
CS194-26 FACIAL KEYPOINT DETECTION
Chendi Wu
Chendi Wu
The goal of this project is to automatically detect facial keypoints that define important features on a human portrait. A Convolutional Neural Network (CNN) is considered a good model that automatically learns key features from input images and achieves the goal of this project. All code in this project is written in Pytorch.
We start with training a model on one point, the nose tip, to examine our method and model architecture. A custom dataset "keyPointsDataSet" is defined to read and store all images and respective landmarks. Then the dataset is split into a training set with 80% of the population and a validation set with 20% of the population. Both datasets are resized to 80x60, converted to greyscale images and normalized to a range of [0, 1]. Last, two dataloaders are created from these two datasets, which will feed the inputs into the model in batches. Hereby, I used a batch size of 4.
Here are some results of loading data from each dataloader:

|

|

|
In order to predict the nose tip point, I trained a neural network with three convolution layers, with parameters (1, 12, 7), (12, 24, 5), (24, 32, 3). Each convolution layer is followed by a ReLu layer and a maxpool layer with parameter 2. Lastly, I used two fully connected layers with parameters (32*4*7, 240) and (240, 2), where 2 indicates we're expecting 2 outputs, the predicted x and y coordinates of the nose tip.
The neural network is trained over 25 epochs, with the training and validation loss shown below:
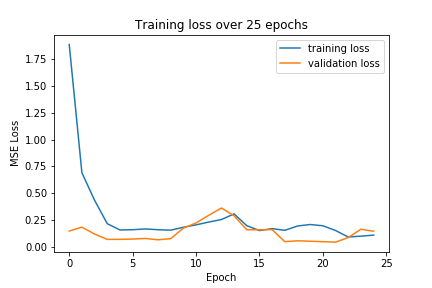
|
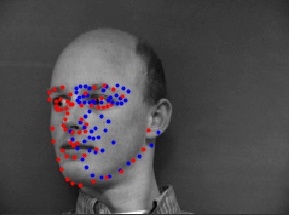
Here are some prediction results (blue points). For comparison, the ground-truth points are plotted as red points. The first row are successful predictions, whereas the second row are failure cases. The reason for these failure cases may be that most images in the training set are forward-facing and with a stern look, so the model learn these features well and is better at predicting forward stern faces and poor at predicting side faces.

|

|

|

|

|

|
I wrote a new custom dataset to include augmented data. To generate augmented data, I first calculated a rotation matrix to rotate the landmarks, then using "getRotationMatrix2D" and "warpAffine" to get a rotated image. I experimented with rotation around middle point and around the annotated nose tip.
The rotated image and respective points look like these:

|

|

|
To predict full facial keypoints, I trained a neural network with five convolution layers, with parameters (1, 12, 7), (12, 18, 7), (18, 24, 5), (24, 32, 5), (32, 40, 3). Each convolution layer is followed by a ReLu layer and a maxpool layer with parameter 2. Lastly, I used two fully connected layers with parameters (320, 200) and (200, 68*2), where 68*2 indicates we're expecting 136 outputs, which are the x and y coordinates of all points.
The neural network is trained over 25 epochs, with the training and validation loss shown below:
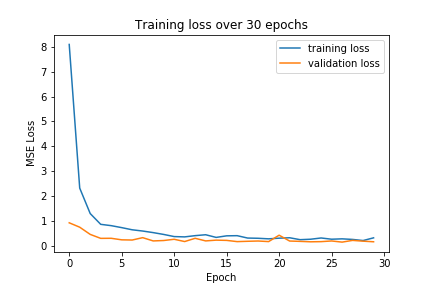
|
Here are some prediction results. The first row are quite successful predictions, while the second row are failure cases. The second row is predicted poorly probably because the people are not centered in the middle, but the model tends to predict more closer to the middle as with the majority of images.

|
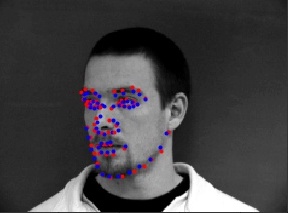
|
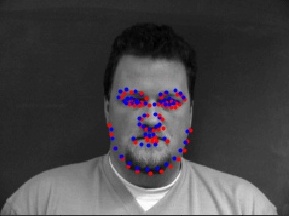
|
|

|
Then, here is a visualization of part of the learned filters of the second convolution layer. The entire set has too many filters. The filters have several dark spots that probably represent detected features.

|
I used the data augmentation technique from part 2 to increment the dataset and trained on a larger dataset. To enforce a standard, I cropped all images to the have the face relatively at the center by the predefined boxes and then resize all images to 224x224.
The architecture I used is mostly the ResNet18 model. The only modifications happen in the first and last layer: The first parameter of the first convolution layer is changed to 1, and the second parameter of the last fully connected layer is changed to 68*2 for the same reason as in previous part. I trained the model on 80% of the augmented dataset and over 25 epochs.
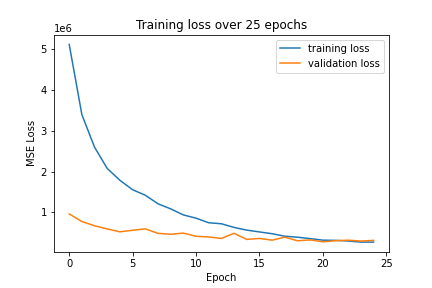
Here, the training and validation MSE losses plotted over the 25 epochs:
|
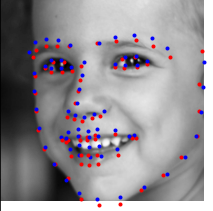
Here are some successful predictions.

|

|
|
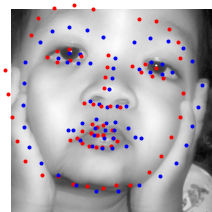
Here are some examples that are not predicted super well.

|
|
Here are some predictions on some examples of the test set. I also submitted the predictions on the test set to Kaggle and the resulting MAE score is: 13.69.
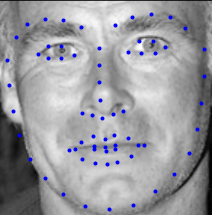
|

|

|
Here are some predictions on some images of my own collection. They are mostly predicted well.

|

|

|