Sensor-Fusion Aided Simulation of Scenarios for Autonomous Vehicles
Romil Bhardwaj, Sukrit Kalra
Introduction
Autonomous vehicles (AVs) will be required to drive
across a plethora of complex scenarios, many of which
present unique challenges to the computational pipeline underlying the vehicle. The ability to develop and test future updates to the pipeline on such scenarios is critical
in ensuring the safety of the pipeline. In order to incorporate production scenarios into the testing cycle, the vendors
need to be able to reconstruct an accurate top-down representation of the environment around the vehicle using data
collected from various sensors attached to the vehicle.
In this work, we present a preliminary approach that utilizes camera images along with point clouds generated by a
LiDAR instance in order to construct a top-down representation of the environment around the vehicle. Furthermore,
we utilize a series of such representations to estimate the
movement of other agents in the environment over time and
reconstruct their trajectories in a simulated environment.
Dataset
We chose the Waymo Open Dataset, which provides images from multiple camera angles along with the LiDAR and GPS information required for the precise simulation of the scenario in the CARLA simulator.
Raw video sample from the waymo dataset.Strawman approach
A naive approach to creating a top-down representation would require points in the image and their real world distances to compute a homography between the camera and the top-down view.
Detecting objectsThe first step involves detecting the objects in the scene. Our straw man approach utilizes off-the-shelf object detection models (eg. Fast-RCNN) to infer a bounding box in the camera frame for the object along with a label such as person or vehicle.
Real world distancesIn order to map these boxes to their appropriate locations in the top-down representation, we require both the width and the height of each object. Similar to previous work, our straw man approach utilizes an average height and width for both persons and vehicles gathered from the National Center for Health Statistics and Consumer Reports respectively. This provides us with the dimensions of the topdown bounding box for each detected object in the scene.
ResultWith the strawman approach, we got this top-down representation:
- The heterogeneity of the obstacles is not represented by the average dimensions chosen by the straw man approach. As a result, the scale of the objects is not maintained.
- The assumption of a straight road to find the distance of the obstacles is limiting and does not work across the different road surfaces experienced during regular driving.
- The per-frame homography computation produces jittery top-down representations across time.
Design
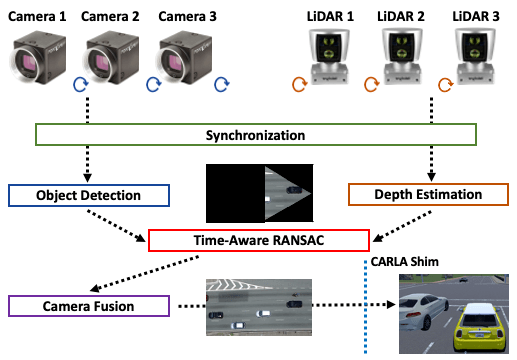
The key observation in our approach is the utilization of the multiple sensors present in an AV. Specifically, we utilize data from the multiple cameras, LiDARs and GPS modules in order to accurately detect the dimensions and distance of the obstacles in the scene. We introduce time-aware RANSAC, which enables the construction of a stable top-down representation of the environment over time. This aids in the reconstruction of the trajectories of the obstacles over time, which is then replayed in the CARLA simulator.
SynchronizationWhile this allows the AV to capture the entire environment around it, these sensors run at different frequencies which complicates the process of fusing data from these sensors in order to build the environment representation. Taking the most recent data from all the sensors at the frequency of the slowest sensor hinders both the accuracy and the latency of the fusion module. For example, running at the frequency of the LiDAR sensor, the latest camera image available might not contain the objects in the same location as they are in the LiDAR reading.
Transformation to a common frame-of-referenceIn our design, we run at the frequency of the camera, and utilize the periodicity of the sensors to wait if the incoming LiDAR reading is closer in time to the camera image than the last available one. In order to ensure the correct fusion of this data, we transform the LiDAR data into the camera frame. To achieve this, we first transform the LiDAR data to the frame of the vehicle based on the location of the LiDAR with respect to the center of the vehicle. This data is further transformed to the camera frame by applying the transform matrix with respect to the front-facing camera.
Hierarchical Time-aware RANSACIn order to calculate the homography that converts the images from the camera frame to the top-down environment representation frame, the straw man approach ran RANSAC across the bounding boxes detected for each frame. This approach minimizes the error across a frame, but leads to a jittery representation over time since each frame is transformed with a different homography. A jittery top-down representation complicates an accurate calculation of the trajectory of each obstacle in the scene.
Our design introduces time-aware RANSAC that seeks to minimize the jitter caused due to the homography transformation across time. Time-aware RANSAC calculates the homography by executing RANSAC across both the obstacle and the time dimension. Specifically, we calculate the homography by choosing a fixed number of points from a single frame. The homography with the minimum error is chosen by executing RANSAC with the homography across all the frames in the dataset. While this approach minimizes the error, it is computationally expensive. As an optimization, our implementation chooses the homography with the minimum error by executing RANSAC across all the obstacles in the scene. However, to prevent jitter, the homography with the minimum error across time is chosen as the single homography for the video stream. In order to calculate this homography, we execute RANSAC across the minimum computed homography of each frame.
Top-down representation with with LIDAR data and Time-aware RANSAC to stabilize homographiesIn order to build a complete representation of the environment around the AV, we utilize images captured from cameras located at different parts of the vehicle. To fuse the images together, we utilize the static locations of the camera with respect to the vehicle to calculate the extrinsic and intrinsic matrices of all the cameras. Further, every image is projected on the frame of the center camera in order to retrieve the complete top-down representation of the scene. This provides us with a panoramic view of the entire area captured by the cameras.
Once the representation of the environment is complete, we use the current location of the vehicle (retrieved from fusing the GPS and IMU sensors) to calculate the location of each obstacle in every frame. These points are then transformed to corresponding waypoints on a CARLA map with a predefined starting point for the AV. We developed a simple waypoint follower control algorithm that generates steering and acceleration commands for the vehicles by applying PID control to the given trajectory. We also match the size and label of the obstacle to the corresponding vehicle in CARLA. However, we are limited by the number of vehicles in CARLA, and cannot ensure that the dimensions of the real vehicles remain unaltered.