


Part 1. Nose Tip Detection
In part 1, I used 240 facial images of 40 persons from the IMM Face Database. Each person has 6 facial images in different viewpoints and facial expressions.

1

2

3

4

5

6
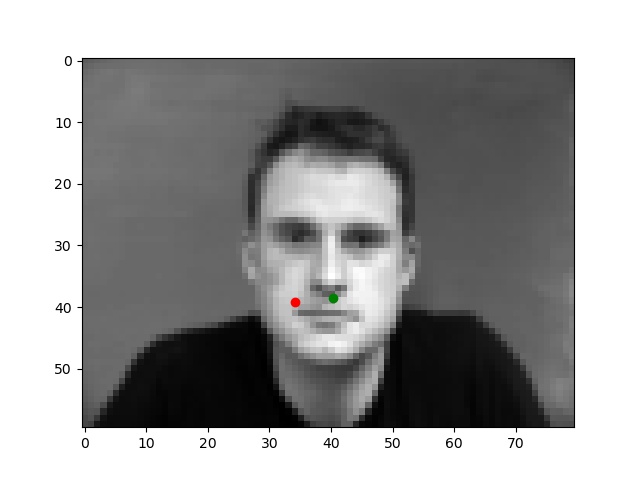
The task is to detect the coordinates of the nose tip from each facial images. Below is an example of facial image displayed along with nose tip ground-truth annotation from my training dataloader.

Each image is converted into grayscale and image pixel values are normalized float values in range -0.5 to 0.5. After that, images are resized into smaller size -> 80x60. I used (torch.nn.MSELoss) as the loss function, and Adam (torch.optim.Adam) as my optimizer, with a learning rate of 1e-3. Training loop is ran for 25 epochs.
I used a 3 layered Convolutional Neural Network. The loss during each epoch is shown below:



For almost all my failure cases, the persons in the image are either tilting their head towards the side, or making a strong facial expression. If not, the lighting is poor, resulting in obscuring shadows in the background. I believe those factors are interfering with my predictions.
-- success cases: successful predictions of nosetip --




-- failure cases: unsuccessful predictions of nosetip --



Part 2. Full Facial Keypoints Detection
For part 2, instead of trying to predict the coordinates of people's nosetips, the task is to predict the all 58 facial keypoints. The input images are resized to 160x120.
In order to prevent the model from overfitting, I applied data augmentation techniques: randomly rotating the train set images for -10 to 10 degrees, and randomly shifting the face for -10 to 10 pixels.
Same as part 1, loss function = (torch.nn.MSELoss), and optimizer = Adam (torch.optim.Adam), with a learning rate of 1e-3. I ran training loops for 25 epochs.
The architecture of the 5-layered Convolutional Neural Network and loss during each training epoch are visualized below:


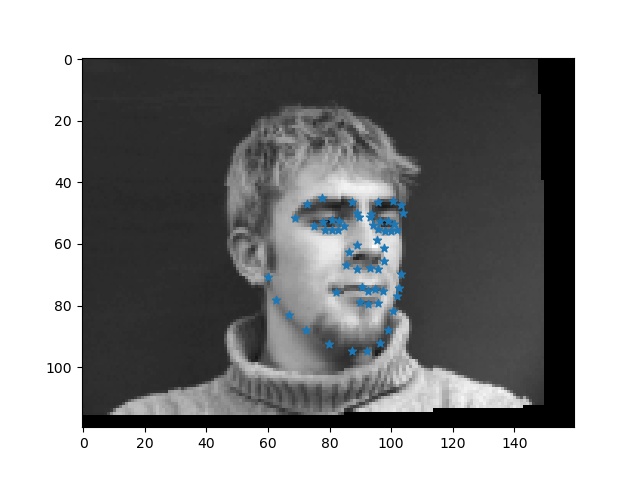
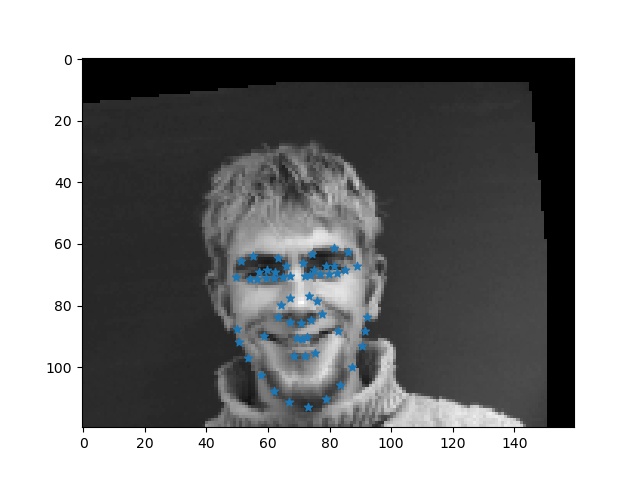
Below are a few successful and unsuccessful predictions. In general, I'm not satisfied with my results, and I think it is due to the fact that there are too many confounding factors in each image that disrupt the model, especially given that it is too small a dataset for such a prediction. For failure cases, the persons are mostly facing sideways.
-- success cases: successful predictions of facial keypoints --




-- failure cases: unsuccessful predictions of facial keypoints --



-- 1st convolutional layer filters visualized --













Part 3. Train with Larger Dataset
"During training, we need to crop the image and feed only the face portion. You need to use bounding boxes to do the image cropping. Resize the crop into 224x224, and remember to update the keypoints coordinate as well.
-- samples from the train dataloader: applied with data-augmentation techniques --

.png)
.png)
.png)
This dataset contains 6666 images of varying image sizes, and each image has 68 annotated facial keypoints.
My loss function for part 3 is also (torch.nn.MSELoss), and optimizer = Adam (torch.optim.Adam), with a learning rate of 1e-3. I ran training loops for 10 epochs because it is extremely slow to process 1 loop even using GPU.
I used ResNet18 as my CNN structure, with some parameter modifications:




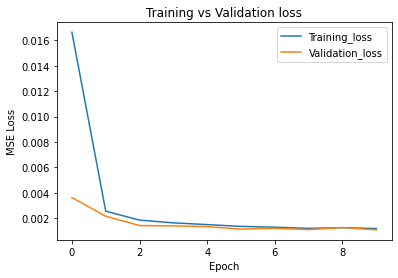
The loss of running on training dataloader and validation loader during each epoch is:
After the training session, here are a few examples of facial keypoints predictions from the test set using the trained net:





Also some predictions from my own photo collection. The predictions are not ideal, probably because of resolution / cropping issues.


