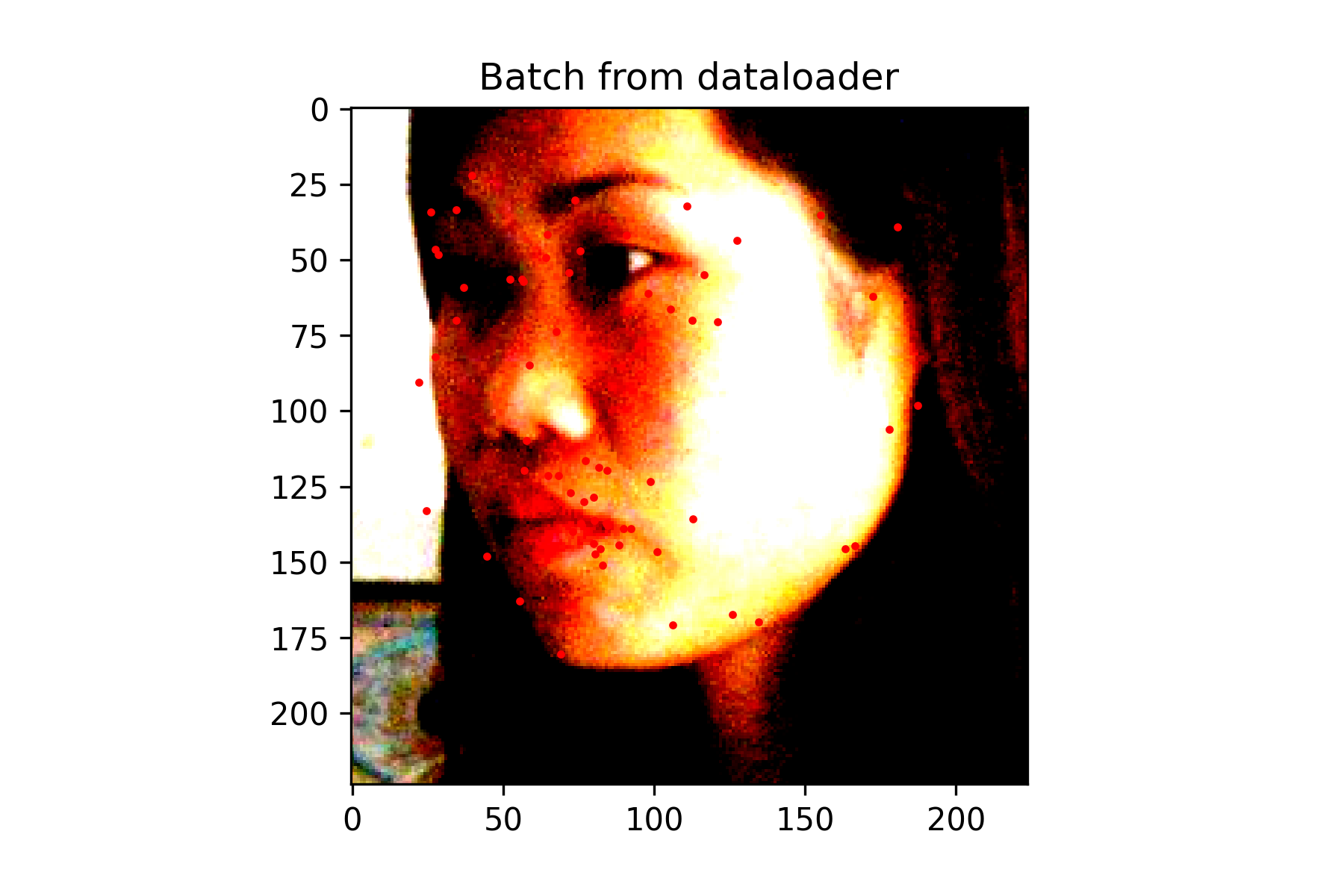
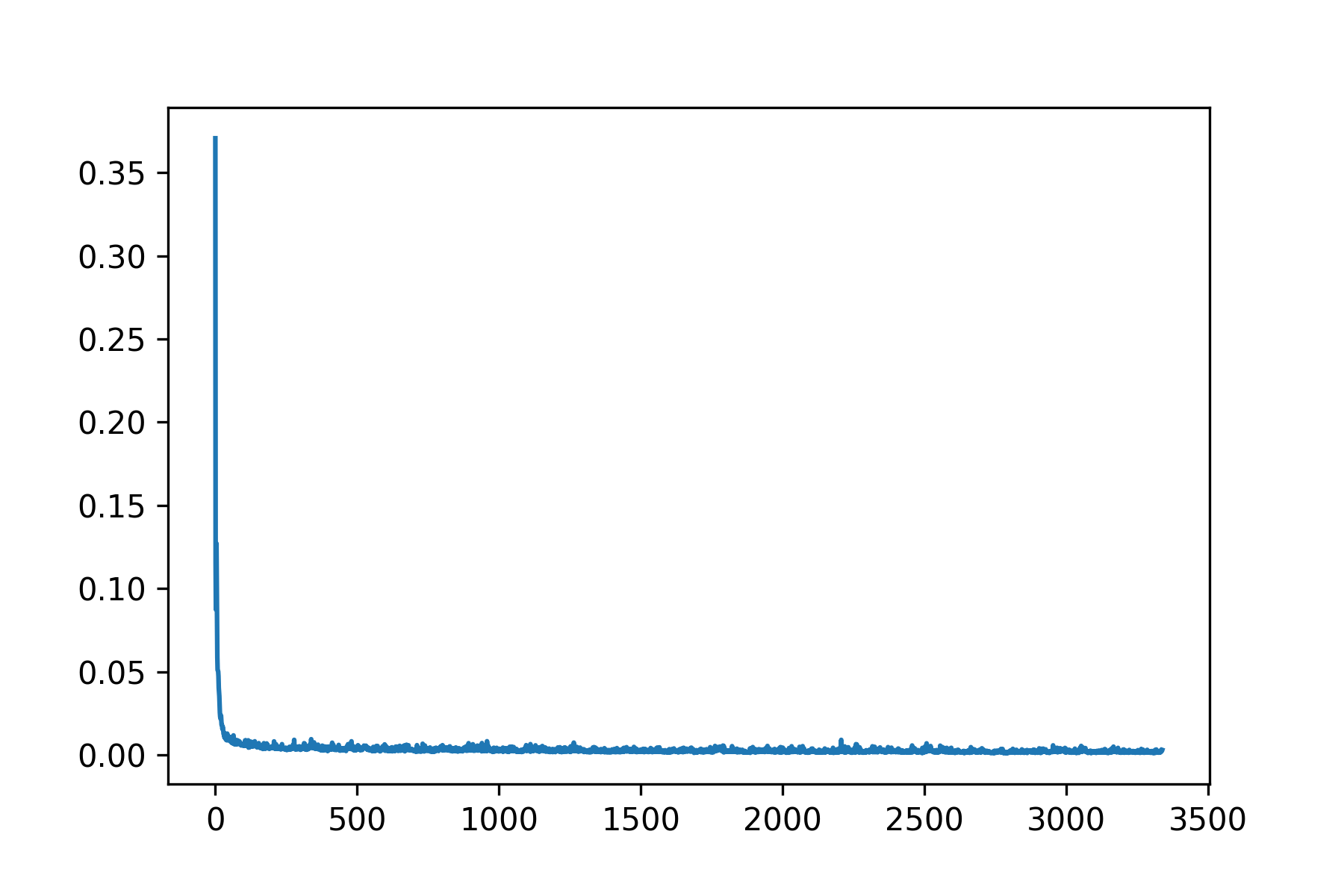
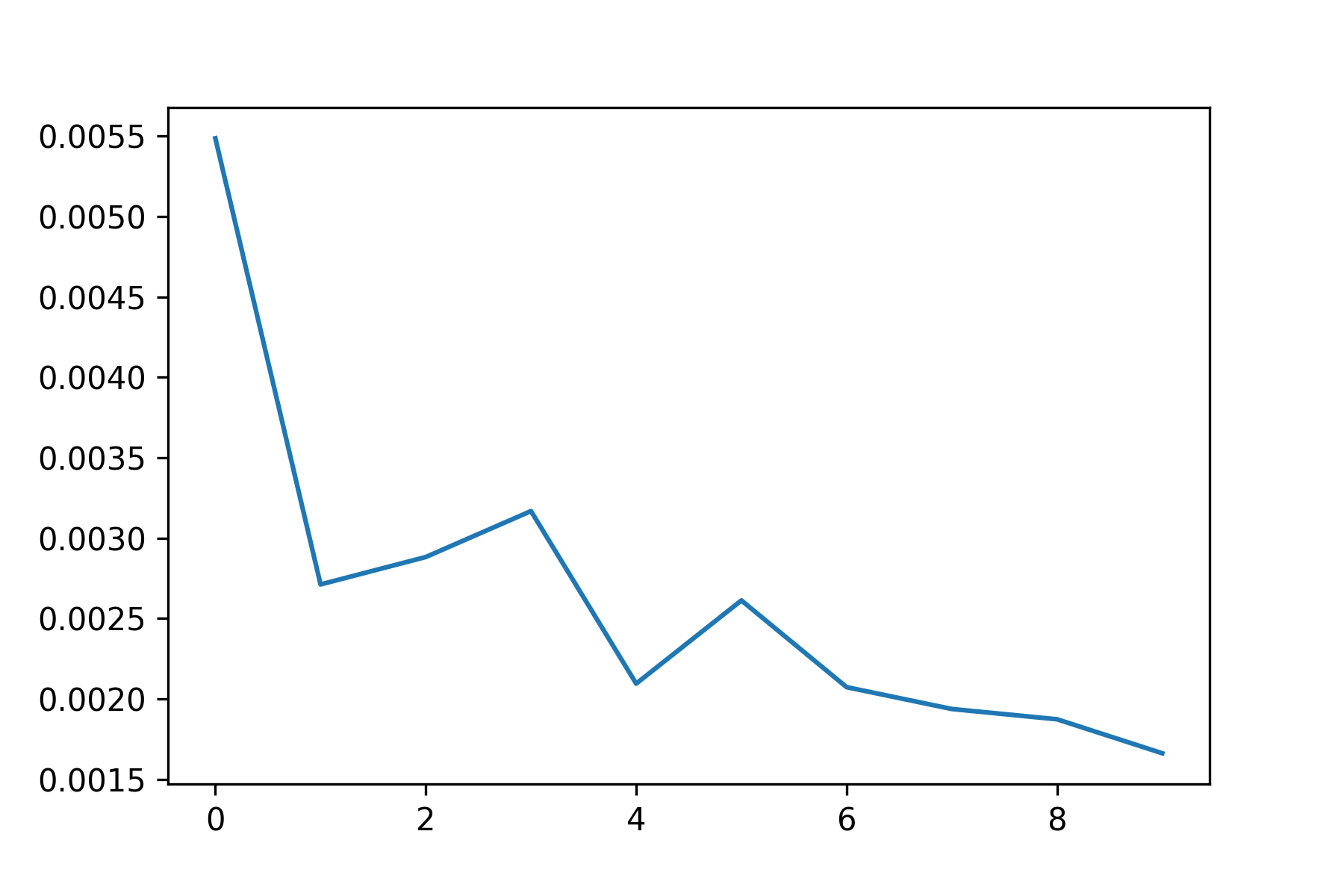
Since this was a simpler task, a fairly small neural network was used without data augmentation. It performs decently, but because the nose keypoint is located just under the nose, it has some issues guessing the nose when person is not facing the camera.
With a more complex task, this network was made to be a bit larger. When implementing online data augmentation, I believe that vertical flips had some issues with obtaining good validation accuracy. When that transformation was applied, it tended to guess most points to be around the eyes rather than correctly placing landmarks around the face. I think this was due to the network not learning the features well and preferring to output an average of the training set. While training, I attempted to lower the batch size, so that the network could generalize better. Without applying this transformation, better results were seen, though it still had issues when the person was not facing the camera.
Training this network was difficult because of how long it took to train. I attempted to lower the learning rate and decrease the batch size for better performance. Other data augmentation techniques were also applied except for flips. Flips caused the output to be completely off, so they were ignored.