report
CS194-26 Project 4
Part 1: Nose Tip Detection
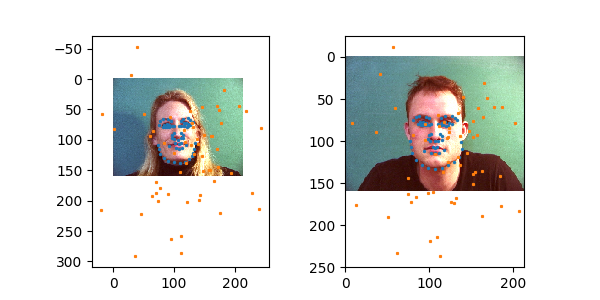
First we parse the IMM dataset to get keypoints and images. Here is a sample taken from my DataLoader:

My model looked like the following
| Layer | size |
|---|---|
| Conv | 24 * 3x3 |
| Max pool | 2x2 |
| Conv | 6 * 3x3 |
| Max pool | 2x2 |
| FC | 80 -> 50 |
| FC | 50 -> 2 |
Using MSE loss.
Training worked well: This is what my losses looked like (blue are validaton, orange are training)
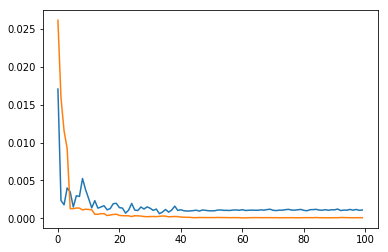
Here are some samples of correct classifications:

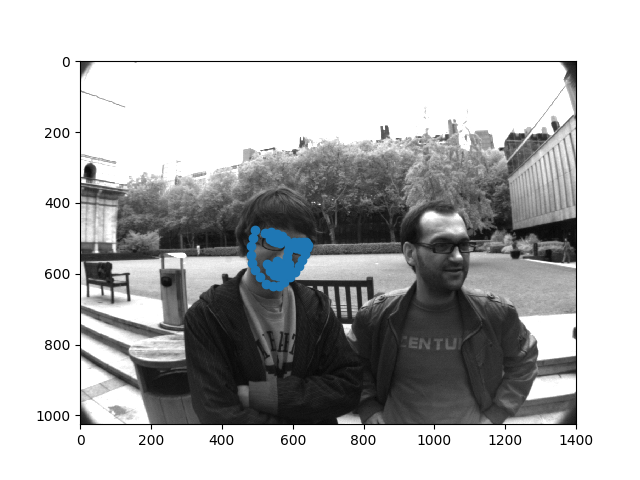
We see the lighting on the face is very uniform and the nose feature is very pronounced. Here are some failures:

Here the lighting is varied and the faces are turned, resulting in higher errors.
Part 2: Full facial keypoint detection
Here we implement some image augmentations including color jitter and rotations after a resize to 160x240. My data loader by default outputs points centered around 0 so we compute a 2d rotation matrix, apply the rotation to the image as well as multiply the points matrix by the computed rotation matrix:
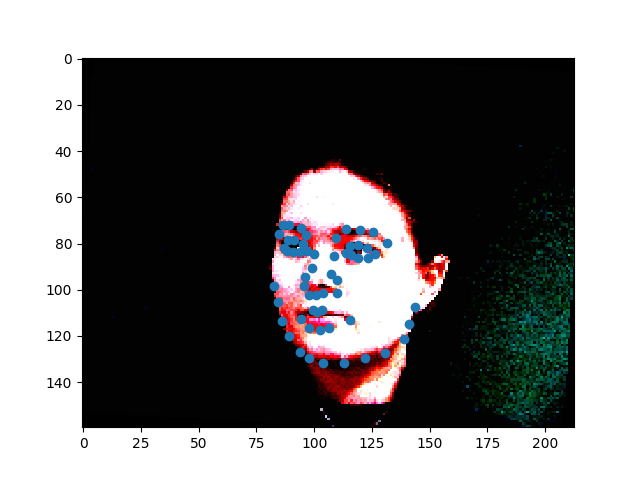
For my model here I essentially copied VGG-11
| Layer | size |
|---|---|
| Conv | 64 * 3x3 |
| Max pool | 2x2 |
| Conv | 128 * 3x3 |
| Max pool | 2x2 |
| Conv | 256 * 3x3 |
| Conv | 256 * 3x3 |
| Max pool | 2x2 |
| Conv | 512 * 3x3 |
| Conv | 512 * 3x3 |
| Max pool | 2x2 |
| Conv | 512 * 3x3 |
| Conv | 512 * 3x3 |
| Max pool | 2x2 |
| Adaptive avg pool | 7x7 |
| FC w/dropout | 512 * 7 * 7 -> 2048 |
| FC w/dropout | 2048 -> 2048 |
| FC | 2048 -> 58 * 2 |
Where each convolutional layer has a 2d batch norm layer applied after it
I used a learning rate of 0.001 and a batch size of 4
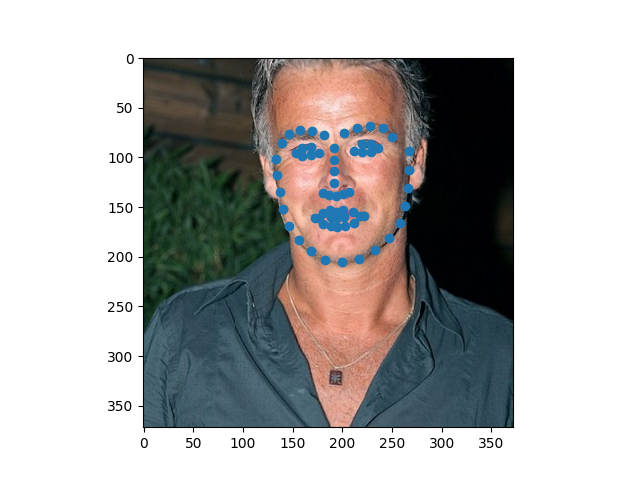
The model did reasonably, given how hard it is to classify something like this:
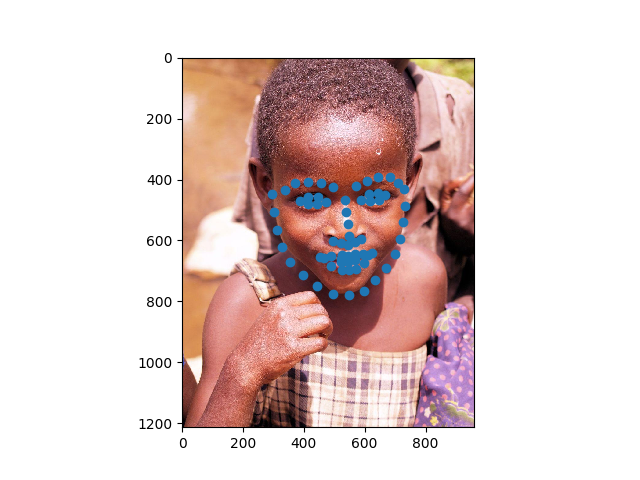
It did have some it seems like it just totally gave up on though:
Here is a visualization of some of the filters we get.
At the first layer:
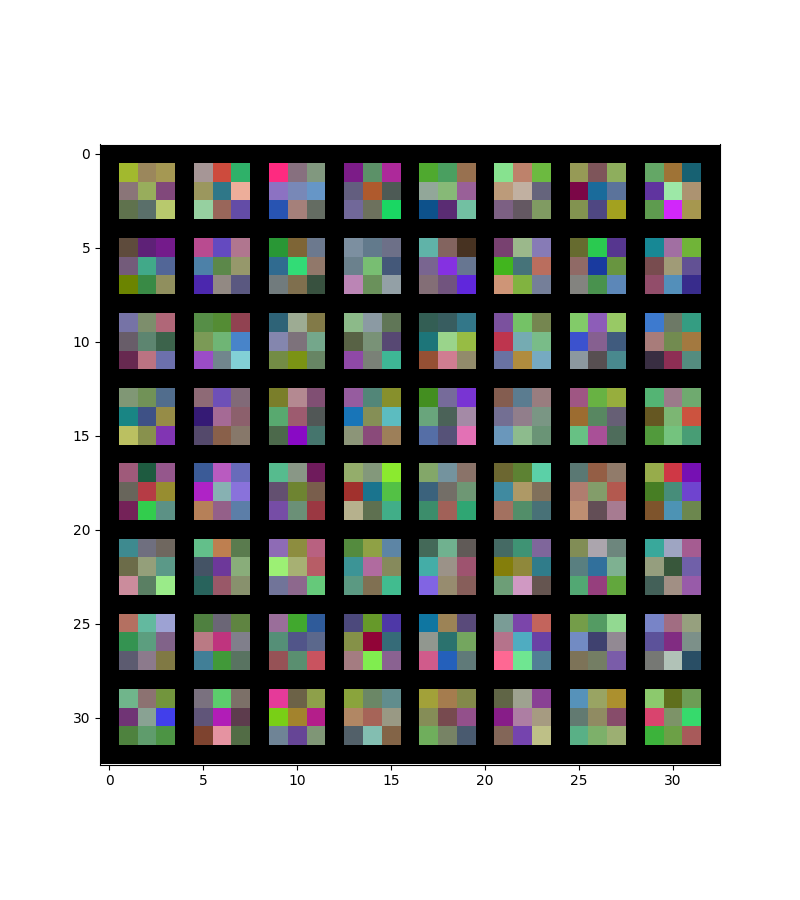
At the second layer:

At the thirdlayer:

Part 3: The IBUG dataset
The dataloader for the Ibug dataset was slighly more complicated to write. First I center cropped each image to be square in a way that would capture the whole face. Sometimes this meant dilating the box and other times it meant cropping it down more to maintain a square frame. The images were then resized to 224x224, normalized, jittered, and rotated to get the desired effect.
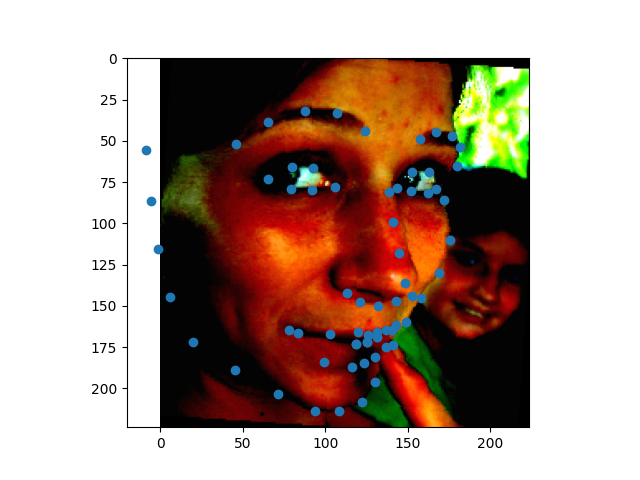
Seeing as these faces were far more complex, I decided to try some preprocessing to make the faces easier to predict.
The first thing apparent about these keypoints is that individual keypoints are highly correlated. This gave me the impression that we really don’t need to predict 68 * 2 individual points to predict the face.
Seeing as PCA worked well with faces previously, I thought I would try it on the facial keypoints here.
I normalized all the faces from my dataloader and computed PCA on all the faces in the training set:
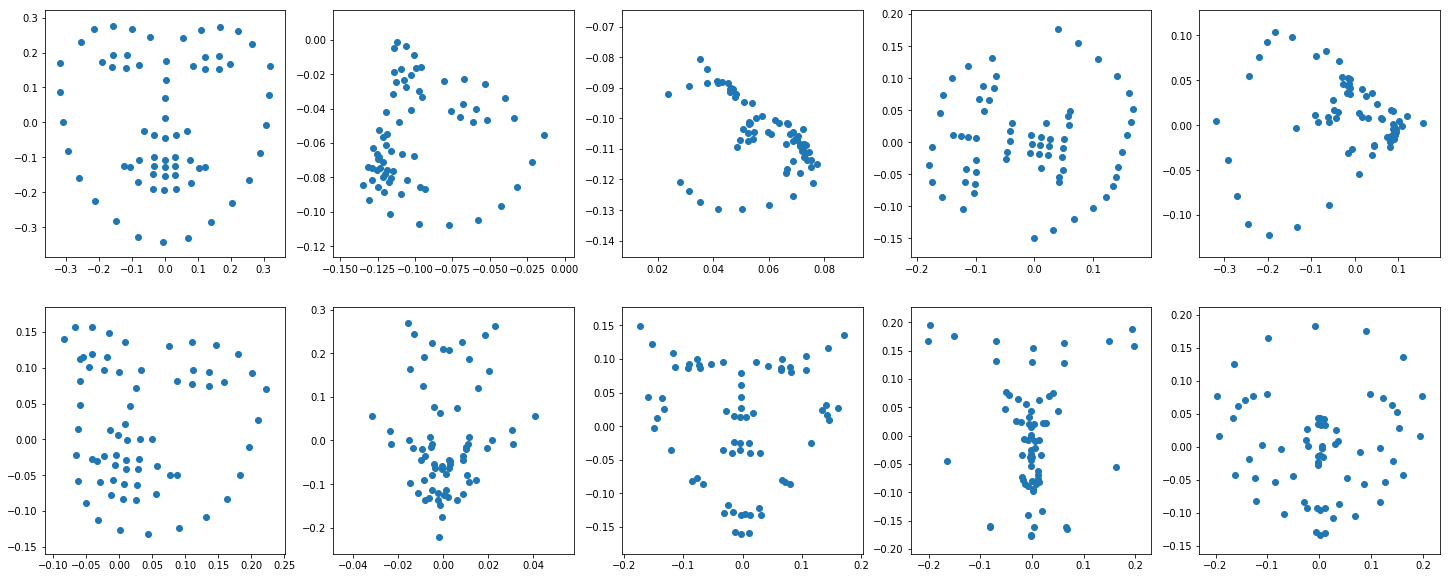
Overall some of them seem reasonable and others less good, but still alright. Now, instead of predicting the overall faces we can predict weights of these PCA’d faces. For example, here would be a weight of -1 on the first principal component:

I experimented with a wide range of models and found that a lot of the time it had difficulty with faces off center or rotated as here:
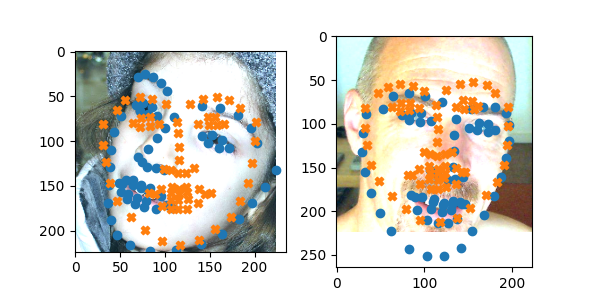
And worked very well for more rigid faces:
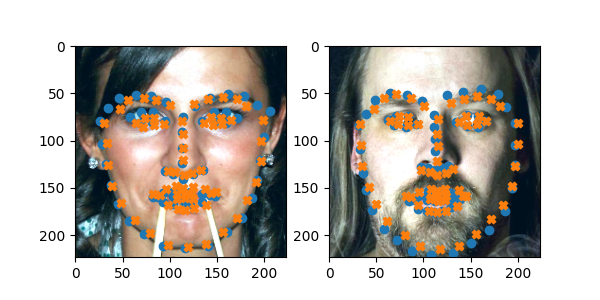
So I realized that the PCA’d faces (because they’re all centered) wouldn’t be able to do a good job of translating properly and might do alright with rotations but it wouldn’t be perfect, so I also added 6 additional parameters in which the neural net learned an affine transformation and truncated the principal components to make it easier to learn:
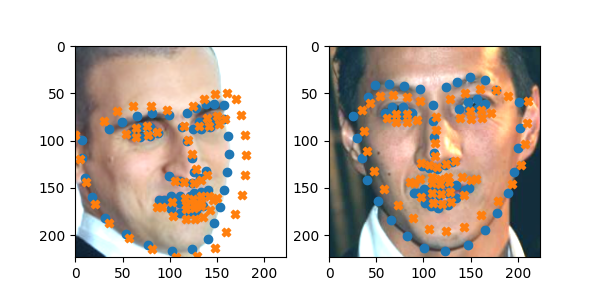
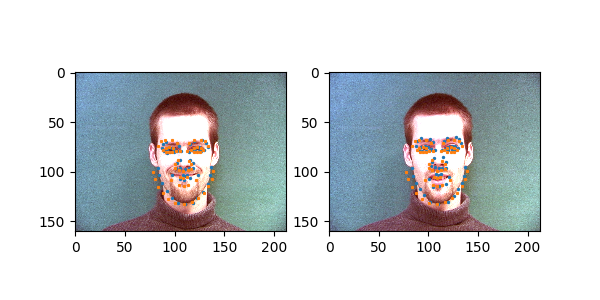
Here is the model run on some images in the testing set:
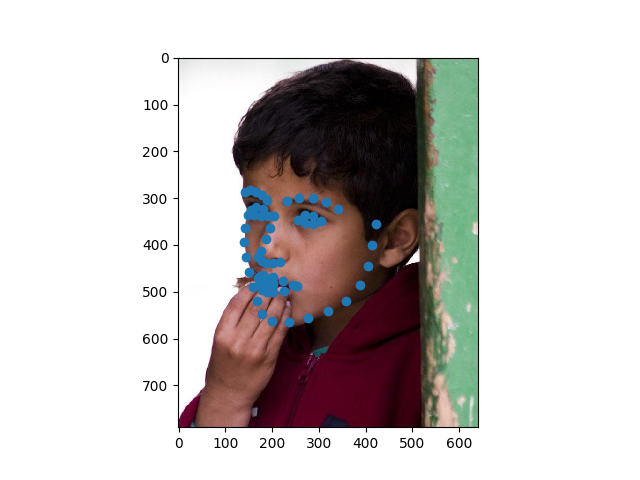

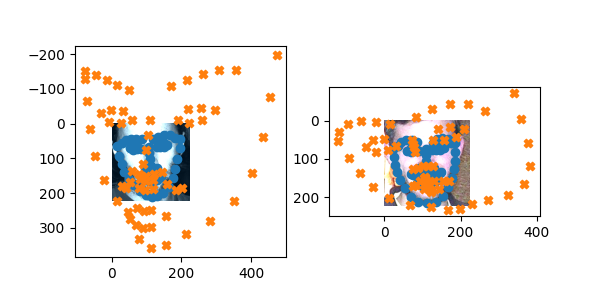
This did insanely poorly on some images though, and I’m not really sure why. Could be something about their backgrounds or the face structure.
The mean overall error I got for this was 8.67166 as it is on kaggle.
Here is a full description of the model, inspired by VGG with some experimentation:
| Layer | size |
|---|---|
| Conv | 64 * 3x3 |
| Max pool | 2x2 |
| Conv | 128 * 3x3 |
| Max pool | 2x2 |
| Conv | 256 * 3x3 |
| Conv | 256 * 3x3 |
| Conv | 256 * 3x3 |
| Conv | 256 * 3x3 |
| Max pool | 2x2 |
| Conv | 512 * 3x3 |
| Conv | 512 * 3x3 |
| Conv | 512 * 3x3 |
| Conv | 512 * 3x3 |
| Max pool | 2x2 |
| Conv | 128 * 3x3 |
| Conv | 128 * 3x3 |
| Conv | 128 * 3x3 |
| Conv | 128 * 3x3 |
| FC w/dropout | 128 * 14 * 14 -> 4096 |
| FC w/dropout | 4096 -> 4096 |
| FC | 4096 -> 25 + 6 |
| PCA weighting | 25 for pca components, 6 for affine matrix -> 68 * 2 |
I experimented with both L1 and L2 loss and found that L1 loss produced better images, likely because it interprets distances uniformly rather than not trying to minimize small distances.
I used ReduceLROnPlateau with a patience of 5 and an initial learning rate of 0.0001 with the Adam Optimizer for 200 epochs.
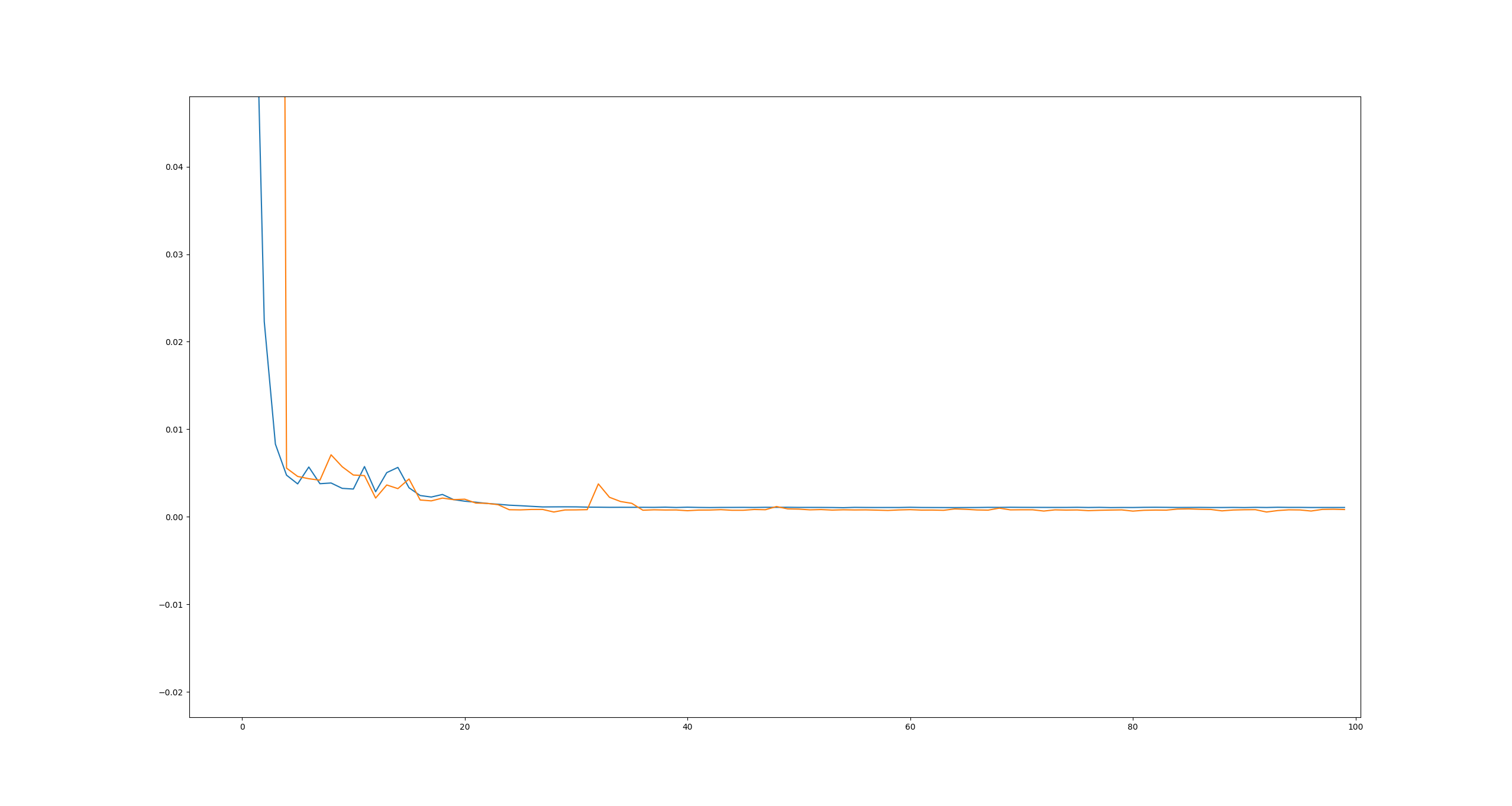
Here are the loss curves I got (ignoring the first couple):
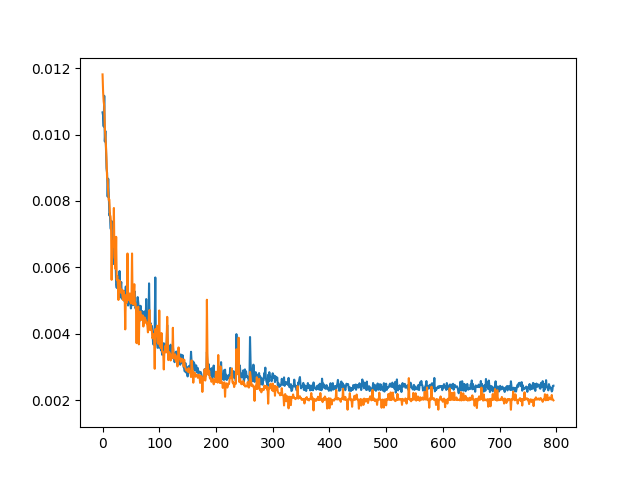
I think it’s pretty clear it could benefit from a bit more regularization but does ok as is.
Bell/Whistle: Antialiased Max Pool
I modified the code I wrote using Richard’s modification of the VGG networks here, using his default filter_size of 4.
I only had the time to run this for 20 epochs, so I compared it against the previous model run for 20 epochs to be fair. The previous model scored 15.61192. The results were mixed on my first try. Using the same exact structure as before, I got a kaggle result of 17.80536, worse than that before, with an extremely similar learning curve to the previous. With high and low error cases looking similar, with low error being in nice lighting conditions and high error being in not so ideal conditions.
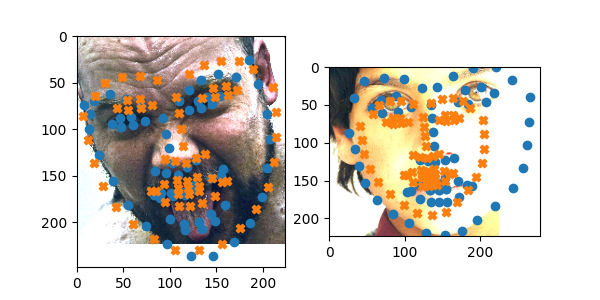
It looks like the model had trouble with the half occluded face and, although it was able to fit the chin and side of the face on the left it could not adjust the eyes, mouth, and nose.
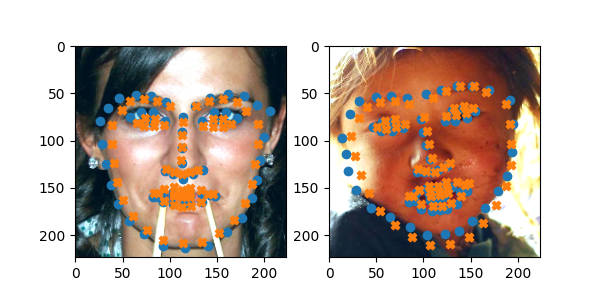
As with before I think I just need more training time to trim down the loss.
Things to try with more time
- Training the antialiasing network properly
- New idea for the PCA Stuff: It appears that in the face left face in the first image above, the model fits the chin very well but has a difficult time fitting the nose, eyes, and mouth. This is likely due to the PCA components not being able to express this particular structure (or having a complicated projection space for it). One solution to this would be to learn independently pca components for the chin, eyes, nose and mouth as well as affine transforms for each of these. This would likely result in a more expressive output space and could very well yield a more accurate model.