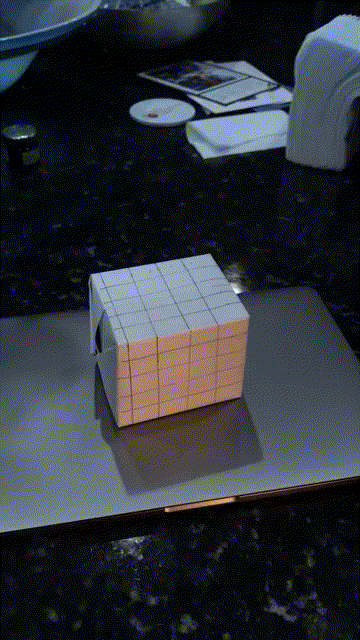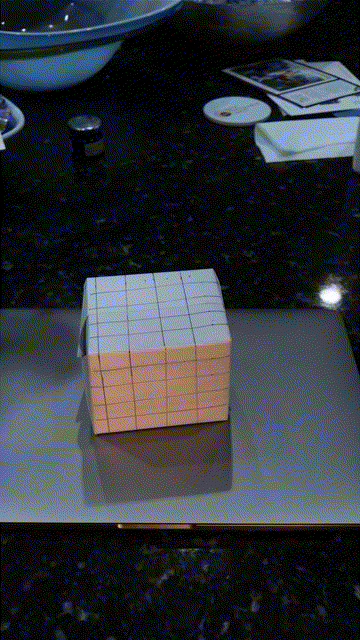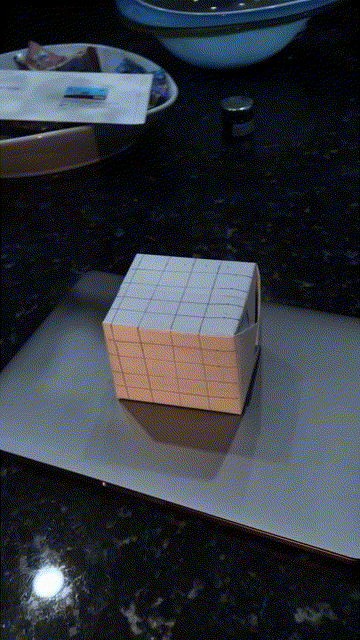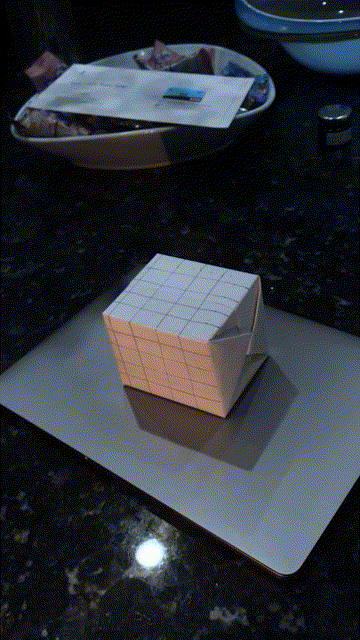

This project involves tracking a set of pre-defined points through a video, and using known corresponding world coordinates to generate a transformation between world coordinates and image locations for every frame of the video.
I defined points for the first frame of the video, and labeled each point with a world coordinate. Instead of manually labeling points for the other frames, I propogated these points using cv2's MedianFlow tracker, as suggested.
| Original | Tracked Points |
|
|
To compute the matrix P describing a particular camera projection matrix for a set of n points, I use least squares to solve the below linear system b = Ax for x, where x is a vector with the 11 free values of P (p_34 is fixed to 1), and b and A are defined as below, with two rows for each point.
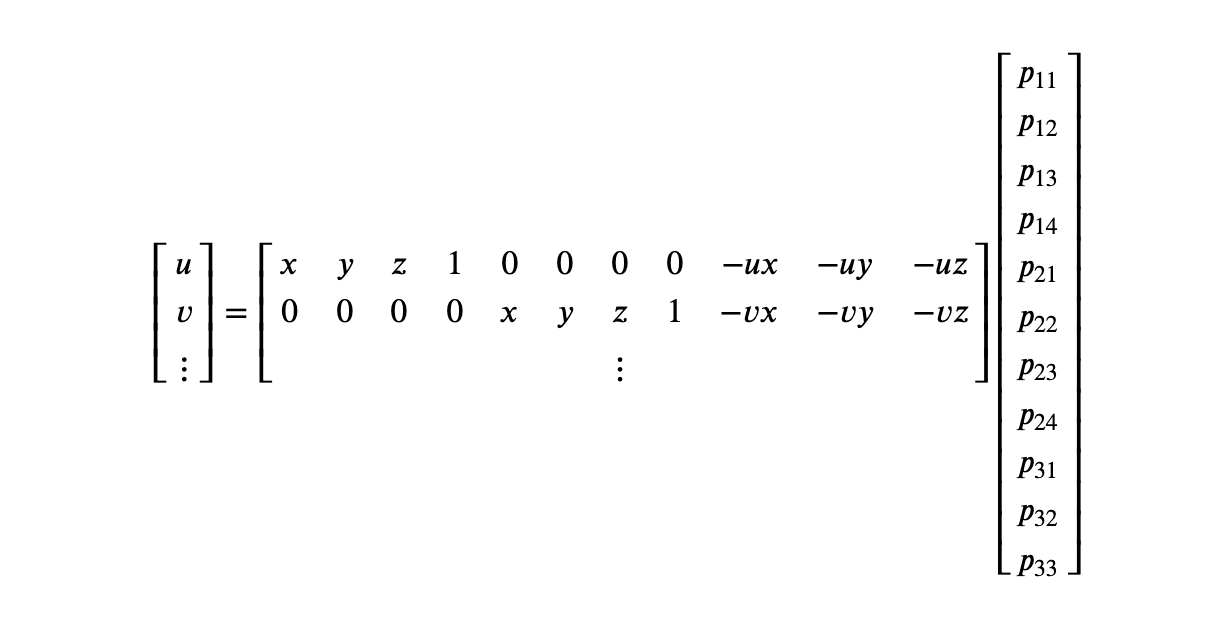
Using the camera projection matrix for each frame, I project a cube on the side of the box throughout the video:

The Stanford Light Field Archive contains multiple images (17x17 grid) per subject taken regularly over a grid. This project explores a couple effects that can be generated with simple operations on this data.
Shifting images based on their position in the grid can allow us to refocus the aggregate image to another depth. Each image is labeled with a (u, v) coordinate, so I use this to determine each image's relative shift. In particular, I first center all the (u, v) in the grid (uv - average uv), then uniformly scale the values to be within the range (-0.9, 0.9). For a given alpha, then, I translate each image by alpha * uv. Varying alpha refocuses the aggregated image:
| Chess | Stanford Bunny |
| alpha: [-10, 30] | alpha: [-40, 25] |
 |
 |
If we want to find the best set of shifts for a given point on the image, then, we simply need to find the alpha that best aligns the pixels near the given point. For my simple implementation, I performed a straighforward linear search through possible alpha values, translating each image on the grid using the selected alpha and extracting the 40x40px patch surrounding our interest point. As a heuristic for overall alignment between the n patches, I simply used sigma^2 / n, where sigma is the first singular value of the nx1600 matrix of flattened patches. The alpha with the highest score for alignment was chosen for the final result.
Below I display the results of this approach for a couple points on the bunny. The selected points are displayed as blue dots:
| Nose (200, 500) | Ear (500, 120) |
| Best alpha: 11 | Best alpha: -16 |
 |
 |
To emulate a shrinking aperture, instead of agreggating all the images in the grid, I only aggregated images whose grid position is within a particular manhattan distance from the grid's center. Below are the results of this approach:
| Chess | Stanford Bunny |
 |
 |