|
|

|

|

|

|
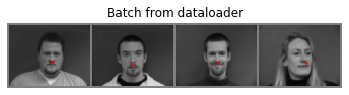
This project attempts to detect facial keypoints on images with faces within them through Convolutional Neural Networks created through PyTorch.
To start off the project, I created a toy neural network model to detect nose points. After reading in the images and keypoints, I normalized both the image brightness and landmark coordinated to be within -0.5 to 0.5. This CNN contains 3 convolutional layers with 2 fully connected ones, with channel size 12, 14, and 32 respectively using filters of size 3. The fully connected layers take in inputs 1280 and 120 respectively, outputting 2 points in the final fully connected layer to represent the coordinates of the nose. For each following image, blue = Ground Truth, red = predicted
|
|
|
|
|
|
|
|
|
Most of the failures involved faces that were turned around. It's likely that, with such a small training set, the model almost immediately overfit to the training data, resulting in a gross disparity between training and validation error.
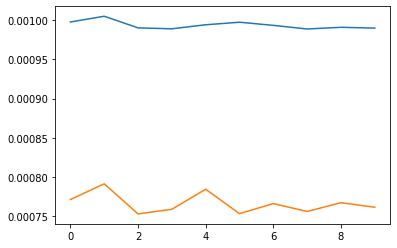
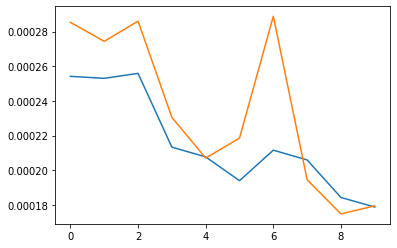
We now expand our CNN to accomodate 58 landmarks. Since our original dataset is rather small, data augmentation including rotation and shifting were applied, along with the usual normalization of points and brightnesses. The architecture was modified to accomodate 5 convolutional layers, of channel size 4, 8, 16, 24, and 32 respectively. Filter sizes of 3 were used for each. 3 fully connected layers were used in the CNN, with inputs 480, 256, and 256 respectively. The final FC layer outputted 116 data points, representing 58 landmarks. RELUs and max pooling were applied after each convolutional layer, applying only RELUs to the fully connected layers. Finally, a batch size of 4 with learning rate 0.001 was used to train the model for 10 epochs.

|
|

|

|

|

|
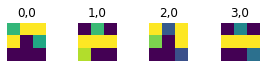
|
The first failed approximation may have been due to smaller, skinnier face of the man. Most of the training set individuals have rather fuller faces, and the model was not able to generalize to this individual's facial structure. The second failed approximation may have been due to large smile of the woman; most of the training set includes closed lip smiles, and the presence of teeth and prominent face creases from the smile would have thrown off the model.
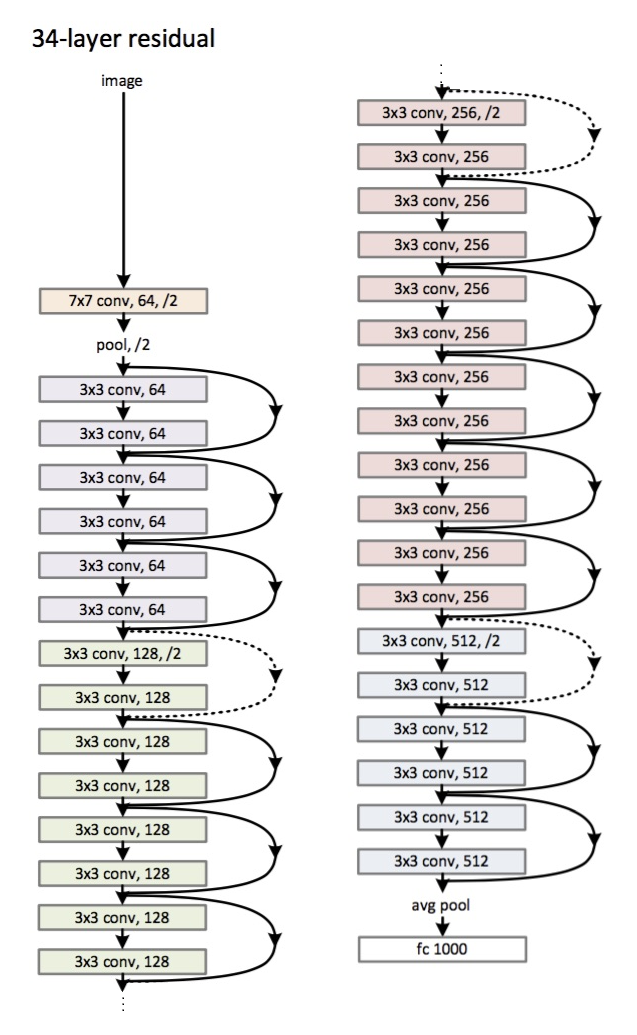
Finally, we pull out the big guns; equipped with a larger dataset, I used a modified version ResNet50 with pretrained weights as my model. The modifications included changing the first convolutional layer's input size to 1 due to the images being grayscale, and changing the last fully connected layers output to 136 to output the 58 coordinates. The architecture for Resnet50 is shown below, which remains mostly untouched aside from the above changes.
|
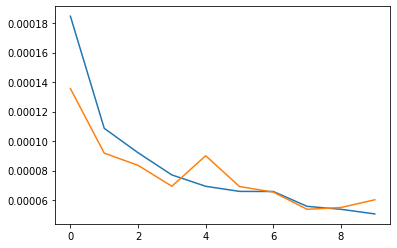
As for hyperparameters, a batch size of 16 with learning rate .001 was used to train the model on 50 epochs.

|
|
|
|

|

|
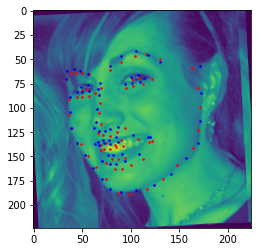
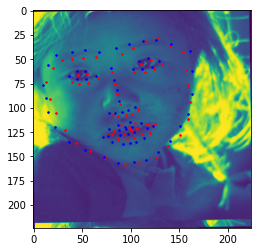
The model reports an MSE of 9.90286 under Michael Wang #2. The model fails on the last example most likely due to the man's facial hair. The black color of his facial hair most likely isn't being considered as part of his face due to a lack of training data on men with facial hair and instead as something else, leading to the chin area being truncated. The man's cigar also deforms the typical facial structure as well, once again making it difficult for the model to generalize to this case as there is little data on faces with accessories.

|

|

|
The results from my model don't seem to generalize well to new pictures, despite a decent score on the MSE. I suspect this may be due to my code not being well setup for data not directly in the format of the given dataset (i.e. loose images), resulting in some bugs with respect to scaling and morphing the landmarks with respect to the full image, or that the images were not properly cropped to show only the head, and thus the extraneous information threw off the model.