Sample ground truth nose keypoint images:




These keypoints were correctly predicted.


These keypoints were incorrect. These points seemed to be the average nose keypoint among all the training images, meaning that this neural net in general was not very good at predicting nose keypoints at different head positions.
It probably failed because the weights are so small for some reason, causing less of a shift in prediction when images are even slightly different. It defaults to the average keypoint.


The training loss shows decline as expected.

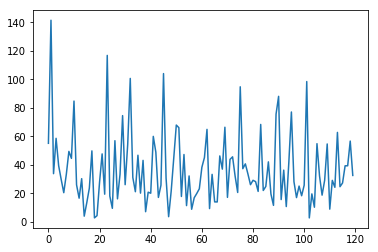
The validation loss is all over the place, and spikes are much higher in error than expected. This model suffers from the issues stated in the previous section.
My CNN model for this part consisted of 5 convolution layers, each increasing in the number of channels up to 128, and each followed by a ReLU and a max pool. Finally 2 FC layers, the first of which is followed by an ReLU.
I used one augmentation method of random rotation, in which I rotated each image by a random degree from -15 to 15. I also rotated the landmarks/keypoints as well by the same degree around the point at the center of the image, or (0.5, 0.5) relative to the non-scaled keypoints.



This network prediction fails in a similar manner to the first part. It looked like the variation in the points across different faces and images in the test set was miniscule, suggesting that the weights are again small enough to not make a major difference.
In all the time spent debugging my training, tuning the hyperparameters, and recreating the network and datasets, dataloaders, etc from scratch, I could not figure out why the points were being trained to default to the average face.
Even with data augmentation, the face did not seem to want to shift based on different images.


The training loss shows a good decline, but the MSE loss itself hovers around 0.01-0.02, which is not low enough for the un-scaled keypoints.

This is the validation loss with the test set after every batch trained. It hovers around the same values of 0.001 to 0.013. It only improved after the first epoch, and converged to a mediocre loss value for every epoch after.

For training, I used a batch size of 5 and a small learning rate of 0.001 to prevent divergence. I also used a smooth L1 loss criterion instead of the MSE loss I used in previous parts.
I also split the training data into 6000 images for training, and 666 images for validation, although it didn't mean anything because I didn't use validation loss to tune the weights; it was only for visualization.
My mean absolute error in the Kaggle competition turned out to be 24.56857. Either my model wasn't trained enough on the existing training data, or it was trained too much to fit the average value, like previous parts showed, and like the model predicted for a lot of the test data (and even training data). The changes for each point between different images was too small to properly match the ground truth points fully.
Cropped + resized/scaled to 224x224




As per the spec, I inputted 224x224 rescaled test data into the model, and scaled back the points returned as outputs from the model into the original image's position + dimensions.




Training loss over one epoch of the 6000 images in the training split.
