CS194-26 Project 4: Facial Keypoint Detection with Neural Networks
Avik Sethia - Fall 2020
HTML Template Credits- Michael Park
Objective
In our previous projects we had used existing libraries to detect facial keypoints. This project asks us to build our own Convolutional neural net using PyTorch to automate this process given any image.
Nose Tip Detection
As a nice introduction to using neural nets in images we were first asked to detect just the tip of the nose as a keypoint instead of multiple facial keypoints.We were asked to use the imm dataset that consists of 240 images and build our own Dataloader to feed into the neural network.
Below are some results of loading the data using the dataloader we have written:

|

|

|

|
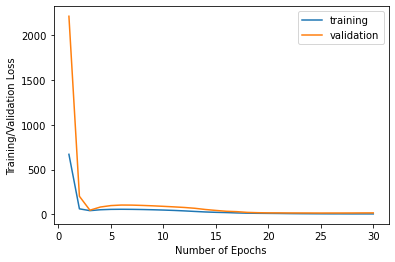
We had to split this dataset into a training and validation/test set with the validation set being 48 images. Below is a plot of the training and validation losses for my neural net against epoch number for my Neural net that consists of 3 convolutional layers and 3 fully connected layers trained over 20 epochs with a learning rate of 0.001 and batch size of 6.
Below are the training and validation losses over epochs:
Training and Validation Losses
|
Below are the results. While most of them are reasonably close to the ground truth- the neural net seems to do really badly on pictures in which the subject is not forward facing. There are also a few forward facing pictures in which the neural net fails.
Good Results

|

|

|

|
Bad Results
|

|

|

|
Full Face Keypoints Detection
For this task, I trained a neural network to predict all 58 keypoints as determined in the ASF files of the
IMM dataset. I followed the same procedure as for the previous task, but I rescaled the images to be
(120px, 160px) for more precise detection. In addition, I implemented data augmentations for this
part: rotation of varying degrees and translation of images. I made sure that I transformed the keypoints
according to the translation of images as well. Below are loaded images with keypoints:

|

|

|

|
I trained a 8-layer neural network with 5 convolutional and 3 ground truth layers. The following is the architecture:
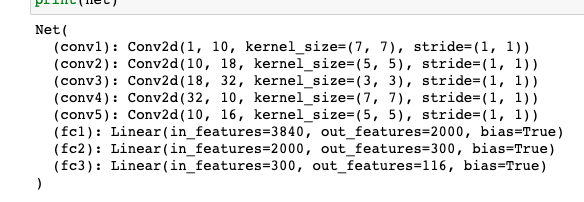
|
Each layer besides the last layer is followed by ReLU and max-pooling. The model was trained over 20 epochs and the Adam optimizer with the learning rate of 0.0025.
Below are the training and validation losses over epochs:
Training and Validation Losses
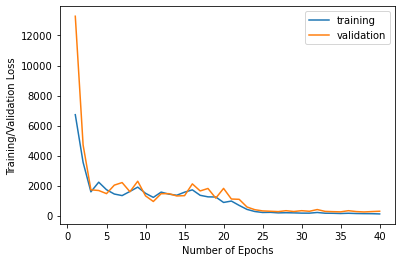
|
Below are the results. Again, while some of them hit the ballpark, the neural net was unable to correctly predict some images, even with data augmentation. This is because of the same reasons as before; there are not much variations in terms of head orientation and lip closure. Because it is more advantageous for the neural network to stick to a general shape that adhere to the majority of the data, it would incorrectly determine images of people facing sideways. Perhaps having more data or other forms of data augmentation would help mitigate the inconsistencies.

|

|

|

|

|

|

|

|
Also, below is a visualization of learned filters of the first layer. Notice that the filters have a dark concentrated spot, which seems to correspond to edges and points that are considered facial features.
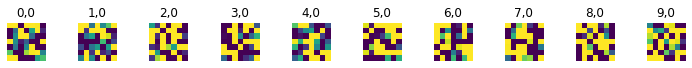
|

|
Train with Large Dataset
For part 3 we were asked to train our neural net on the ibug face in the wild dataset. I used a GPU on colab to do this To increase generizability and performance on test set- I used the same data augmentation techniques we used in part 2. We were given bounding boxes that encompassed the relevant face for each picture- I cropped the image to the co-oridnates of the bounding box and then resized to 244 by 244 pixels to ensure uniformity.
For the neural network, I used the ResNet18 model, a deep neural network designed with 18 layers. I trained the model over 20 epochs using with a learning rate of 0.0015.
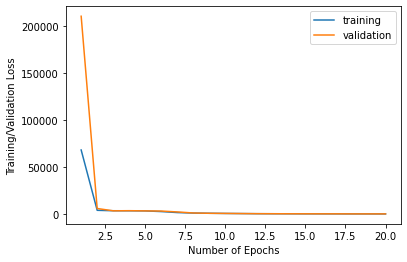
Below are the training and validation losses over epochs:
Training and Validation Losses
|
The Mean Absolute Error of predictions of the test dataset using this model with a learning rate of 0.0015 and a batch size of 6 is 13.91219. , as reported by Kaggle, is I had previously used a batch size of 66 and that seemd to have a much higher MAE. I had also experimented woth learning rates between 0.001 and 0.003 and this seemed to be optimal.Below is the architecture of my ResNet34 net followed by 8 example predictions superimposed on the corresponding images.

|

|

|

|

|

|

|

|
Here is the Architecture of the Resnet 18 model I used
ResNet(
(conv1): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=136, bias=True)
)
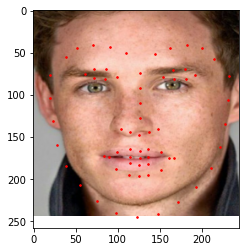
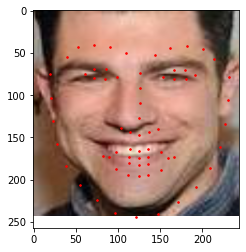
I also tried using the neural net to predict keypoints in pictures of my own collection. I used three pictures of people I admre- my favorite actor(Eddie Redmayne), my favorite sportsperson(Virat Kohli) and my favorite tv show character(Scmhidt from new Girl). The following are the results

|
|
|
Bells and Whistles
I implemented the Anti-aliased max pool from Richard Zhang's work by using model = antialiased_cnns.resnet18() instead of model = models.resnet34() .
There was no tangible difference in performance accuracy unfortunately when I used a learning rate of 0.0001 and a batch size of 6.
Here is the architecture of the model in detail.
ResNet(
(conv1): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): Sequential(
(0): MaxPool2d(kernel_size=2, stride=1, padding=0, dilation=1, ceil_mode=False)
(1): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
))
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): BlurPool(
(pad): ReflectionPad2d([1, 2, 1, 2])
)
(1): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=136, bias=True)
)