Nose Tip Detection
Nose Tip Detection
In this project, I am going to train a neural network for facial keypoints recogniton. Part 1 is the nose tip point detection. We are usiing a data set that has a total of 40 people, each people has 6 images with different poses and different camea direction. We are doing the nose tip detection for this part. For the data_loader, my implementation is that we load all of the images and keypoints into the data set first. We are 80% of the data as the training set and the rest as validation set. Then, we do the data transform, which I overwrite some of the functions from torch.transform, and apply the transformation including normalization, resizeing to the iamges. For the net information, I choose to have 3 layers, and two fc functions, as shown in the figure below. I have also included the image with ground truth points, traiining and validation loss, as well as two good and two bad results. The possible reason for having bad results, I think is due to the data set is not large enough. Hence, whenever the person is not in the pose that is facing the camera, the overfitted point with no predict the correct location of the nose.

Net
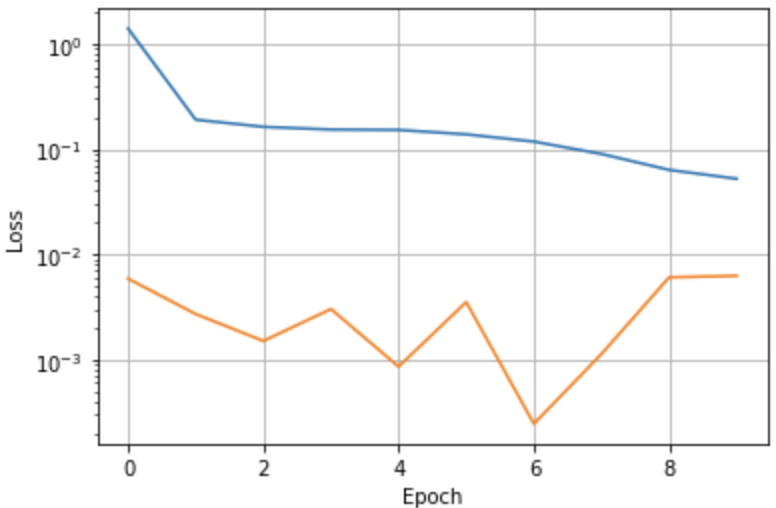
Traning and validation loss
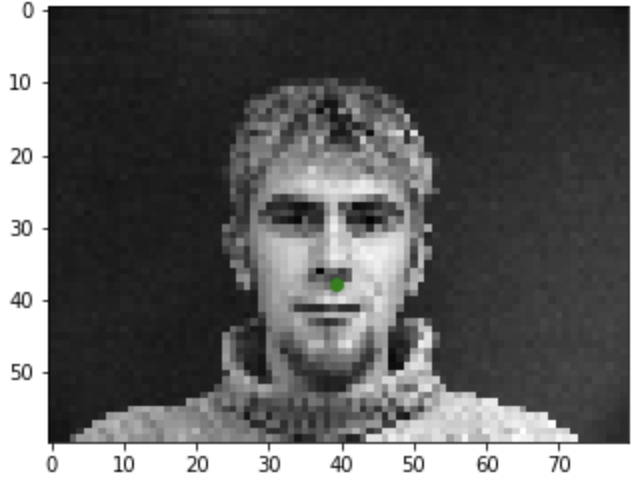
Ground Truth
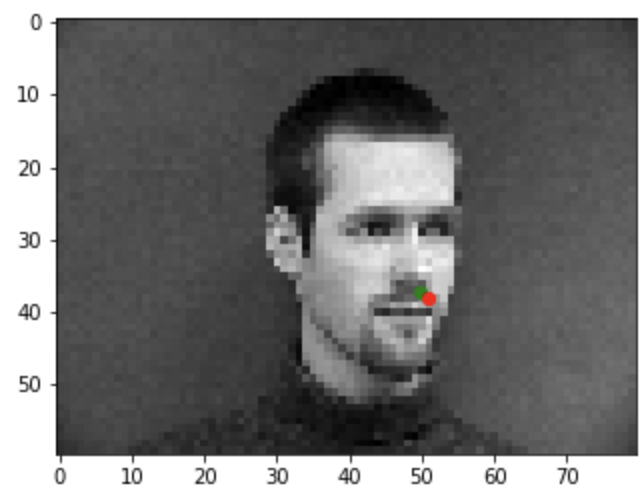
Good example1
Good example2
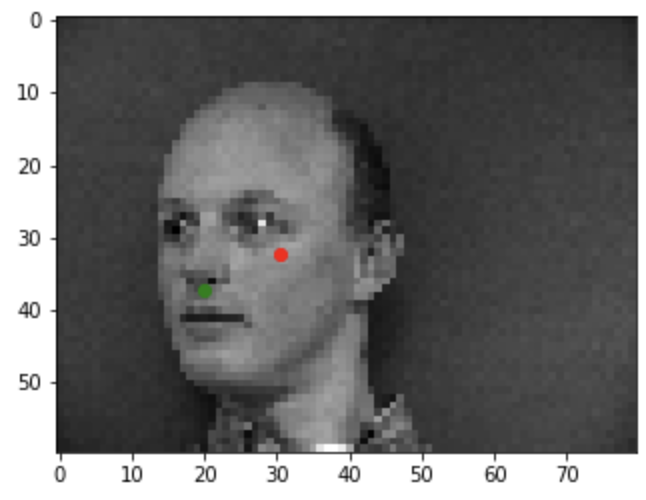
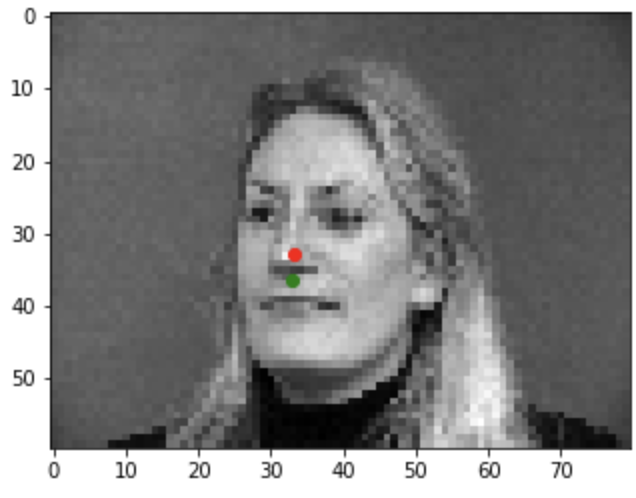
Bad example1
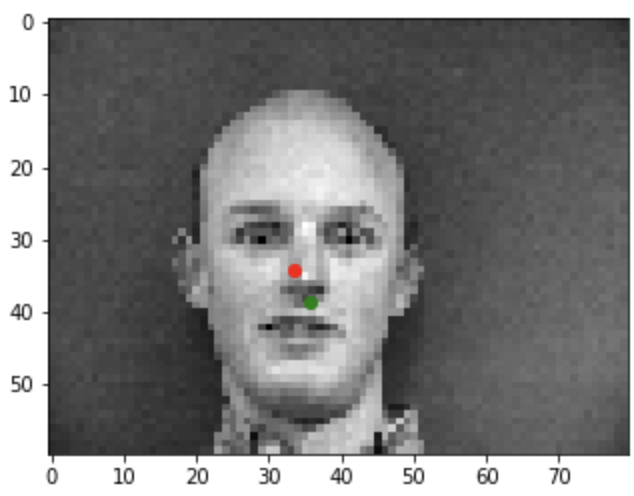
Bad example2
Full Facial Keypoints Detection
Here in this part, we are going to do the full facial keyponts detection. The data_loader is similar to last part, but the only dfference is that we include dat aagumentation this time. I include rotation as the augumentation. I randomly generate a degree of angle to rotation between -15 to 15, and apply the transformation to the image. Next, I use the rotation matrix to rotate the keypoints after centralizeds. The result of images after rotation with ground truth point is shown below. I have also create a new net for this part, with two more layers, as shown below in the figure. Similar as above, I provided two good and two bad examples. I belive thebad preidictation are still due to the fact that the data set is not large enough. So for poses that not facing directly to camera, the predicition is off by a little bit. Also, maybe adding more layers and changing the optimization function to, say signoid, or adding more augumentation might make the predicition better. Lastly, I also include the filters of my network, using code from https://colab.research.google.com/github/Niranjankumar-c/DeepLearning-PadhAI/blob/master/DeepLearning_Materials/6_VisualizationCNN_Pytorch/CNNVisualisation.ipynb

Net
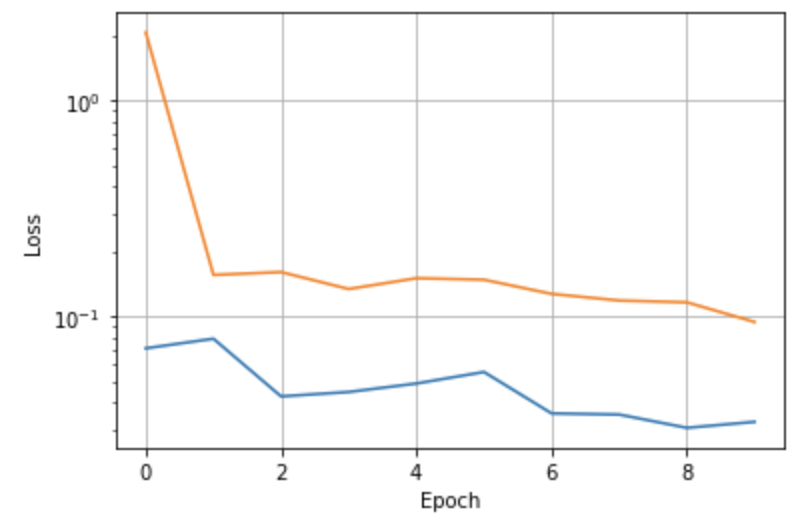
Traning loss and validation loss
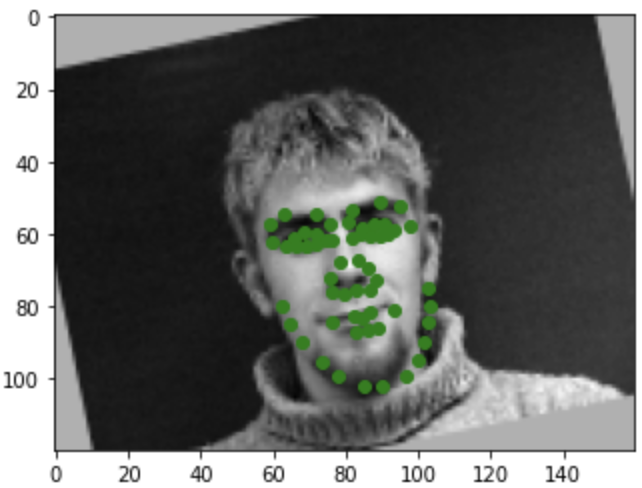
augumented face with ground truth points
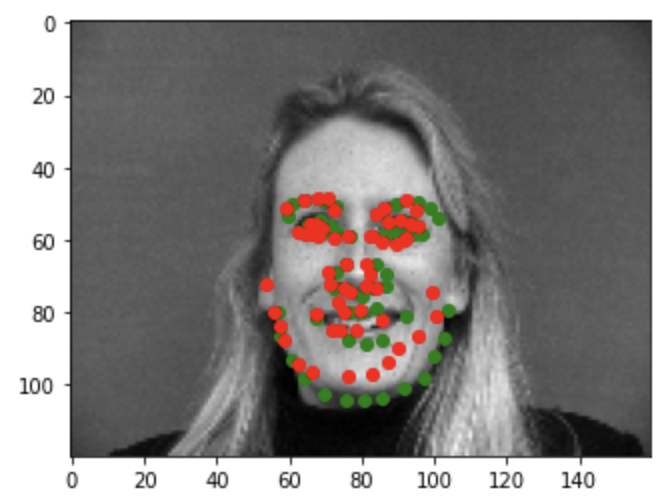
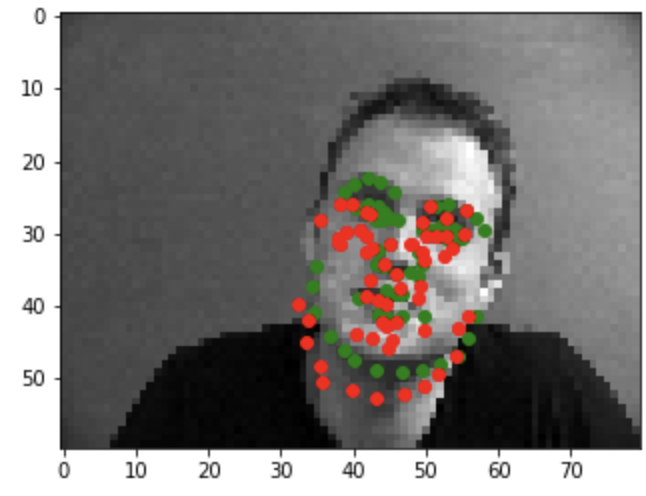
Good example1
Good example2
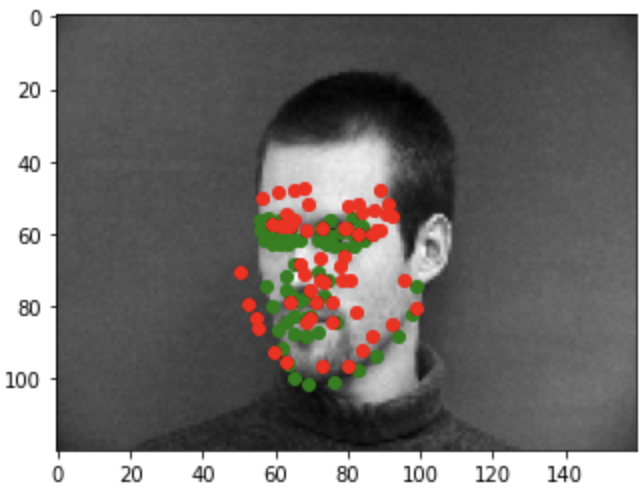
Bad example1
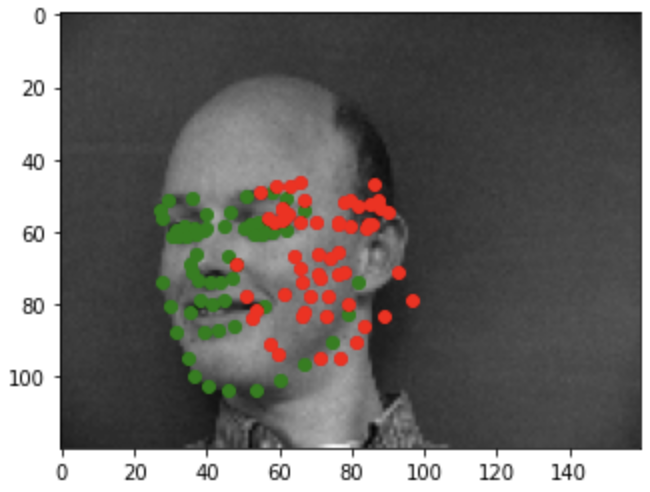
Bad example2
Filter weight 0

Filter weight 2

Filter weight 3
Train With Larger Dataset
For the last part, we are traning the model to predict facial keyponts with a large dataset. The net I am using is ResNet with parameter pretrain set to be true. The fc function is Linear(512, 136). For the convolution layer, I use Conv(1,64) with a kernal size of 7 x 7 and stride of 2. Like before, I use 80% of the data for training and the rest for validaton. Lastly, we have a test set with no facial points given. I show serveral images with predicated points below. Lastly, I have included some points of image of my selection.
Here is the link to my Kaggle:https://www.kaggle.com/c/cs194-26-fa20-proj4/submit
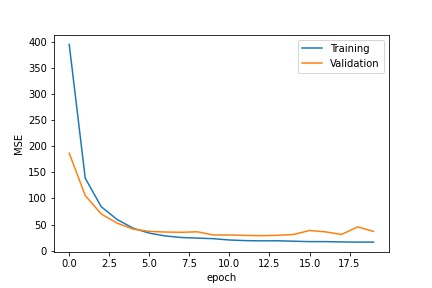
Training loss and validation loss

Net

First image from test set

Second image from test set

Thrid image from test set
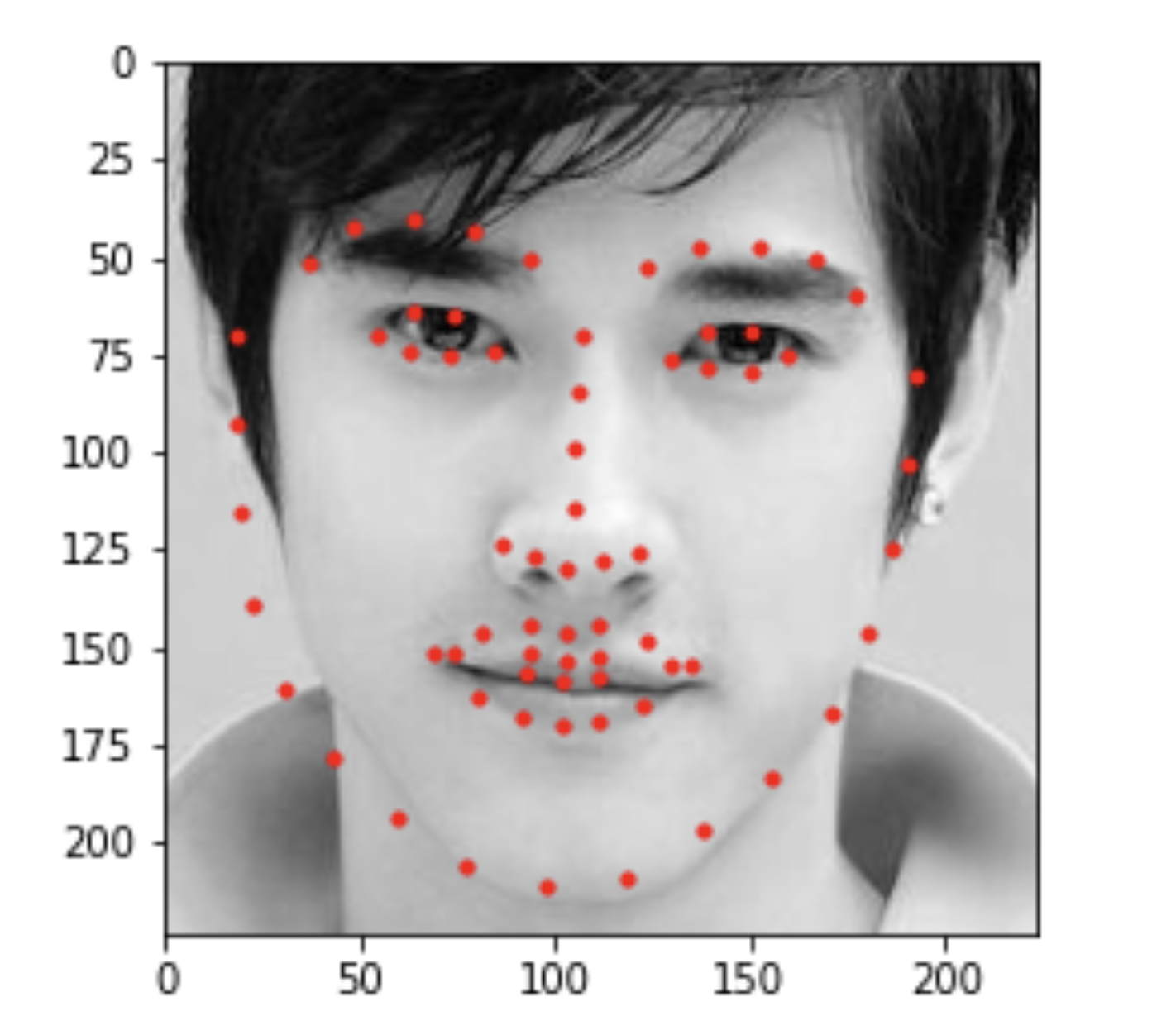
First image choosen by me
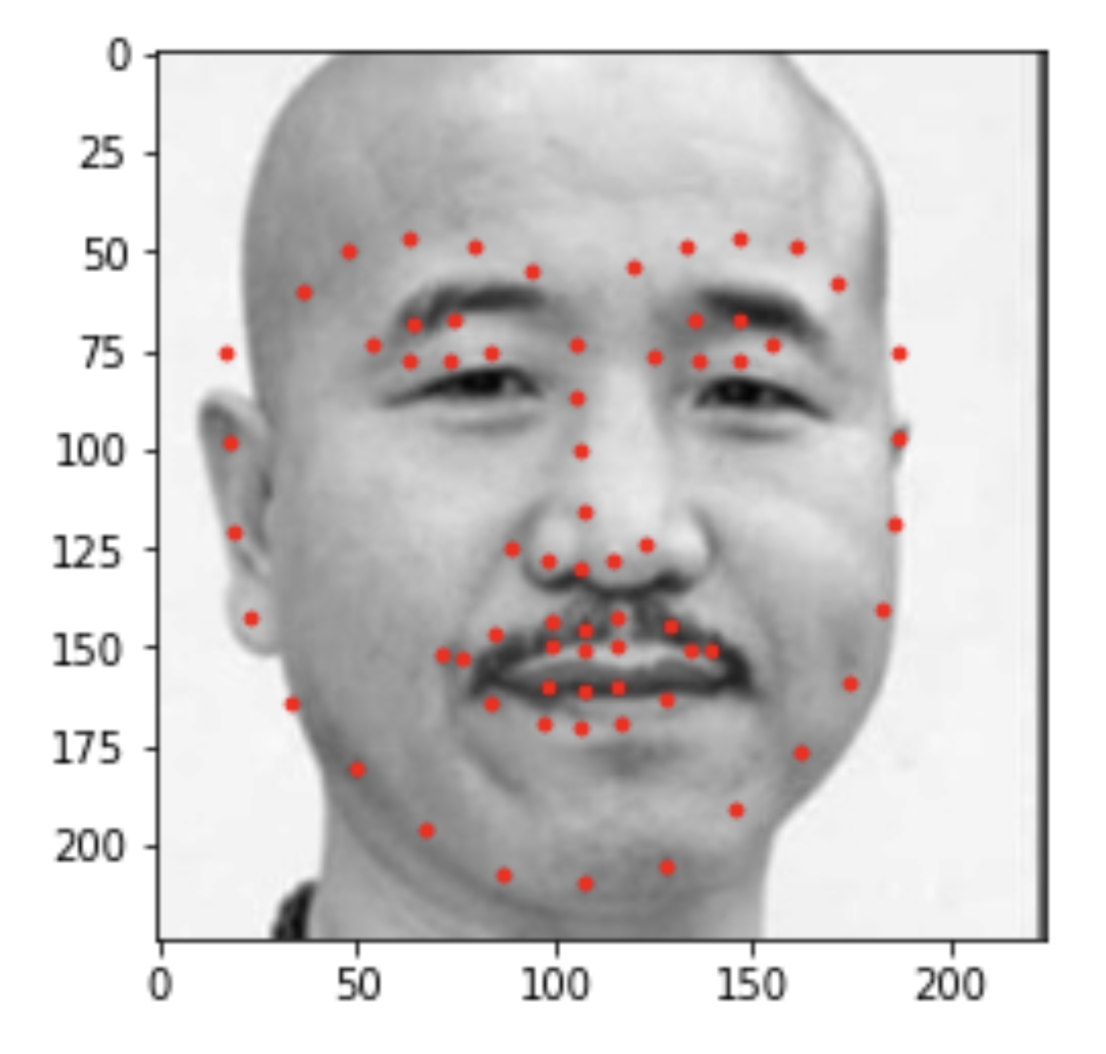
Second image choosen by me

Thrid image choosen by me