Using cv2, I downscale the images down to 80x60. The neural network is a small network specified in the following pseudocode:

Here is a sampled image (the first one).

I ran the training loop with Adam optimizer with lr=1e-3, and for 25 epochs on colab. The results for 2 correct and 2 incorrect detections are as follows:
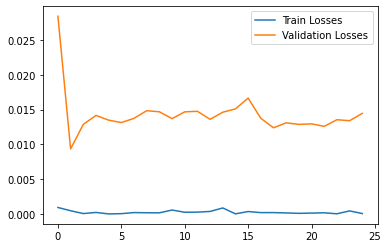




I think it is a bit inaccurate for the first case due to lack of shadow to find the nose. Similarly in the third case, the heavy shadow near the ear leads the network to think that it is the nose.
Quite a few papers have shown that rotations aren't as good as translate, and simple ones (namely cutout and random crop/translate) work just as well. Implemented is a random translate, with the face moving horizontally between -25 and 25 pixels, and vertically -25 and 13 pixels. This is so the keypoints will always be in frame, but still translate as much as possible.
Here's a sampled translate on the first face again. The keypoints are also translated to match the annotation properly.

The architecture is as detailed below. Visualized are the filters right after the first set of convolutions, which we will see later, that pay attention to important parts of the image.

I train for 50 epochs, with a chosen learning rate in [1e-3, 5e-4, 1e-4] that performs best. 1e-3 seemed to work best.
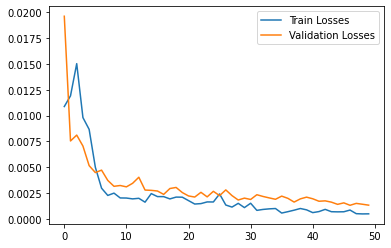
Again from the validation set, here are some samples, 2 that worked and 2 that didn't.




I would guess that the second two didn't work simply because the features are hard to extract for cramping the eyes so much together. As for the second one, it is likely that the convs couldn't have enough expressive power to extract edges.
Here are some visualized filters. They pay attention to things such as the shoulder position, the eyebrows, and hairline.


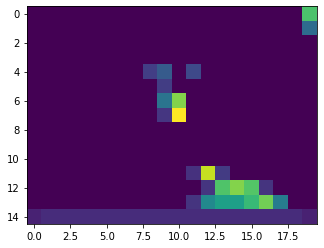
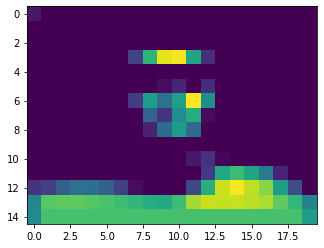
It seems that the location is a little too downsized, so a better architecture would use less filters, and larger filter sizes, to maintain xy spatial awareness in the network.
As mentioned before, the filters are too small, so stuff like edges are too hard to detect, which would lead to difficulty properly annotating stuff like the jawline, rather than guessing based off of the location of the face, which is indeed detected.