Introduction
Recently, NeRFs have shown great promise in generating novel views. However, this quality comes at a high computational cost, making this approach infeasible for time sensitive rendering applications. We approach this problem via methods that learn the rendering process as part of the training regime. At inference time we observe a significant speedup over NeRF as our models avoid computationally intense volume rendering procedures.
Our three approaches
Approach 1: Network Distillation
Results

|

|
We also tried to distill a NeRF that was trained on an unconstrained scene. This means that the views we generated were from any angle, making it imperative for our model to learn a 3D structure of the scene. It did not. Most images were completely black, matching the background of the scene only.
Takeaways
Our naive distillation approach proved quite disappointing. From these experiments, it is clear that enforcing correct 2D views is not enough for our model to learn a clear 3D representation of the scene. The following methods serve to directly force our model to learn a 3D scene. We focus on the unconstrained scene as this requires a stronger 3D understanding.
Approach 2: a Hybrid
For approach 2, we adapt the method used by Niemeyer & Geiger to speed up view synthesis for a single multi-view scene. We train a NeRF to predict an $M$ dimensional feature vector and use the adapted 3D Volume Rendering procedure from Niemeyer & Geiger in order to render a $H x W x M$ image. In practice, we generated a $16 x 16 x 128$ image using 32 samples per ray. This is a much faster procedure due to the smaller output size and reduced number of samples. We then up-sample this image using the up-sampling architecture from UNet. We remove the residual connections from the down-sampling layers and instead just use the last 4 layers for our upsampling procedure. Here are our results.

Clearly, the hybrid model has not learned a coherent representation of the scene, and there are very distinct checkerboard artifacts in the synthesized views.
In order to remove the checkerboard artifacts, we replace the transpose convolutions in our upsampling procedure with bilinear upsampling.

This effectively removed the checkerboard artifacts, and proved more effective in learning a 3D representation of the scene. However, this representation lacks the detail and consistency produced by a normal NeRF, perhaps in part due to the lower sampling rate. Thus, we turn to approach 3.
Approach 3: Shared Backbone
For our final approach, we encode the view direction via a backbone shared between an untrained NeRF and a student model. The student model receives only this encoding as input and produces an image. The NeRF receives both the encoded view direction and a set of rays to sample. Each ray is encoded via the positional encoding described in the original NeRF paper, and concatenated with the view encoding. Both the student and the initially untrained NeRF learn to predict the desired view label. Here is a visualization:
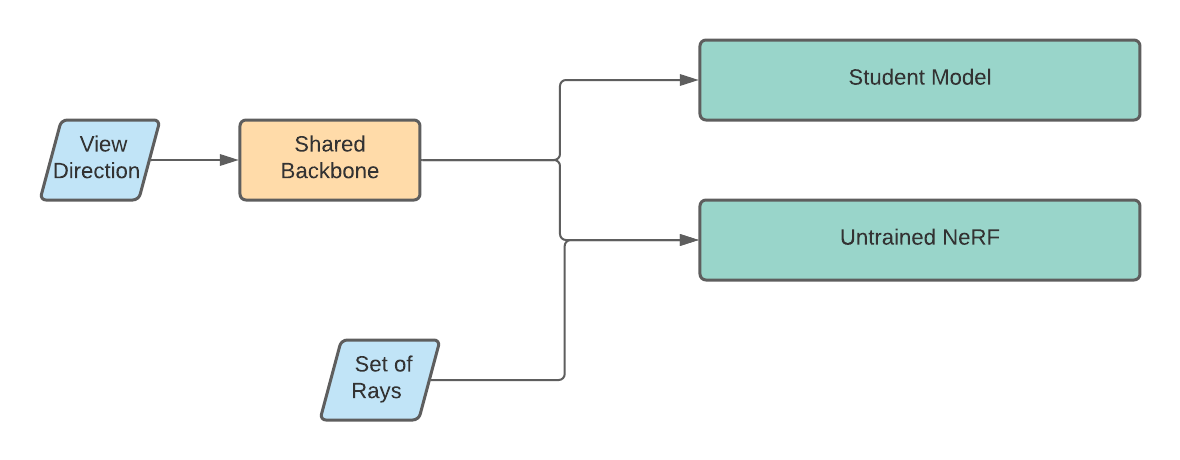

Although our results do not match the quality of NeRF's, we do observe a significant speedup over NeRF. In our experiments, we took 100 forward passes with NeRF and averaged their execution time before doing the same for our model. Our final model sees an $\approx 3000\times$ speedup over NeRF with an average forward pass latency of $0.00332$s compared to NeRF's $9.2246$s.
Limitations
Our model sees significant speedup over NeRF, but has its own limitations as well. First of all, the prediction accuracy of our models are not nearly as high quality as NeRFs. They seem to be blending multiple views, and our model is unable to disentangle which view to present. As well, our model is less configurable than NeRF. Seeing as NeRF fits into the middle of a rendering procedure, the querying done to NeRF is very configurable; one can choose image size, results quality, etc with NeRF while our model outputs one size for all forward passes. Finally, it is unclear if our model retains the high quality 3D information that NeRF gains during training, which makes for water-tight representations that are consistent across views. More evaluation is needed to determine whether or not our model received any of this information in the training process.
Future work
These results are limited but encouraging. For one, the tradeoff in quality is partially mitigated by the impressive speed gains our model makes. We believe that with more resources, a better model could nearly match NeRF's quality while maintaining speed. We were limited by GPU memory on many of our experiments and were forced to shrink our models to fit on GPU; so training a bigger model on a cluster may prove fruitful as it seems our model is underfitting.