Part 1¶
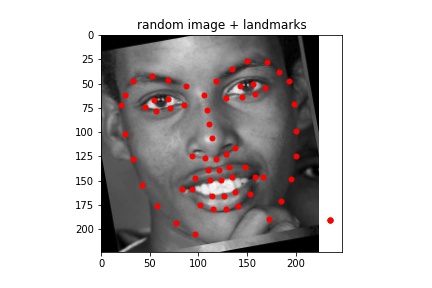
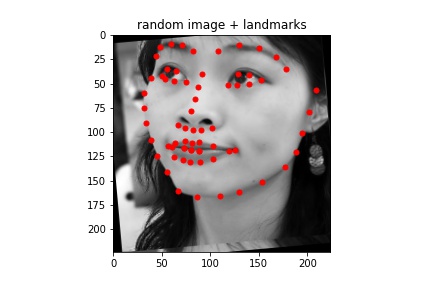
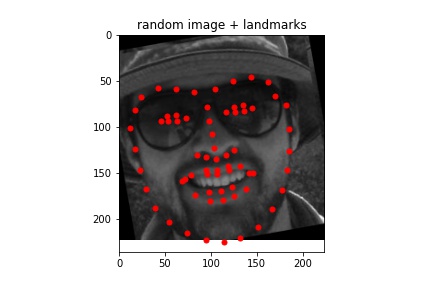
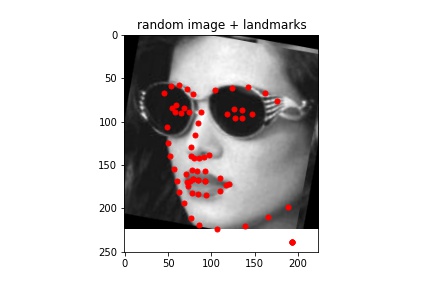
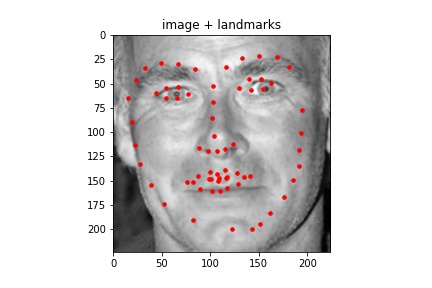
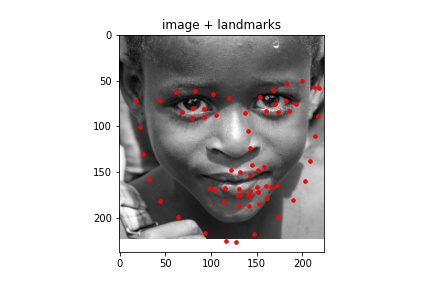
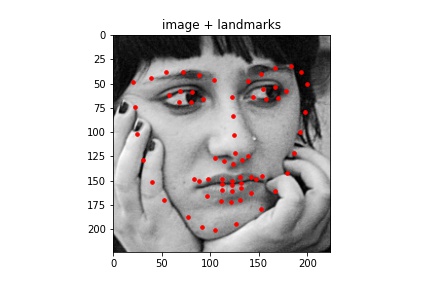
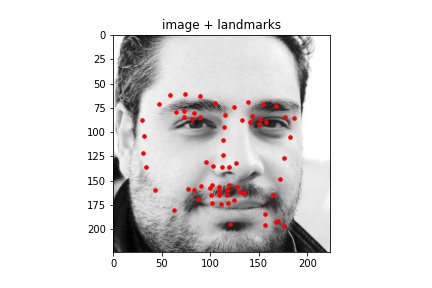
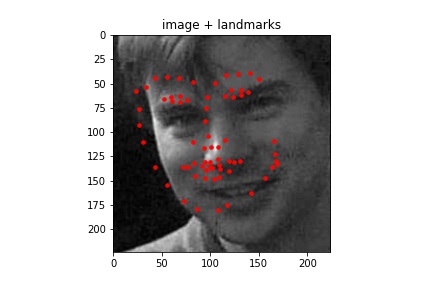
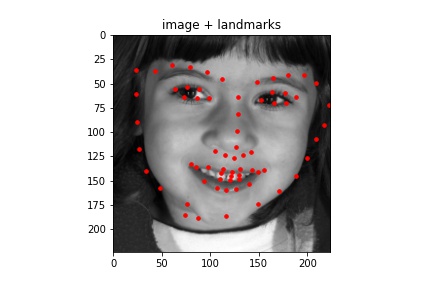
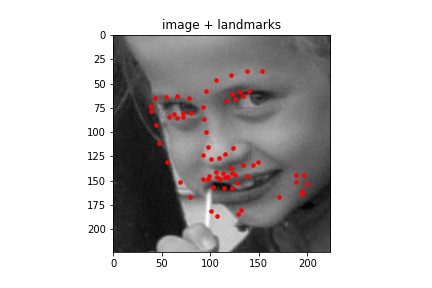
Sampled images:¶




Model¶
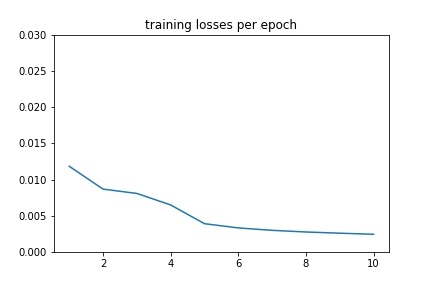
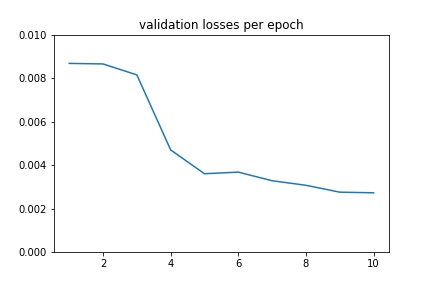
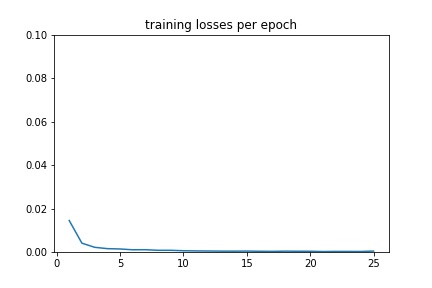
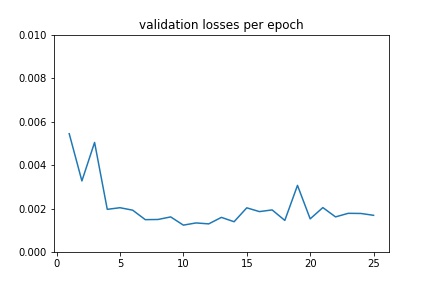
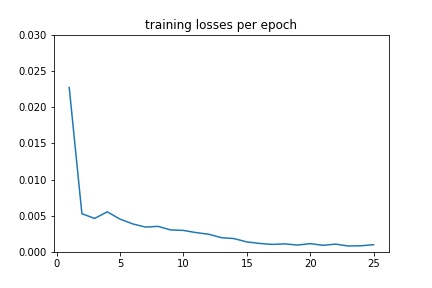
I created 3 transforms NoseOnly, Rescale, and GrayScale, and applied them to the dataset. The model had 4 convolution layers and 2 fully connected layers. In the form of (input_channels, output_channels), the convolution layers were: (1, 12), (12, 16), (16, 20), (20, 24). They all used 3x3 kernel sizes, and were followed by a ReLU and a Maxpool of size 2x2. The fully connected layers were: (72, 500) and (500, 2). The first was followed by a ReLU. For training, the learning rate was 1e-3, the optimizer was Adam, the loss function was MSELoss, and the number of epochs was 25.
Accuracy¶
Training¶
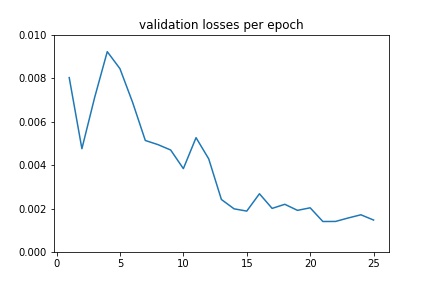
Validation¶
Output¶
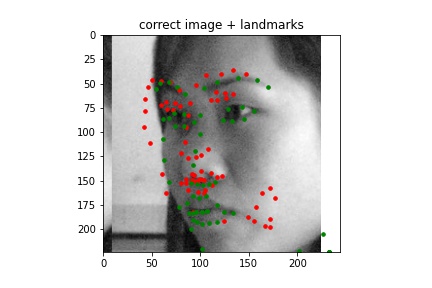
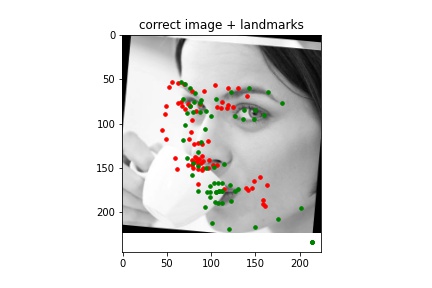
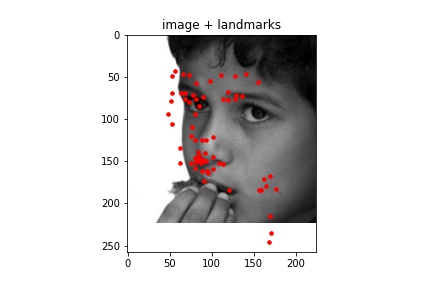
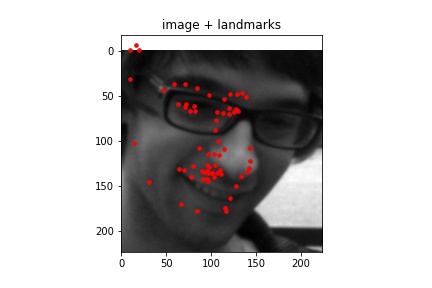
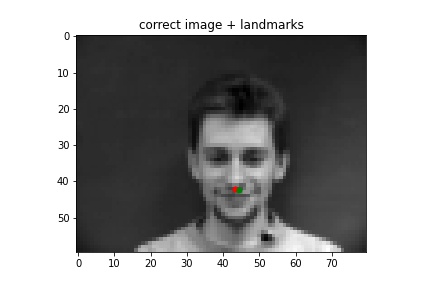
Correct¶

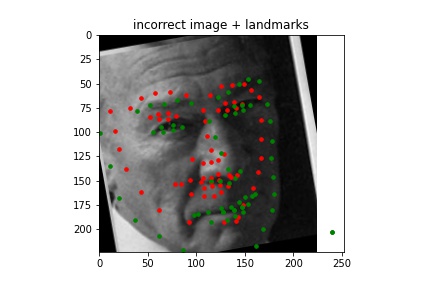
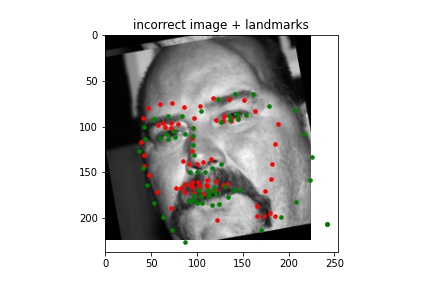
Incorrect¶
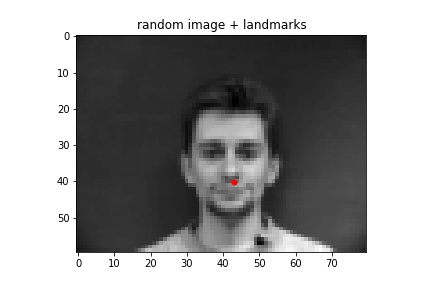
 I think the nose is detected incorrectly because of the head tilt, and because the woman is positioned a lot closer to the camera than the other pictures i.e. her face in this picture takes up a noticeably larger area. The height of her face seems to be about 10 pixels larger, which is significant considering the height of the entire image is 60 pixels.
I think the nose is detected incorrectly because of the head tilt, and because the woman is positioned a lot closer to the camera than the other pictures i.e. her face in this picture takes up a noticeably larger area. The height of her face seems to be about 10 pixels larger, which is significant considering the height of the entire image is 60 pixels.
 Similar to the woman above, I think the nose is detected incorrectly because his face takes up a larger area since he is closer to the camera, less so than the woman but still apparent, and since his face seems longer. There's a lot less space between his chin and the bottom of the image compared to the correct images.
Similar to the woman above, I think the nose is detected incorrectly because his face takes up a larger area since he is closer to the camera, less so than the woman but still apparent, and since his face seems longer. There's a lot less space between his chin and the bottom of the image compared to the correct images.







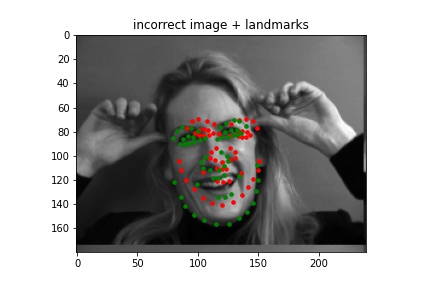 I think the facial points are detected incorrectly primarily because of the head tilt again (all of the points are off, and the face it forms is noticeably straight rather than tilted), but also because I think the model might be thrown off by her smile, mistaking its curve as her chin. The length of her face probably plays a factor as well, as there's more pixels between her smile and her chin than I think there are within other faces.
I think the facial points are detected incorrectly primarily because of the head tilt again (all of the points are off, and the face it forms is noticeably straight rather than tilted), but also because I think the model might be thrown off by her smile, mistaking its curve as her chin. The length of her face probably plays a factor as well, as there's more pixels between her smile and her chin than I think there are within other faces.
 Similar to the woman above, I think the nose is detected incorrectly because of the distance between his smile and his chin, but it's made additionally hard because his chin and his neck are both visible and both similarly curved. The points are labelled technically along the outline of his neck I think, while the model did a good job detecting the faint line of his actual chin. All the other points are detected fine though.
Similar to the woman above, I think the nose is detected incorrectly because of the distance between his smile and his chin, but it's made additionally hard because his chin and his neck are both visible and both similarly curved. The points are labelled technically along the outline of his neck I think, while the model did a good job detecting the faint line of his actual chin. All the other points are detected fine though.